
Lena, 28, a business informatics student from Leipzig, was staring at her phone screen with a problem: a page full of flashcard apps, three open browser tabs with statistics scripts, and a course ending in six weeks. The exam on regression analysis was within reach — and yet she felt like she knew nothing. So she did what almost everyone does reflexively these days: she opened ChatGPT and typed: “Explain regression analysis to me.”
Ten seconds later, she had a flawless, four-page explanation. Clear. Structured. Comprehensible. Lena read through it, nodded inwardly, and closed the window. Okay, I’ve got that now, she thought.
Two weeks later, in the exam: complete blank.
What had happened? Lena hadn’t learned. She had read what an AI had thought through for her. Her brain had consumed information without processing it — and the result was a perfect illusion of competence masking a real gap in knowledge.
The good news: this is not an argument against AI in learning. It’s an argument for using it correctly.
The Paradox of the Perfect Answer
Large Language Models (LLMs — AI language models such as ChatGPT, Claude, or Gemini) are on everyone’s lips. Millions of people use them daily to write texts, debug code, and compose emails. And increasingly: to learn.
Yet this is precisely where one of the subtlest traps of the digital age lurks. Because what LLMs do best — answering immediately, fluently, and exhaustively — is simultaneously what sabotages learning most effectively.
The learning sciences are quite clear on this. We don’t learn by consuming information. We learn by making an effort — by retrieving, failing, remembering, connecting. Researchers call this principle Desirable Difficulties: learning that feels harder sticks longer. A text that serves up everything instantly feels like understanding — but is often merely familiarity with someone else’s thinking.
That sounds paradoxical: the most powerful explanation machines in history can actually make learning worse. But only when used incorrectly.
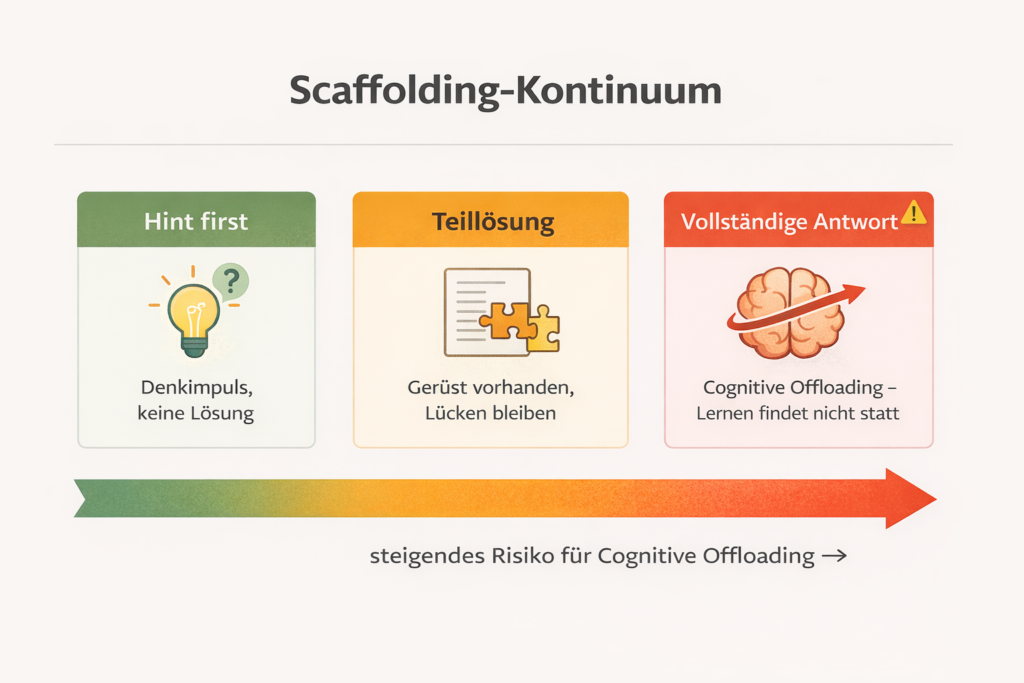
Four Pillars No AI Can Replace
To understand why LLMs are so dangerously useful, a brief detour into neuroscience is worthwhile. Stanislas Dehaene, neuroscientist at the Collège de France in Paris, has identified four universal mechanisms that he describes as the pillars of human learning. They explain — directly and unequivocally — why Lena’s strategy had to fail.
