
Lena, 28, Wirtschaftsinformatikerin aus Leipzig, hatte das Problem auf dem Handy-Display: eine Seite voller Karteikarten-Apps, drei offene Browser-Tabs mit Statistik-Skripten und einen Kurs, der in sechs Wochen endet. Die Prüfung über Regressionsanalyse war greifbar nah und trotzdem hatte sie das Gefühl, gar nichts zu wissen. Also tat sie das, was heute fast reflexartig passiert: Sie öffnete ChatGPT und tippte: „Erkläre mir Regressionsanalyse.“
Zehn Sekunden später hatte sie eine makellose, vierseitige Erklärung. Klar. Strukturiert. Verständlich. Lena las sie durch, nickte innerlich und schloss das Fenster. Gut, das hab ich jetzt verstanden, dachte sie.
Zwei Wochen später, in der Prüfung: Blackout.
Was war passiert? Lena hatte nicht gelernt. Sie hatte gelesen, was eine KI für sie zusammengedacht hatte. Ihr Gehirn hatte Informationen konsumiert, ohne sie zu verarbeiten – und das Ergebnis war eine perfekte Illusion von Kompetenz bei einer realen Lücke im Wissen.
Die gute Nachricht: Das ist kein Argument gegen KI im Lernen. Es ist ein Argument dafür, sie richtig einzusetzen.
Das Paradox der perfekten Antwort
Large Language Models (LLMs – KI-Sprachmodelle wie ChatGPT, Claude oder Gemini) sind in aller Munde. Millionen Menschen nutzen sie täglich, um Texte zu schreiben, Code zu debuggen, E-Mails zu formulieren. Und immer öfter auch: um zu lernen.
Doch genau hier lauert eine der subtilsten Fallen der digitalen Gegenwart. Denn das, was LLMs am besten können – nämlich sofort, flüssig und erschöpfend zu antworten – ist gleichzeitig das, was Lernen am effektivsten sabotiert.
Die Lernwissenschaft ist da ziemlich eindeutig. Wir lernen nicht, indem wir Informationen konsumieren. Wir lernen, indem wir uns anstrengen. Indem wir abrufen, scheitern, erinnern, verknüpfen. Desirable Difficulties (erwünschte Schwierigkeiten) nennt die Forschung das Prinzip: Lernen, das sich schwerer anfühlt, haftet länger. Ein Text, der uns sofort alles serviert, fühlt sich nach Verständnis an – ist aber oft nur Vertrautheit mit fremdem Denken.
Das klingt paradox: Die mächtigsten Erklärmaschinen der Geschichte können das Lernen verschlechtern. Aber eben nur, wenn man sie falsch einsetzt.
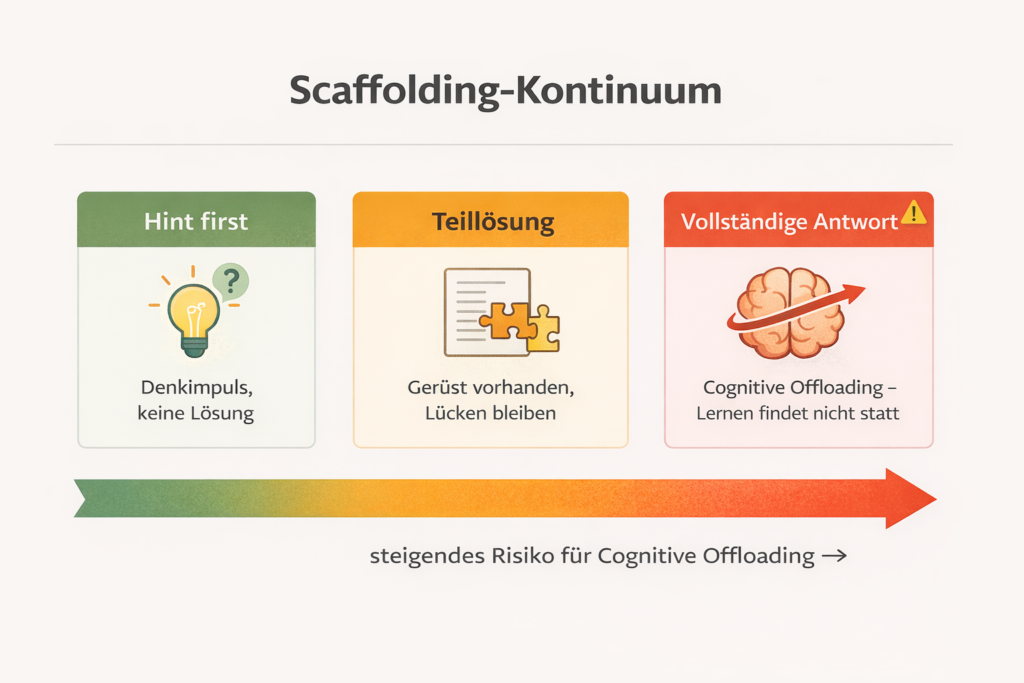
Vier Säulen, die keine KI ersetzen kann
Um zu verstehen, warum LLMs so gefährlich nützlich sind, lohnt ein kurzer Abstecher in die Neurowissenschaft. Stanislas Dehaene, Hirnforscher am Collège de France in Paris, hat vier universelle Mechanismen identifiziert, die er als die Säulen des menschlichen Lernens beschreibt. Sie erklären – direkt und unerbittlich – warum Lenas Strategie scheitern musste.
