Stellen Sie sich vor, Sie sitzen in den 1960er Jahren vor einem klobigen Fernschreiber. Sie tippen: „Ich bin traurig.“ Die Maschine rattert und antwortet: „Warum sagen Sie, dass Sie traurig sind?“ Magie? Nein, bloße Textbausteine nach Kochrezept.
Heute führen wir philosophische Debatten mit KI-Systemen, die Code schreiben, Gedichte verfassen und Unternehmensdaten analysieren. Wer mit ChatGPT, Claude oder lokalen Modellen in Automatisierungs-Workflows arbeitet, erlebt oft etwas fast Magisches: Man schreibt einen Satz – und bekommt brauchbare Antworten, Zusammenfassungen oder sogar funktionierenden Code.
Doch diese Magie ist das Ergebnis einer langen, überraschend stringenten Entwicklungslinie. Wer sie versteht, trifft bessere technische Entscheidungen: Welche Modelle? Welche Architektur? Wann reicht ein Prompt – und wann braucht es mehr?
Dieser Artikel zeichnet diese Linie nach. Nicht als akademische Historie, sondern als praktische Herleitung, warum moderne Large Language Models (LLMs) genau so funktionieren, wie sie funktionieren – und was das für den Aufbau einer zukunftssicheren, KI-fähigen Automatisierungsumgebung bedeutet.
Warum Sie das wissen sollten
Ob Sie ein RAG-System für Ihr Unternehmen aufsetzen, zwischen GPT-4 und lokalem Llama entscheiden, oder verstehen wollen, warum Ihr Chatbot manchmal halluziniert: Die Antworten liegen in dieser technischen Entwicklungslinie.
Wer weiß, dass ein LLM „nur“ Wahrscheinlichkeiten berechnet, stellt andere (bessere) Fragen. Wer versteht, warum RAG funktioniert, kann es gezielt einsetzen. Wer die Dekodierung durchschaut, kann Ausgaben steuern.
Die folgenden 60 Jahre Entwicklungsgeschichte sind keine akademische Fingerübung – sie sind der Schlüssel zu praktischen Entscheidungen, die Sie heute treffen müssen.
Was ein LLM technisch wirklich ist
Große Sprachmodelle lassen sich nüchtern beschreiben als probabilistische Textgeneratoren. Sie berechnen – Schritt für Schritt – die Wahrscheinlichkeit des nächsten Tokens (kleinste Texteinheiten, oft Wortteile) und bauen daraus eine Ausgabe.
Die heute dominante Bauform basiert auf Transformer-Modellen. Der Weg von der Eingabe zur Antwort lässt sich als Geschichte in vier Akten erzählen – von rohem Text zu scheinbar intelligenter Ausgabe. Jeder dieser Schritte trägt das Erbe jahrzehntelanger Forschung in sich.
Schauen wir uns an, wie wir hierher gekommen sind.
Die Steinzeit: Als Chatbots noch nach Kochrezept funktionierten
1966: ELIZA – Der Papagei ohne Gedächtnis
In den Anfängen war KI ein reines Regelwerk. Das prominenteste Beispiel ist ELIZA, entwickelt am MIT. Sie funktionierte wie ein Spiegel: Sie suchte nach Schlüsselwörtern und bog den Satz nach festen Mustern um.
Das Prinzip: Wenn „Mutter“ vorkommt, antworte: „Erzählen Sie mir mehr über Ihre Familie.“
Das Problem: Es gab kein echtes Sprachverständnis. ELIZA wusste nicht, was eine „Mutter“ ist; sie sah nur eine Zeichenfolge. Keinerlei Statistik, keine Semantik, kein Weltmodell.

Warum das trotzdem wichtig war: Text musste bereits segmentiert werden – eine primitive Form dessen, was wir heute Tokenisierung nennen. Und es gab schon eine Form von „Antwortgenerierung“, wenn auch extrem fragil.
ELIZA zeigte: Sprachinteraktion war möglich, aber mit dem Tiefgang eines Zaubertricks.