Attention is the first pillar. Only what we truly pay attention to is processed deeply enough by the brain to be stored. Imagine reading a menu in a foreign language: you see the words, but without active engagement they slide off. The same is true of an AI explanation you scroll through without really thinking.
Active engagement is the second. A passive brain that receives information like a sponge absorbs water barely learns at all. Learning happens through forming hypotheses, making mistakes, and correcting them. Concretely: someone who receives an explanation of a formula without ever having tried to derive it themselves hasn’t learned it — they’ve only seen it.
Error feedback is the third. The brain learns through the comparison of expectation and reality. Error signals are not setbacks — they are the actual engine of learning. Whoever is never wrong because the AI always corrects in time loses precisely that engine.
Consolidation is the fourth. Knowledge that isn’t reinforced through sleep, repetition, and time intervals fades away. This explains why last-minute ChatGPT sessions before exams yield so little — even when they feel like intense studying.
The problem with conventional LLM use: it undermines at least three of these four pillars simultaneously. Not because the AI is poor. But because it is so good that it takes over the work our brains need to do themselves.
One Sentence. A Different Learning Architecture.
Back to Lena. What could she have done differently? She shouldn’t have asked the chatbot: “Explain regression analysis to me.” Instead: “You are my Socratic tutor. I’m currently learning regression analysis. Never give me the solution directly — instead, ask me a question that finds out how far along I already am.”
That is a small difference in the prompt (the input text used to give an AI a task). But it changes the entire learning architecture.
Instead of receiving a finished explanation, Lena would have gotten a question. Perhaps: “What do you think happens to the regression line when you add an outlier to your data?” She would have thought about it. Guessed. Perhaps been wrong. And that is precisely how real knowledge would have formed — not pseudo-knowledge, but the genuine article.
Retrieval Practice (actively recalling knowledge from memory) is what learning researchers such as Peter C. Brown, Henry Roediger, and Mark McDaniel call this principle: retrieving knowledge strengthens neural pathways far more than passive absorption. An LLM that forces us to answer first before commenting is a powerful tool for precisely this mechanism.
And this is just one of many possible roles a language model can play in the learning process.
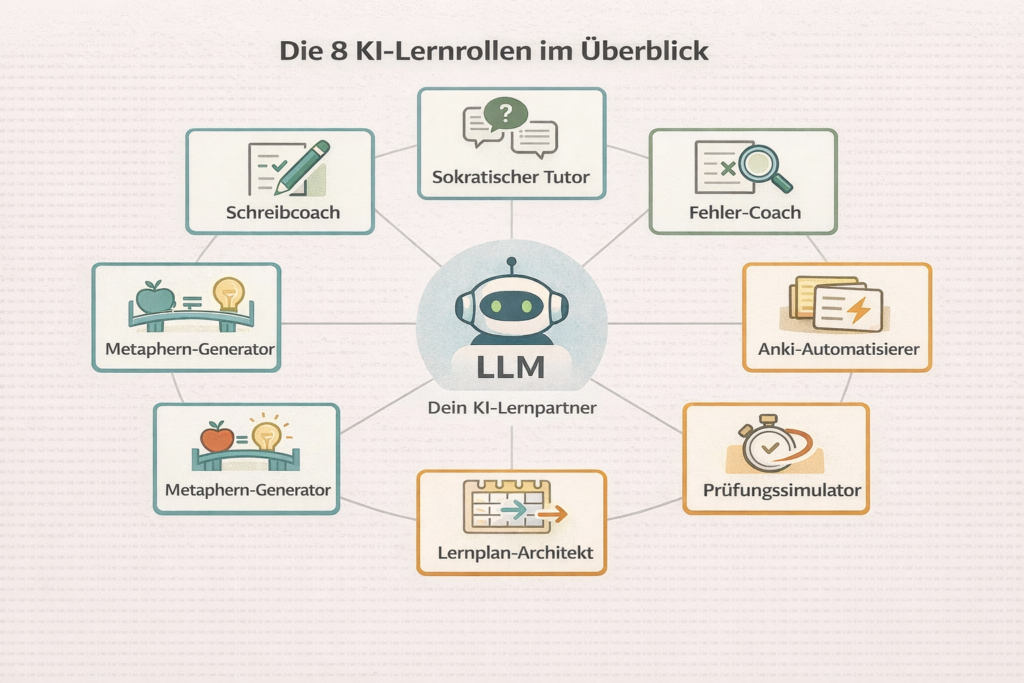
Eight Roles, One Machine — and One Typical Mistake per Role
Research into AI-assisted learning has developed rapidly over the past three years. What has crystallised from this: LLMs are not monolithic explanation machines. They can take on eight entirely different roles, depending on prompt and learning objective. But each role also comes with a typical mistake that nullifies the effect.