Aufmerksamkeit ist die erste Säule. Nur was wir wirklich beachten, verarbeitet das Gehirn tief genug, um gespeichert zu werden. Stell dir vor, du liest eine Speisekarte in einer fremden Sprache: Du siehst die Wörter, aber ohne aktive Zuwendung gleiten sie ab. Genau so verhält es sich mit einer KI-Erklärung, durch die man scrollt, ohne wirklich nachzudenken.
Aktives Engagement ist die zweite. Ein passives Gehirn, das Informationen empfängt wie ein Schwamm Wasser, lernt kaum. Lernen passiert im Hypothesenbilden, im Irren, im Korrigieren. Konkret: Wer eine Formel erklärt bekommt, ohne sie je selbst herzuleiten versucht zu haben, hat sie nicht gelernt – er hat sie nur gesehen.
Fehler-Feedback ist die dritte. Das Gehirn lernt durch den Abgleich von Erwartung und Realität. Fehlersignale sind keine Rückschläge – sie sind der eigentliche Motor des Lernens. Wer nie falsch liegt, weil die KI immer rechtzeitig korrigiert, verliert genau diesen Motor.
Konsolidierung ist die vierte. Wissen, das nicht durch Schlaf, Wiederholung und zeitlichen Abstand gefestigt wird, verflüchtigt sich. Das erklärt, warum Last-Minute-ChatGPT-Sessions vor Prüfungen so wenig bringen – selbst wenn man dabei das Gefühl hat, intensiv zu lernen.
Das Problem mit dem klassischen LLM-Einsatz: Er untergräbt mindestens drei dieser vier Säulen gleichzeitig. Nicht weil die KI schlecht ist. Sondern weil sie so gut ist, dass sie uns die Arbeit abnimmt, die unser Gehirn selbst tun müsste.
Ein Satz. Eine andere Lernarchitektur.
Zurück zu Lena. Was hätte sie anders machen können?
Sie hätte den Chatbot nicht fragen sollen: „Erkläre mir Regressionsanalyse.“ Sondern: „Du bist mein sokratischer Tutor. Ich lerne gerade Regressionsanalyse. Gib mir niemals die Lösung direkt, stelle mir stattdessen eine Frage, die herausfindet, wie weit ich schon bin.“
Das ist ein kleiner Unterschied im Prompt (der Eingabetext, mit dem man einer KI eine Aufgabe beschreibt). Aber er verändert die gesamte Lernarchitektur.
Anstatt eine fertige Erklärung zu empfangen, hätte Lena eine Frage bekommen. Vielleicht: „Was glaubst du, passiert mit der Regressionsgerade, wenn du einen Ausreißer in deine Daten hinzufügst?“ Sie hätte nachgedacht. Geraten. Vielleicht falsch gelegen. Und genau dadurch wäre Wissen entstanden kein Scheinwissen, sondern echtes.
Retrieval Practice (aktives Abrufen aus dem Gedächtnis) nennen Lernforscher wie Peter C. Brown, Henry Roediger und Mark McDaniel dieses Prinzip: Das Abrufen von Wissen stärkt neuronale Pfade weit mehr als passives Aufnehmen. Ein LLM, das uns zwingt, zuerst selbst zu antworten, bevor es kommentiert, ist ein mächtiges Werkzeug für genau diesen Mechanismus.