Die Ära der Wahrscheinlichkeit: Würfelspiel mit System
Späte 1960er bis 1990er: Hidden-Markov-Modelle – Das Fundament wird gelegt
Zwischen den 1970ern und 90ern wurde es mathematischer. Die Forscher verstanden, dass Sprache ein Prozess ist, bei dem eines auf das andere folgt. Hier betreten Hidden-Markov-Modelle (HMMs) die Bühne.
HMMs gehen davon aus, dass hinter dem, was wir sehen (Wörter), ein verborgener Zustand steckt (die Grammatik oder Absicht). Ein HMM versucht drei Dinge:
- Evaluation: Wie wahrscheinlich ist diese Wortfolge?
- Decoding: Was ist der wahrscheinlichste Weg durch den Satz?
- Training: Wie passe ich meine internen Regeln an die Daten an?
Warum das der direkte Vorläufer moderner LLMs ist:
Hier wurde das Fundament gelegt: Wir betrachten Sprache nicht mehr als starre Regel, sondern als Kette von Wahrscheinlichkeiten. Sequenzen werden probabilistisch erklärt. Es gibt eine klare Trennung zwischen „Verteilung berechnen“ und „konkrete Ausgabe wählen“.
Der Gedanke des Decodings (etwa durch den Viterbi-Algorithmus) – also die Frage, wie man aus Wahrscheinlichkeiten die beste konkrete Antwort findet – lebt bis heute fort. Wer das „nächste Wort“ vorhersagen will, muss rechnen können.
Der Durchbruch: Wenn Wörter zu Landkarten werden
2013: Word2Vec – Die Vektor-Revolution
Lange Zeit verstand der Computer Wörter als isolierte Symbole. „Hund“ und „Welpe“ waren für ihn so verschieden wie „Hund“ und „Kühlschrank“. Das änderte sich 2013 mit Word2Vec und dem Konzept der Embeddings (Einbettungen).
Wörter wurden in riesige, mehrdimensionale Koordinatensysteme (Vektoren) übersetzt. Plötzlich hatten Begriffe eine Position im Raum – und damit eine berechenbare Bedeutung.
Die berühmte Formel:
„König – Mann + Frau ≈ Königin“
funktionierte tatsächlich im Vektorraum.
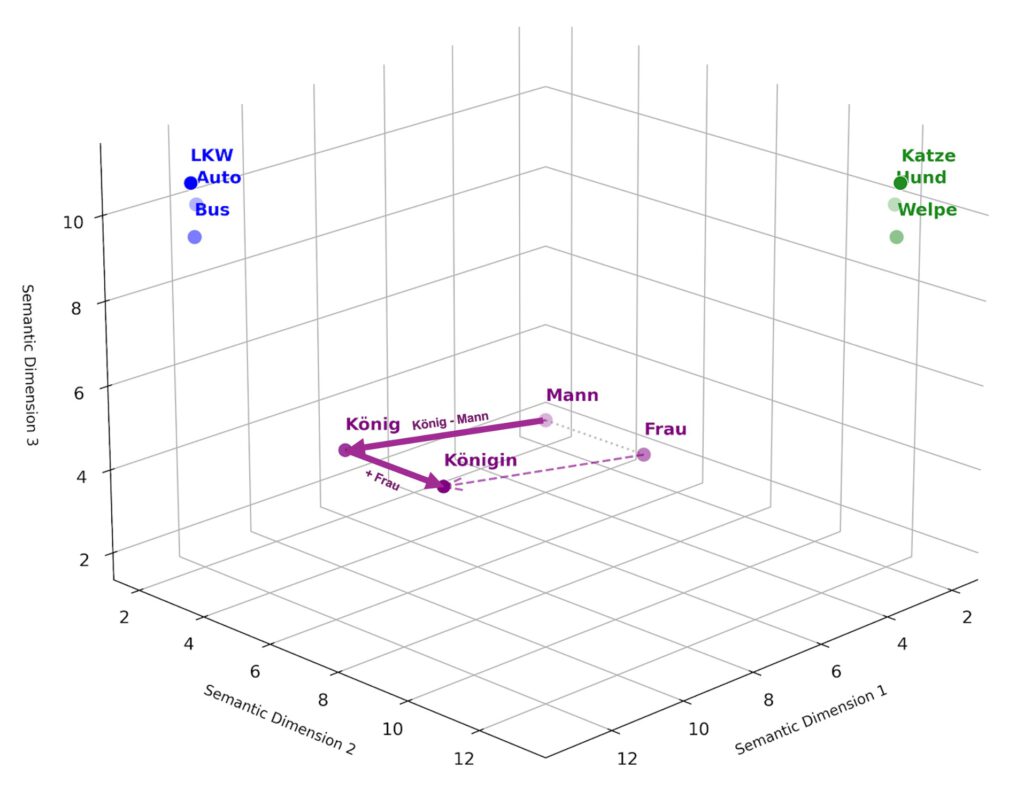
Warum das ein Meilenstein war:
- Diskrete Symbole wurden kontinuierlich
- Semantische Nähe wurde messbar
- Neuronale Netze konnten Sprache erstmals robust verarbeiten