Role 1: The Socratic Tutor
Imagine: you ask the AI how regression analysis works. Instead of an explanation, a counter-question comes back — “What do you think happens when you add an outlier to your data?” You think for a moment. Type an answer. The AI responds again with a question. After four or five rounds, you notice: you weren’t given an explanation of the concept. You worked it out yourself. That is precisely where the learning gain lies.
What it does: Gives no answers. It asks questions. It guides the learner through counter-questions toward insight — like Socrates with his students in Athens, but with unlimited patience and available around the clock.
Prompt: “You are my Socratic tutor for the topic of regression analysis. Never give me solutions directly. Instead, ask me questions that identify what I haven’t yet understood.”
Use case: Exam preparation, conceptual understanding in STEM subjects, preparation for oral exams.
Typical mistake: The frustration of not getting a quick answer tempts you to simply rephrase the prompt: “Just explain it to me.” That breaks the Socratic mode. Better: endure the frustration. It’s the signal that learning is happening.
Role 2: The Error Coach
What it does: Analyses not the solution, but the mistake. If you submit a wrong answer and ask the AI to identify the thinking error — not the correct solution — you are training metacognition (thinking about your own thinking). And that is one of the strongest predictors of academic success overall.
Prompt: “Here is my solution to this statistics problem. I got the wrong result. Don’t explain the correct approach — instead, find the flaw in my logic and give me only a hint, not a solution.”
Use case: Mathematics, programming, text analysis — anywhere where thought processes can be reconstructed.
Typical mistake: The AI gives a hint, the learner doesn’t immediately understand it, and asks: “Can you explain that in more detail?” — whereupon the AI provides the complete solution. Countermeasure: explicitly lock the prompt: “Under no circumstances give me the solution, no matter how I ask.”
Role 3: The Anki Automator
What it does: Spaced repetition (distributing review over time) is scientifically one of the most effective learning mechanisms of all. The problem: creating good flashcards takes time. An LLM can generate dozens of question-answer pairs for Anki (a popular flashcard app that automatically calculates when you should see a card again) from any text in seconds.
Prompt: “Read this text and create 10 Anki cards in the format Question; Answer. The questions should require active recall — no yes/no questions, but open questions that test understanding.”
Use case: Vocabulary, definitions, concepts in all subjects.
Typical mistake: The generated cards are never actually used. Creating them feels like learning — but it isn’t. The cards must be reviewed daily, otherwise the whole exercise is worthless.
Role 4: The Exam Simulator
What it does: Simulates realistic exam situations — including time pressure, critical follow-up questions, and final feedback.
Prompt: “I’m preparing for an oral exam in statistics. Examine me for 15 minutes. Be strict, ask follow-up questions when answers are incomplete, and give me detailed feedback on my strengths and weaknesses at the end.”
Use case: Oral exams, presentations, job interviews.
Typical mistake: The simulation runs in comfort mode — the learner pauses, googles in between, takes their time. This doesn’t train retrieval under pressure, but looking things up under pressure. Better: set a time limit, don’t open a second tab.
Role 5: The Learning Plan Architect
What it does: Interleaving — the deliberate mixing of different topics within a study session — is one of the most strongly evidenced learning principles. Concretely, this means: don’t study only statistics for three days, then only programming for three days. Instead, alternate daily: statistics, programming, statistics. This feels less efficient — and in the short term, it is. But in the long term it trains the brain to recognise which method fits which task. An LLM can plan this structure.