Und das ist nur eine von vielen möglichen Rollen, die ein Sprachmodell im Lernprozess spielen kann.
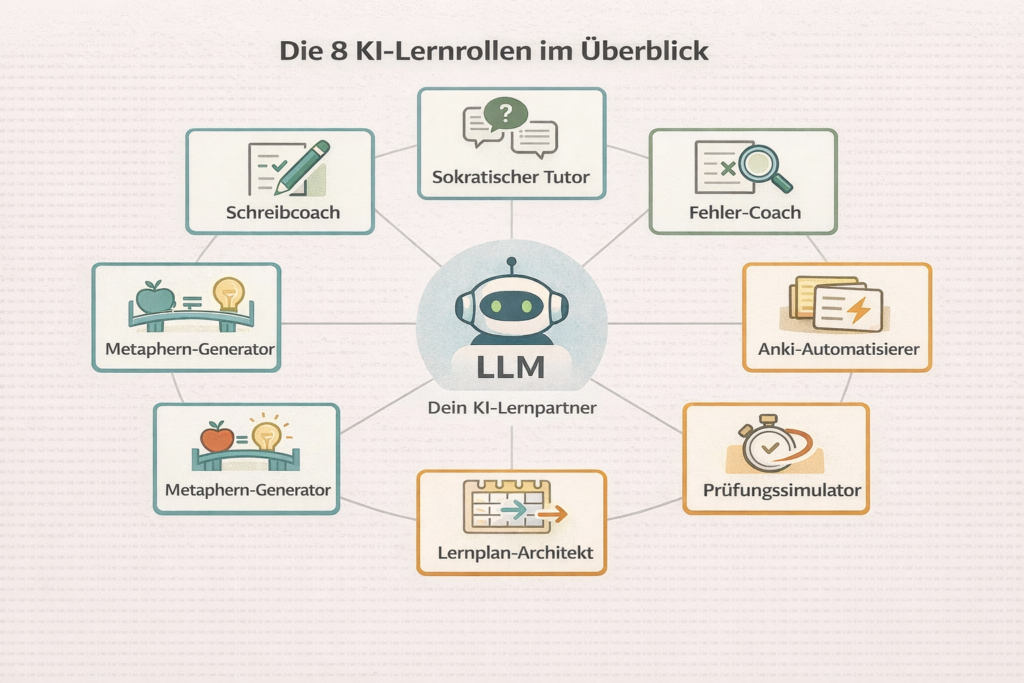
Acht Rollen, eine Maschine und ein typischer Fehler pro Rolle
Die Forschung rund um KI-gestütztes Lernen hat sich in den letzten drei Jahren rasant entwickelt. Was sich dabei herauskristallisiert hat: LLMs sind keine monolithischen Erklärmaschinen. Sie können acht völlig verschiedene Rollen einnehmen, je nach Prompt und Lernziel. Zu jeder Rolle gehört aber auch ein typischer Fehler, der den Effekt zunichte macht.
Die Rolle 1: Der Sokratische Tutor
Stell dir vor: Du fragst die KI, wie Regressionsanalyse funktioniert. Statt einer Erklärung kommt eine Gegenfrage zurück – „Was glaubst du, was passiert, wenn du einen Ausreißer in deine Daten einfügst?“ Du denkst kurz nach. Tippst eine Antwort. Die KI antwortet wieder mit einer Frage. Irgendwann, nach vier oder fünf Runden, merkst du: Du hast das Konzept nicht erklärt bekommen. Du hast es selbst erarbeitet. Genau darin liegt der Lerngewinn.
Was er tut: Gibt keine Antworten. Er stellt Fragen. Er führt den Lernenden durch Rückfragen zur Erkenntnis – wie Sokrates mit seinen Schülern in Athen, nur mit unbegrenzter Geduld und rund um die Uhr verfügbar.
Prompt: „Du bist mein sokratischer Tutor für das Thema Regressionsanalyse. Gib mir niemals Lösungen direkt. Stelle mir stattdessen Fragen, die herausfinden, was ich noch nicht verstanden habe.“
Use Case: Prüfungsvorbereitung, Konzeptverständnis in MINT-Fächern, Vorbereitung auf mündliche Prüfungen.