- Erst durch diese mathematische „Nachbarschaft“ konnten KI-Modelle semantische Ähnlichkeiten verstehen, ohne dass ein Mensch sie explizit programmieren musste
Das war die Geburtsstunde des ersten Akts moderner LLMs: Text wird nicht mehr als Buchstabenfolge behandelt, sondern als Position in einem Bedeutungsraum.
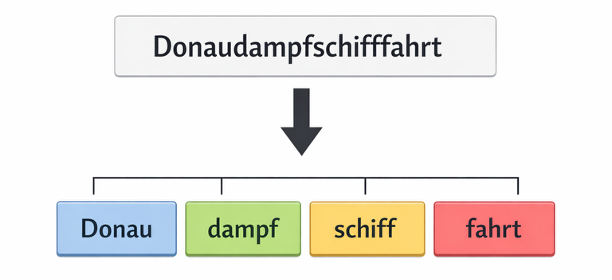
2015/2016: Subword-Tokenisierung – Das Lego-Prinzip für Sprache
Parallel löste die Subword-Tokenisierung (etwa durch Byte-Pair Encoding) ein altes Problem: Anstatt jedes Wort einzeln zu lernen, zerlegt man sie in Schnipsel.
So versteht die KI auch neue Wortschöpfungen wie „Donaudampfschifffahrtsgesellschaftskapitän“, indem sie die Bestandteile erkennt. Das löste praktische Probleme: offene Vokabulare, Komposita, Zahlen, Fachbegriffe.
Die Transformer-Revolution: Aufmerksamkeit ist alles
2017: „Attention Is All You Need“ – Der eigentliche Wendepunkt
2017 erschien ein Paper mit dem selbstbewussten Titel „Attention Is All You Need“. Es führte den Transformer ein (das „T“ in GPT). Die Innovation? Self-Attention.
Frühere Modelle lasen Sätze mühsam von links nach rechts und „vergaßen“ oft den Anfang, wenn er zu lang wurde. Der Transformer hingegen schaut sich den gesamten Text gleichzeitig an und gewichtet, welche Wörter füreinander wichtig sind.
Beispiel: Im Satz „Die Bank war nach dem langen Marsch eine Wohltat“ erkennt die KI durch Attention, dass mit „Bank“ das Sitzmöbel gemeint ist (wegen „Marsch“ und „Wohltat“) und nicht das Geldinstitut.
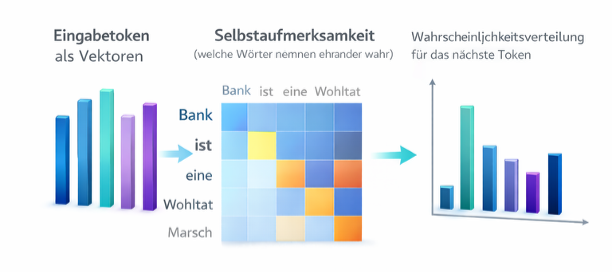
Die Konsequenzen:**
- Massive Parallelisierung möglich
- Lange Kontexte werden beherrschbar
- Skalierung wird praktikabel
- Alles kann gleichzeitig betrachtet werden – kein mühsamer Schritt-für-Schritt-Durchlauf mehr
Das ist der zweite Akt: Das Modell verarbeitet Bedeutungen und berechnet Zusammenhänge. Es erstellt eine Wahrscheinlichkeitsverteilung über zigtausende möglicher nächster Tokens.