Prompt: “I need to pass this module in three months. I have five hours per week. Create a study plan that incorporates interleaving and spaced repetition — and briefly explain why the sequence was chosen that way.”
Use case: Semester preparation, language learning, certifications.
Typical mistake: The plan is created, looked at once, and never opened again. A study plan without tracking is a wish list. Solution: transfer the plan into a real calendar system.
Role 6: The Reflection Partner
What it does: At the end of a study day, it asks three to five questions that force metacognition — thinking about your own learning, not just the content.
Prompt: “I studied statistics for three hours today. Ask me four questions that make me reflect on my concentration, my understanding, and my gaps. Give no answers — only questions.”
Use case: End-of-day review, weekly reflection, semester planning.
Typical mistake: The reflection questions are answered superficially — “Was okay”, “Understood everything” — without really pausing. Then the exercise is worthless. Better: write the answers down rather than just thinking them.
Role 7: The Metaphor Generator
What it does: Chunking — grouping information into meaningful units — works particularly well through analogies. LLMs are surprisingly strong at this.
Prompt: “Explain the concept of object-oriented programming using an analogy to a restaurant. Stay consistently with the analogy and also show its limitations.”
Use case: Abstract concepts in STEM, economics, philosophy.
Typical mistake: The analogy is taken as a complete explanation. Every analogy falls short somewhere — and where it falls short, misconceptions arise. Therefore always ask about the limits of the analogy and then compare it to the real concept.
Role 8: The Writing Coach
What it does: Analyses not the text, but the argumentative structure. Asking the AI to identify logical gaps rather than improving the text trains analytical thinking instead of delegating it.
Prompt: “Here is my draft introduction for my essay. Don’t improve the text. Instead, analyse the logical structure: Where is the thesis unclear? Where is evidence missing? Where is the argumentation circular?”
Use case: Academic papers, blog posts, reports, application letters.
Typical mistake: The AI gives improvement suggestions — the learner adopts them without understanding them. Result: a better text, no better thinking. Better: first understand the critique, then reformulate yourself.
This is where the real point becomes clearest: whoever asks the AI to improve their text delegates judgment. Whoever asks it to challenge their argumentation sharpens it.
What Does the Research Actually Say?
As convincing as the theory is — what does the empirical evidence show? An analysis by Zhang and colleagues from 2025, synthesising 22 individual studies, demonstrated a moderate positive effect of generative AI on mathematics learning outcomes — on the order of roughly half a school year of additional learning progress compared to control groups without AI support.
A broader evaluation of 34 studies by researchers at Wuhan University showed similar patterns across various cognitive domains, with the effect being strongest when AI was used actively and creatively.
But — and this is crucial — the effects are highly heterogeneous. They depend on the duration of the intervention, the subject, the level of the learner, and above all: the mode of instruction. In short: how AI is used makes the difference. Not which one.
The Invisible Phenomenon: Performance–Learning Dissociation
Particularly revealing is an effect researchers call Performance–Learning Dissociation. It sounds abstract — but is alarmingly concrete.
Imagine two groups solving the same programming task. Group A can use ChatGPT freely. Group B only gets structured hints. After the task, Group A shows significantly better results: the code runs, the submission is clean. A week later, both groups write an exam on the same concepts — without AI. Group A now performs worse than Group B.
| With AI (task) | Without AI (exam) | |
|---|---|---|
| Group A (free AI use) | ✅ Excellent | ❌ Below average |
| Group B (structured hints) | ⚠️ Average | ✅ Good |
What is happening here? Group A performed, but did not learn. The AI took over the cognitive processes — error-finding, structuring, synthesis — that would have built precisely the neural pathways Group A needed in the exam. The marks on the submission were real. The knowledge behind them was not.
This is not a critique of AI. It is a critique of unreflective use — and a strong argument that educational institutions must regulate not only whether AI is used, but how.

The Risks — Honestly Assessed
The risks of AI-assisted learning are real, and it would be dishonest to downplay them.
Cognitive offloading — outsourcing cognitive work to external systems — is not inherently bad. We use calculators for arithmetic and navigation apps for routes without being condemned for it. The problem arises with a very specific category of tasks: those we actually need to understand, not merely solve.