Typischer Fehler: Die Frustration, keine schnelle Antwort zu bekommen, verleitet dazu, den Prompt einfach neu zu formulieren: „Erkläre es mir doch einfach.“ Dann ist der sokratische Modus gebrochen. Besser: Frustration aushalten. Sie ist das Signal, dass gerade gelernt wird.
Die Rolle 2: Der Fehler-Coach
Was er tut: Analysiert nicht die Lösung, sondern den Fehler. Wer eine falsche Antwort einreicht und die KI bittet, den Denkfehler zu benennen – nicht die richtige Lösung –, trainiert Metakognition (das Denken über das eigene Denken). Und das ist einer der stärksten Prädiktoren für akademischen Erfolg überhaupt.
Prompt: „Hier ist meine Lösung für diese Statistikaufgabe. Ich habe das falsche Ergebnis. Erkläre mir nicht den richtigen Weg – finde stattdessen den Fehler in meiner Logik und gib mir nur einen Hinweis, keine Lösung.“
Use Case: Mathematik, Programmierung, Textanalyse – überall, wo Denkwege rekonstruierbar sind.
Typischer Fehler: Die KI gibt einen Hinweis, der Lernende versteht ihn nicht sofort und fragt nach: „Kannst du das genauer erklären?“ – woraufhin die KI die vollständige Lösung liefert. Gegenmaßnahme: Den Prompt explizit sperren: „Gib mir auf keinen Fall die Lösung, egal wie ich nachfrage.“
Die Rolle 3: Der Anki-Automatisierer
Was er tut: Spaced Repetition (zeitlich verteiltes Wiederholen) ist wissenschaftlich einer der wirksamsten Lernmechanismen überhaupt. Das Problem: Gute Lernkarten zu erstellen kostet Zeit. Ein LLM generiert aus einem beliebigen Text in Sekunden dutzende Frage-Antwort-Paare für Anki (eine populäre Karteikarten-App, die automatisch berechnet, wann man eine Karte wieder sehen sollte).
Prompt: „Lies diesen Text und erstelle 10 Anki-Karten im Format Frage; Antwort. Die Fragen sollen aktives Erinnern fordern – keine Ja/Nein-Fragen, sondern offene Fragen, die Verständnis prüfen.“
Use Case: Vokabeln, Definitionen, Konzepte in allen Fächern.
Typischer Fehler: Die generierten Karten werden nie wirklich benutzt. Das Erstellen fühlt sich wie Lernen an – ist es aber nicht. Die Karten müssen täglich abgerufen werden, sonst ist die ganze Übung wertlos.
Die Rolle 4: Der Prüfungssimulator
Was er tut: Simuliert realistische Prüfungssituationen – inklusive Zeitdruck, kritischen Nachfragen und abschließendem Feedback.
Prompt: „Ich bereite mich auf eine mündliche Prüfung in Statistik vor. Prüfe mich 15 Minuten lang. Sei streng, stelle Nachfragen bei unvollständigen Antworten und gib mir am Ende ein detailliertes Feedback zu meinen Stärken und Schwächen.“
Use Case: Mündliche Prüfungen, Präsentationen, Bewerbungsgespräche.
Typischer Fehler: Die Simulation läuft im Komfort-Modus – der Lernende pausiert, googelt zwischendurch, lässt sich Zeit. Das trainiert nicht das Abrufen unter Druck, sondern das Nachschauen unter Druck. Besser: Zeitlimit setzen, kein zweites Tab öffnen.
Die Rolle 5: Der Lernplan-Architekt
Was er tut: Interleaving – also das bewusste Mischen verschiedener Themen innerhalb einer Lerneinheit – ist eines der am stärksten belegten Lernprinzipien. Konkret bedeutet das: Nicht drei Tage lang nur Statistik lernen, dann drei Tage nur Programmierung. Sondern täglich wechseln: Statistik, Programmierung, Statistik. Das fühlt sich ineffizienter an – und ist es kurzfristig auch. Langfristig führt es aber dazu, dass das Gehirn lernt, welche Methode für welche Aufgabe passt. Ein LLM kann diese Struktur planen.
Prompt: „Ich muss in drei Monaten dieses Modul bestehen. Ich habe fünf Stunden pro Woche. Erstelle mir einen Lernplan, der Interleaving und zeitlich verteiltes Wiederholen berücksichtigt – erkläre dabei kurz, warum die Reihenfolge so gewählt wurde.“
Use Case: Semestervorbereitung, Sprachlernen, Zertifizierungen.