Drei häufige Missverständnisse – aufgeklärt
Bevor wir weitergehen, lohnt es sich, drei hartnäckige Fehlvorstellungen über LLMs zu korrigieren:
❌ „Das Modell versteht mich wirklich“
✅ Es berechnet Wahrscheinlichkeiten basierend auf Mustern. Sehr gute Muster – aber kein Bewusstsein. Die „Landkarte“ aus Vektoren ist kein semantisches Verständnis im menschlichen Sinn, sondern statistische Nähe.
❌ „Größer ist immer besser“
✅ Ein kleines Modell + RAG + gute Prompts schlägt oft ein großes Modell ohne Kontext. GPT-4 ohne Zugriff auf Ihre Daten ist weniger nützlich als Llama-2 mit perfekt aufbereiteten Unternehmensdokumenten.
❌ „Halluzinationen sind ein Bug“
✅ Sie sind ein Feature: Das Modell füllt Wahrscheinlichkeitslücken. Es wurde trainiert, immer etwas zu generieren. RAG macht daraus einen kontrollierbaren Prozess, indem es echte Fakten als Anker liefert.
2020: GPT-3 und In-Context-Learning – Der Aha-Moment
Große Modelle zeigten plötzlich: Man kann Aufgaben im Prompt erklären, ohne das Modell neu zu trainieren. Gib ein paar Beispiele – und das Modell lernt „on the fly“.
Das ist kein Bewusstsein. Es ist Statistik in großer Dimension. Aber es fühlt sich magisch an.
Vom Plappermaul zum Assistenten: Der psychologische Feinschliff
Instruction Tuning – Wenn die KI lernt, was Sie wirklich wollen
Ein reines Sprachmodell wie GPT-3 war anfangs nur ein extrem guter Text-Vervollständiger. Wenn man fragte: „Wie backe ich einen Kuchen?“, antwortete es vielleicht mit: „Wie backe ich ein Brot? Wie backe ich Kekse?“ – weil es dachte, man wolle eine Liste von Buchtiteln vervollständigen.
Ein Basismodell beantwortet implizit: „Was kommt als Nächstes?“
Nutzer fragen aber: „Tu bitte X – unter meinen Bedingungen.“
Instruction Tuning schließt diese Lücke. Über Supervised Fine-Tuning und Reinforcement Learning from Human Feedback (RLHF) werden Antworten wahrscheinlicher, die hilfreich, korrekt und kooperativ wirken.
Menschen bewerteten die Antworten der KI, und ein Belohnungsmodell brachte ihr bei, hilfreicher, höflicher und weniger „halluzinatorisch“ zu sein. ChatGPT war geboren.
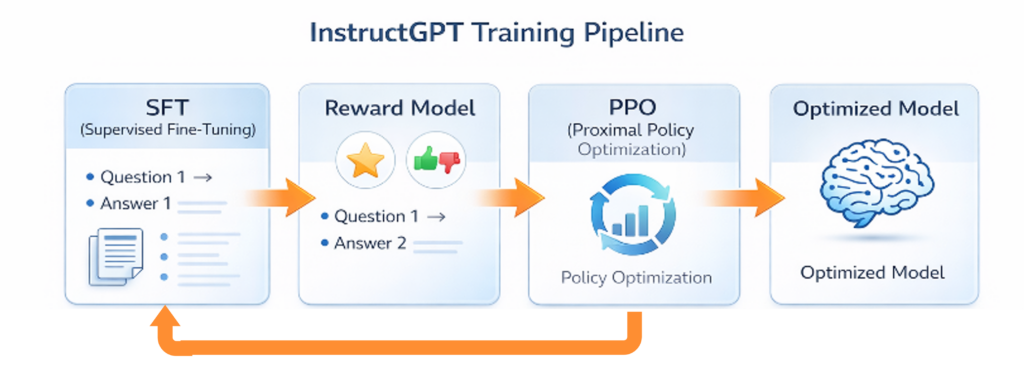
Das ist der dritte Akt: Das Modell lernt nicht nur „was ist statistisch wahrscheinlich“, sondern „was will der Mensch wirklich hören“. Die Architektur bleibt gleich – aber die Wahrscheinlichkeiten verschieben sich Richtung Nützlichkeit.