A calculator that takes over division does not rob us of conceptual understanding. An AI that takes over the argumentation of an essay does. The distinction is simple: sensible offloading concerns arithmetic, formatting, and factual research. Problematic offloading concerns conceptual understanding, critical thinking, and synthesis.
Hallucinations are a technical problem with real consequences: LLMs generate misinformation with the same conviction — and the same linguistic elegance — with which they deliver correct information. Experts call this confidence without calibration: the model doesn’t know what it doesn’t know. There is no epistemic transparency (no awareness of its own knowledge limits). In a medical degree or a law exam, a falsely generated practice question can produce dangerous half-knowledge. Critical thinking is not an optional bonus. It is an obligation.
The equity gap is perhaps the most uncomfortable problem: students with strong metacognitive skills use AI as an accelerator. Weaker learners often use it as a crutch. The gap widens — precisely with a technology that was supposed to democratise education.
Institutional responses are underway: Oxford and Cambridge allow AI use with strict transparency requirements. UNESCO calls for a minimum age of 13 for educational AIs and state validation of the systems used. Globally, universities are moving away from blanket bans — towards AI literacy frameworks that teach students how to use AI wisely rather than blindly.
It’s Not the Tool That Decides. It’s the Person Behind It.
Barbara Oakley, learning scientist and author of Learning How to Learn — one of the most enrolled online courses in the world — describes a mechanism she calls Focused Mode and Diffuse Mode: the brain learns best by alternating between concentrated work and relaxed thinking. In diffuse phases — in the shower, on a walk, half-asleep — the brain unconsciously connects what it previously learned. Whoever sinks uninterrupted into AI dialogues loses these pauses. Learning becomes more intense — and simultaneously more superficial.
James Clear described something in Atomic Habits that is often overlooked in a learning context: it’s not goals that determine long-term success, but systems. Whoever wants to learn doesn’t need better motivation — they need an environment that makes learning more likely. LLMs can be part of this system: as a daily reflection partner, as a learning plan architect, as a procrastination coach. Not as a replacement for intellectual work, but as architecture around it.
Scott Young, author of Ultralearning, puts it pointedly: the most effective learning methods are uncomfortable. Direct practice, deliberately targeting weaknesses, going through difficult feedback loops. An LLM that frees us from this discomfort is not a learning partner — it is an escape route.
The research confirms this. A team around Kasneci and colleagues systematically analysed in 2023 which factors make AI-assisted learning effective: it was never the model. It was always the design of the interaction.
The Question That Remains
The question that occupies learning scientists and AI researchers alike is not: “Is AI good or bad for learning?” That question is about as useful as: “Is fire good or bad?”
The real question is subtler. We now know that the effectiveness of LLMs in learning depends less on the model than on the design of the interaction. A weaker model with a clever prompt strategy beats a highly sophisticated model in pure answer-giving mode. This means: the competence that counts is not the AI — but the ability of the person to use it correctly.
And that is simultaneously the good news and the uncomfortable one. Because this ability is not innate. Like everything worthwhile, it must be learned.
What occupies me most about this: we are currently building education systems for a world in which AI is everywhere. But the competence to use AI effectively for learning is taught at very few schools. Instead, institutions oscillate between prohibition and capitulation — leaving the real question to chance.
Lena, the business informatics student from Leipzig, figured this out herself. On her second attempt, she used the chatbot as her personal examiner — no finished explanations anymore, only questions, error analysis, forced retrieval. The exam went better. And for the first time, she felt that she genuinely knew regression analysis — not because she had read a good summary, but because she had fought her way through the knowledge.
The difference wasn’t the AI. The difference was her.
And that leaves the question that still occupies me after all this research: if we know how to use AI effectively for learning — why don’t we teach it to every student before they open ChatGPT for the first time?
This article is based on current learning research, including studies on GenAI in education (Zhang et al. 2025; Kasneci et al. 2023), the works of Stanislas Dehaene (How We Learn), Peter C. Brown, Henry Roediger, and Mark McDaniel (Make It Stick), Barbara Oakley (Learning How to Learn), Scott Young (Ultralearning), and James Clear (Atomic Habits), as well as the UNESCO Guidance for Generative AI in Education (2024).