Typischer Fehler: Der Plan wird erstellt, einmal angeschaut und nie mehr geöffnet. Ein Lernplan ohne Tracking ist ein Wunschzettel. Lösung: Den Plan in ein echtes Kalender-System übertragen.
Die Rolle 6: Der Reflexionspartner
Was er tut: Am Ende eines Lerntages stellt er drei bis fünf Fragen, die zur Metakognition zwingen – zum Nachdenken über das eigene Lernen, nicht nur über den Inhalt.
Prompt: „Ich habe heute drei Stunden Statistik gelernt. Stelle mir vier Fragen, die mich dazu bringen, über meine Konzentration, mein Verständnis und meine Lücken nachzudenken. Gib keine Antworten – nur Fragen.“
Use Case: Tagesabschluss, Wochenreview, Semesterplanung.
Typischer Fehler: Die Reflexionsfragen werden oberflächlich beantwortet – „War okay“, „Hab alles verstanden“ – ohne wirklich innezuhalten. Dann ist die Übung wertlos. Besser: Antworten aufschreiben, nicht nur denken.
Die Rolle 7: Der Metaphern-Generator
Was er tut: Chunking – das Zusammenfassen von Informationen zu bedeutungsvollen Einheiten – funktioniert besonders gut über Analogien. LLMs sind darin überraschend stark.
Prompt: „Erkläre mir das Konzept der objektorientierten Programmierung anhand einer Analogie zu einem Restaurant. Bleibe konsequent bei der Analogie und zeige auch deren Grenzen auf.“
Use Case: Abstrakte Konzepte in MINT, Wirtschaft, Philosophie.
Typischer Fehler: Die Analogie wird als vollständige Erklärung genommen. Jede Analogie hinkt irgendwo – und wo sie hinkt, entstehen Fehlvorstellungen. Daher immer nach den Grenzen der Analogie fragen und danach mit dem echten Konzept abgleichen.
Die Rolle 8: Der Schreibcoach
Was er tut: Analysiert nicht den Text, sondern die Argumentationsstruktur. Wer die KI bittet, nicht den Text zu verbessern, sondern die logischen Lücken zu benennen, trainiert analytisches Denken statt es zu delegieren.
Prompt: „Hier ist mein Entwurf für die Einleitung meiner Hausarbeit. Verbessere den Text nicht. Analysiere stattdessen die logische Struktur: Wo ist die These unklar? Wo fehlen Belege? Wo ist die Argumentation zirkulär?“
Use Case: Wissenschaftliche Arbeiten, Blogposts, Berichte, Bewerbungsschreiben.
Typischer Fehler: Die KI gibt Verbesserungsvorschläge – der Lernende übernimmt sie, ohne sie zu verstehen. Ergebnis: besserer Text, kein besseres Denken. Besser: Erst die Kritik verstehen, dann selbst umformulieren.
Gerade hier zeigt sich am deutlichsten, worum es eigentlich geht: Wer die KI bittet, seinen Text zu verbessern, delegiert Urteilsvermögen. Wer sie bittet, seine Argumentation zu hinterfragen, schärft es.
Was sagt die Forschung wirklich?
So überzeugend die Theorie auch ist – wie sieht die Empirie aus?
Eine Analyse von Zhang und Kollegen aus dem Jahr 2025, die 22 Einzelstudien zusammenfasste, zeigte einen moderaten positiven Effekt generativer KI auf Mathematiklernleistungen – in der Größenordnung von etwa einem halben Schuljahr zusätzlichem Lernfortschritt im Vergleich zu Kontrollgruppen ohne KI-Unterstützung. Eine breitere Auswertung von 34 Studien durch Forschende der Universität Wuhan zeigte ähnliche Muster über verschiedene kognitive Bereiche hinweg, wobei der Effekt bei aktivem, kreativem Einsatz der KI am stärksten ausfiel.
Aber, und das ist entscheidend, die Effekte sind hochgradig heterogen. Sie hängen ab von der Dauer der Intervention, dem Fach, dem Lernniveau und vor allem: dem Instruktionsmodus. Kurz gesagt: Wie die KI eingesetzt wird, macht den Unterschied. Nicht welche.
Das unsichtbare Phänomen: Performance-Learning Dissociation
Besonders aufschlussreich ist ein Effekt, den Forscher Performance-Learning Dissociation nennen. Übersetzt: Leistungs-Lern-Entkopplung. Das klingt abstrakt – ist aber erschreckend konkret.