Die Gegenwart: RAG – Wissen ohne Raten
Wenn das Modell nachschlägt statt halluziniert
Trotz aller Intelligenz haben LLMs ein Problem: Ihr Wissen ist „eingefroren“ (am Trainings-Cutoff) und sie neigen zum Flunkern, wenn sie die Antwort nicht genau wissen.
Hier kommt RAG (Retrieval-Augmented Generation) ins Spiel – das aktuelle Gold-Standard-Muster für Unternehmen.
Stellen Sie sich RAG wie eine „Open-Book-Klausur“ vor:
- Die KI bekommt eine Frage
- Sie sucht in Ihren eigenen Daten (PDFs, Datenbanken, Wikis) nach relevanten Stellen – über Embeddings, also Vektorsuche
- Sie bekommt diese Textstellen als Kontext geliefert
- Sie formuliert die Antwort nur basierend auf diesen Fakten
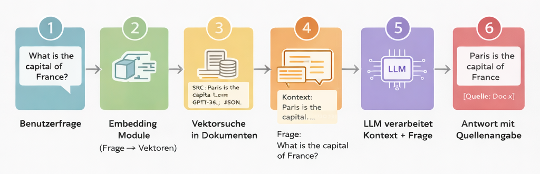
Praktisch bedeutet das:
- Dokumente werden segmentiert
- Embeddings werden berechnet
- In einem Vektorindex gespeichert (etwa ChromaDB, Weaviate)
- Zur Laufzeit wird relevanter Kontext gesucht
- Dem Prompt hinzugefügt
Das LLM verarbeitet dann konkrete Quellen, statt zu halluzinieren. Das macht die KI verlässlich, aktuell und vor allem: Sie „erfindet“ deutlich seltener Fakten, da sie eine Quelle zum Nachschlagen hat.
Wie ein LLM funktioniert: Vier Schritte von Text zu Intelligenz
Alles, was wir heute an KI bewundern, lässt sich auf vier funktionale Schritte reduzieren, die das Erbe der letzten 60 Jahre in sich tragen. Jeder Schritt beantwortet eine grundlegende Frage auf dem Weg von rohem Text zur nützlichen Antwort.
1. Verstehen: Text wird zu Bedeutung
Die Frage: Wie macht das Modell aus Buchstaben etwas, womit es rechnen kann?
Die Lösung: Tokenisierung + Embeddings
Text wird zerlegt (von ELIZAs Keyword-Tricks zur modernen Subword-Logik) und in einen mehrdimensionalen Bedeutungsraum übersetzt. „König“ und „Königin“ liegen näher beieinander als „König“ und „Brot“ – das Modell „versteht“ semantische Nähe.
Historische Wurzeln:
- ELIZA (1966): Primitive Textsegmentierung
- Word2Vec (2013): Vektoren statt Symbole
- Subword-Tokenisierung (2015): Lego-Prinzip für offene Vokabulare
Ergebnis: Jedes Token ist jetzt ein Vektor – eine Position im Bedeutungsraum. Das Modell kann mit Konzepten rechnen.
2. Denken: Der Transformer berechnet Zusammenhänge
Die Frage: Wie erkennt das Modell, welche Wörter wichtig füreinander sind?