Stell dir zwei Gruppen vor, die dieselbe Programmieraufgabe lösen. Gruppe A darf ChatGPT frei nutzen. Gruppe B bekommt nur strukturierte Hinweise. Nach der Aufgabe zeigt Gruppe A deutlich bessere Ergebnisse: Der Code läuft, die Abgabe ist sauber. Eine Woche später schreibt dieselbe Gruppe eine Klausur zu denselben Konzepten – ohne KI. Gruppe A schneidet jetzt schlechter ab als Gruppe B.
| Mit KI (Aufgabe) | Ohne KI (Klausur) | |
|---|---|---|
| Gruppe A (freie KI-Nutzung) | ✅ Sehr gut | ❌ Unterdurchschnittlich |
| Gruppe B (strukturierte Hinweise) | ⚠️ Mittel | ✅ Gut |
Was passiert hier? Gruppe A hat geleistet, aber nicht gelernt. Die KI hat die kognitiven Prozesse übernommen – Fehlersuche, Strukturierung, Synthese –, die genau jene neuronalen Pfade aufgebaut hätten, die Gruppe A in der Klausur gebraucht hätte. Die Punkte auf der Abgabe waren real. Das Wissen dahinter war es nicht.
Das ist keine Kritik an der KI. Es ist eine Kritik am unreflektierten Einsatz – und ein starkes Argument dafür, dass Bildungsinstitutionen nicht nur ob KI genutzt wird regulieren müssen, sondern wie.

Die Risiken – ehrlich betrachtet
Die Risiken des KI-gestützten Lernens sind real, und es wäre unredlich, sie kleinzureden.
Cognitive Offloading – das Auslagern kognitiver Arbeit an externe Systeme – ist nicht per se schlecht. Wir nutzen Taschenrechner für Rechenarbeit und Navigations-Apps für Routen, ohne dass wir dafür geächtet werden. Das Problem entsteht bei einer ganz bestimmten Kategorie von Aufgaben: jenen, die wir eigentlich verstehen müssen, nicht nur lösen. Ein Taschenrechner, der die Division übernimmt, raubt uns kein Konzeptverständnis. Eine KI, die die Argumentation einer Hausarbeit übernimmt, schon.
Die Unterscheidung ist einfach: Sinnvolles Offloading betrifft Rechenarbeit, Formatierung, Recherche von Fakten. Problematisches Offloading betrifft Konzeptverständnis, kritisches Denken, Synthese.
Halluzinationen sind ein technisches Problem mit echten Konsequenzen: LLMs erzeugen Falschinformationen mit derselben Überzeugung – und derselben sprachlichen Eleganz –, mit der sie korrekte liefern. Fachleute nennen das confidence without calibration (Überzeugung ohne Kalibrierung): Das Modell weiß nicht, was es nicht weiß. Es gibt keine epistemische Transparenz (kein Bewusstsein über die eigenen Wissensgrenzen). In einem Medizinstudium oder einem Rechtsexamen kann eine falsch generierte Prüfungsfrage gefährliches Halbwissen erzeugen. Critical Thinking ist kein optionaler Bonus. Es ist Pflicht.
Der Equity Gap ist vielleicht das unangenehmste Problem: Studierende mit starken Metakognitionsfähigkeiten nutzen KI als Beschleuniger. Schwächere Lernende nutzen sie oft als Krücke. Die Schere wächst – ausgerechnet mit einer Technologie, die Bildung eigentlich demokratisieren sollte.
Institutionelle Reaktionen sind im Gange: Oxford und Cambridge erlauben KI-Nutzung unter strikter Transparenzpflicht. Die UNESCO fordert ein Mindestalter von 13 Jahren für Bildungs-KIs und staatliche Validierung der eingesetzten Systeme. Weltweit bewegen sich Universitäten weg von pauschalen Verboten – hin zu AI Literacy-Frameworks, die Studierenden beibringen sollen, wie man KI klug nutzt statt blind.
Nicht das Werkzeug entscheidet. Der Mensch dahinter.