Die Lösung: Self-Attention im Transformer
Das Modell schaut sich alle Wörter gleichzeitig an und gewichtet: Was ist für was relevant? Bei „Die Bank war eine Wohltat nach dem Marsch“ erkennt es: Bank = Sitzgelegenheit, nicht Geldinstitut.
Historische Wurzeln:
- Hidden-Markov-Modelle (1970er–90er): Sequenzen als Wahrscheinlichkeitsketten
- Transformer (2017): Self-Attention ersetzt sequenzielle Verarbeitung
- Skalierung (2020+): GPT-3 zeigt, was große Modelle können
Ergebnis: Eine Wahrscheinlichkeitsverteilung über 50.000+ mögliche nächste Tokens. Für jedes Token: „Wie wahrscheinlich passt es hier?“
3. Wählen: Von Wahrscheinlichkeit zu Text
Die Frage: Wie wird aus „Token A: 23%, Token B: 19%, Token C: 15%“ ein konkretes Wort?
Die Lösung: Dekodierungsstrategien
Das Modell hat Wahrscheinlichkeiten berechnet – aber welches Token wählen wir tatsächlich?
- Greedy: Nimm immer das wahrscheinlichste (langweilig, aber sicher)
- Beam Search: Behalte mehrere Pfade parallel und wähle den besten Gesamtpfad
- Top-k Sampling: Wähle zufällig aus den k wahrscheinlichsten Tokens
- Top-p (Nucleus): Würfle gewichtet aus den wahrscheinlichsten Tokens, bis ihre Summe p% erreicht (kreativer, aber riskanter)
Historische Wurzeln: - Viterbi-Algorithmus (1980er): Beste Pfade durch Wahrscheinlichkeitsräume
- Beam Search: Aus der maschinellen Übersetzung
- Sampling-Strategien: Balance zwischen Kreativität und Kohärenz
Ergebnis: Ein konkretes Token. Wiederhole den Prozess, bis ein Satz entsteht.
Gleiche Gewichte, andere Strategie – völlig andere Qualität. Die Dekodierung entscheidet, ob Ihre Antwort kreativ oder konservativ, flüssig oder repetitiv wird.
4. Optimieren: Vom Papagei zum Assistenten
Die Frage: Wie lernt das Modell, hilfreiche statt nur wahrscheinliche Antworten zu geben?
Die Lösung: Instruction Tuning & RLHF
Das Modell lernt nicht nur „was kommt statistisch als Nächstes“, sondern „was will der Mensch eigentlich hören“. Menschen bewerten Antworten → ein Belohnungsmodell verschiebt die Wahrscheinlichkeiten Richtung „hilfreich, korrekt, kooperativ“.
Historische Wurzeln:
- Supervised Fine-Tuning: Trainieren auf Frage-Antwort-Paaren
- RLHF (2022): InstructGPT/ChatGPT lernen aus menschlichem Feedback
- Constitutional AI: Modelle lernen Prinzipien statt nur Beispiele
Ergebnis: Ein System, das tut, was Sie wollen – nicht nur, was statistisch auf Ihre Eingabe folgen würde. Die Architektur bleibt identisch, aber der Wahrscheinlichkeitsraum ist anders kalibriert.
Was das konkret für Ihre Architektur-Entscheidungen bedeutet
Die Theorie ist das eine – aber welche praktischen Entscheidungen folgen daraus? Hier drei typische Szenarien:
Beispiel 1: Modellwahl – GPT-4 oder lokales Llama?
Sie überlegen, ob Sie auf Cloud-Modelle oder lokale Open-Source-Lösungen setzen?
Was Sie jetzt verstehen:
- Beide nutzen die gleichen vier Prinzipien (Verstehen → Denken → Wählen → Optimieren)
- Der Unterschied liegt primär in Trainingsdaten (Menge und Qualität) und Optimierung (Wie viel RLHF-Budget wurde investiert?)
- Entscheidend ist: Ein kleines lokales Modell + perfekt aufbereitetes RAG kann präziser sein als GPT-4 ohne Kontext zu Ihren Daten
Praktische Konsequenz:
Wenn Sie Datenhoheit brauchen und domänenspezifische Aufgaben haben, ist Llama-2 (13B) + RAG oft besser als GPT-4 ohne Ihre Wissensbasis.