Barbara Oakley, Lernwissenschaftlerin und Autorin von Learning How to Learn – einem der meistbelegten Online-Kurse der Welt –, beschreibt einen Mechanismus, den sie Focused Mode und Diffuse Mode nennt: Das Gehirn lernt am besten im Wechsel zwischen konzentrierter Arbeit und entspanntem Nachdenken. In den Diffuse-Phasen – unter der Dusche, beim Spaziergang, im Halbschlaf – verknüpft das Gehirn unbewusst, was es vorher gelernt hat. Wer ununterbrochen in KI-Dialogen versinkt, verliert diese Pausen. Das Lernen wird intensiver – und gleichzeitig oberflächlicher.
James Clear hat in Atomic Habits (Atomare Gewohnheiten) etwas beschrieben, das im Lernkontext oft übersehen wird: Nicht Ziele entscheiden über langfristigen Erfolg, sondern Systeme. Wer lernen will, braucht keine bessere Motivation – sondern eine Umgebung, die Lernen wahrscheinlicher macht. LLMs können Teil dieses Systems sein: als täglicher Reflexionspartner, als Lernplan-Architekt, als Prokrastinations-Coach. Nicht als Ersatz für Denkarbeit, sondern als Architektur drumherum.
Scott Young, Autor von Ultralearning, bringt es auf den Punkt: Die wirksamsten Lernmethoden sind unbequem. Direkt üben, gezielt an Schwächen arbeiten, schwierige Feedback-Schleifen durchlaufen. Ein LLM, das uns von dieser Unbequemlichkeit befreit, ist kein Lernpartner – es ist ein Fluchtweg.
Die Forschung bestätigt das. Ein Team um Kasneci und Kollegen analysierte 2023 systematisch, welche Faktoren KI-gestütztes Lernen wirksam machen: Es war nie das Modell. Es war immer das Design der Interaktion.
Die Frage, die bleibt
Die Frage, die Lernwissenschaftler und KI-Forscher gleichermaßen umtreibt, lautet nicht: „Ist KI gut oder schlecht für das Lernen?“ Diese Frage ist so hilfreich wie: „Ist Feuer gut oder schlecht?“
Die eigentliche Frage ist subtiler. Wir wissen inzwischen, dass die Wirksamkeit von LLMs im Lernen weniger vom Modell abhängt als vom Design der Interaktion. Ein schwächeres Modell mit kluger Prompt-Strategie schlägt ein hochentwickeltes Modell im reinen Answer-giving-Modus. Das bedeutet: Die Kompetenz, die zählt, ist nicht die KI – sondern die Fähigkeit des Menschen, sie richtig einzusetzen.
Und das ist gleichzeitig die gute und die unbequeme Nachricht. Denn diese Fähigkeit ist nicht angeboren. Sie muss – wie alles Wertvolle – erlernt werden.
Was mich dabei am meisten beschäftigt: Wir bauen gerade Bildungssysteme für eine Welt, in der KI überall ist. Aber die Kompetenz, KI lernwirksam einzusetzen, wird an den wenigsten Schulen unterrichtet. Stattdessen schwanken die Institutionen zwischen Verbot und Kapitulation – und überlassen die eigentliche Frage dem Zufall.
Lena, die Wirtschaftsinformatikerin aus Leipzig, hat das übrigens selbst herausgefunden. Beim zweiten Versuch hat sie den Chatbot als ihren persönlichen Prüfer eingesetzt – keine fertigen Erklärungen mehr, nur Fragen, Fehleranalyse, erzwungener Abruf. Die Prüfung lief besser. Und zum ersten Mal hatte sie das Gefühl, die Regressionsanalyse wirklich zu können – nicht weil sie eine gute Zusammenfassung gelesen hat, sondern weil sie sich durch das Wissen hindurchgekämpft hat.
Der Unterschied war nicht die KI. Der Unterschied war sie selbst.
Bleibt die Frage, die mich nach all der Recherche noch beschäftigt: Wenn wir wissen, wie man KI lernwirksam einsetzt – warum bringen wir es dann nicht jedem Schüler bei, bevor er das erste Mal ChatGPT öffnet?
Dieser Artikel basiert auf aktueller Lernforschung, darunter Studien zu GenAI im Bildungsbereich (Zhang et al. 2025; Kasneci et al. 2023), den Arbeiten von Stanislas Dehaene (How We Learn), Peter C. Brown, Henry Roediger und Mark McDaniel (Make It Stick), Barbara Oakley (Learning How to Learn), Scott Young (Ultralearning) und James Clear (Atomic Habits) sowie der UNESCO-Guidance für generative KI in der Bildung (2024).