Beispiel 2: Prompt-Engineering – Warum funktioniert „Denke Schritt für Schritt“ so gut?
Sie haben bemerkt, dass „Think step by step“ oder „Erkläre deine Überlegung“ die Antwortqualität massiv verbessert?
Was Sie jetzt verstehen:
- Dekodierung bevorzugt wahrscheinliche Fortsetzungen
- „Schritt für Schritt“ triggert strukturierte Reasoning-Patterns aus dem Training (Chain-of-Thought)
- Das ist kein Trick – sondern bewusste Nutzung der Wahrscheinlichkeitsverteilung: Sie lenken das Modell in einen Bereich des Vektorraums, wo sorgfältige Analysen wahrscheinlicher sind
Praktische Konsequenz:
Ihre Prompts sind keine Magie, sondern Wahrscheinlichkeits-Steuerung. Je besser Sie verstehen, was während des Trainings (Schritt 4: Optimieren) gelernt wurde, desto präziser können Sie promten.
Beispiel 3: Halluzination reduzieren – Drei technische Hebel
Ihr System erfindet manchmal Fakten. Sie wollen das minimieren?
Was Sie jetzt verstehen:
Hebel 1 – Temperature (Dekodierung):
- Niedrige Temperature (z.B. 0.2) = konservativere Token-Wahl
- Das Modell bleibt näher an hochwahrscheinlichen Fortsetzungen
- Einsatz: Für faktische Aufgaben wie Datenextraktion
Hebel 2 – RAG (Kontext): - Liefern Sie dem Modell echte Quellen im Prompt
- Das verschiebt die Wahrscheinlichkeitsverteilung weg von „ich rate mal“ hin zu „ich paraphrasiere die Quelle“
- Einsatz: Für wissensintensive Aufgaben (Support, Recherche)
Hebel 3 – System-Prompts (Optimierung): - „Antworte nur auf Basis der bereitgestellten Quellen. Wenn unsicher, sage: Ich weiß es nicht.“
- Nutzt die RLHF-Kalibrierung: Das Modell wurde trainiert, Anweisungen zu befolgen
- Einsatz: In Kombination mit RAG für maximale Verlässlichkeit
Praktische Konsequenz:
Sie brauchen nicht ein perfekteres Modell – Sie brauchen die richtige Kombination aus Dekodierung, Kontext und Instruktion.
Klare Entscheidung: Was heißt das für heutige Systeme?
Die Demokratisierung dieser Technologie bedeutet, dass Sie heute keine Milliarden-Infrastruktur mehr brauchen, um eigene, sichere KI-Umgebungen zu bauen.
LLMs sind keine Blackbox-Magie, sondern präzise Funktionsketten mit nachvollziehbaren Mechanismen:
- Verstehen macht Text berechenbar (Embeddings)
- Denken berechnet Zusammenhänge (Transformer)
- Wählen produziert konkrete Ausgaben (Dekodierung)
- Optimieren macht Ausgaben nützlich (Instruction Tuning)
- RAG macht das System verlässlich und aktuell (externe Wissensbasis)
Wer heute eine zukunftssichere, KI-fähige Automatisierungsumgebung aufbaut, sollte genau hier ansetzen: bei der bewussten Kombination aus Modell, Kontext, Dekodierung und Evaluation.
Mit RAG können Sie Ihre Datenhoheit behalten und dennoch modernste Automatisierung nutzen. Open-Source-Modelle lassen sich lokal betreiben, ohne Ihre Daten in die Cloud zu schicken.
Qualität entsteht nicht nur im Modell, sondern im Systemdesign.
Nicht spektakulär. Aber sehr wirksam.
Der Weg von starren Regeln zu probabilistischen Wunderwerken war kein plötzlicher Geistesblitz, sondern eine faszinierende technische Ahnenreihe. Wer sie versteht, kann die heutige KI-Revolution nicht nur begreifen – sondern für das eigene Unternehmen bändigen.