
Obsidian als Second Brain mit OpenClaw oder Claude
Eine Nachricht aus dem ICE
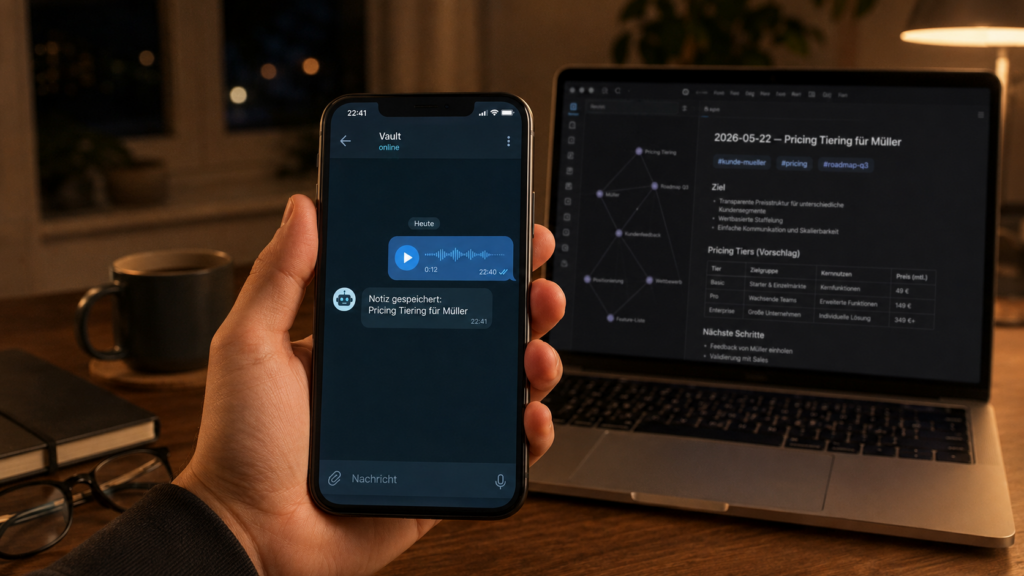
Es ist 19:42 Uhr, als Mark am Hauptbahnhof Mannheim auf seinen Zug wartet. Zwei Stunden Workshop sitzen ihm in den Knochen, sein Kopf surrt noch von Folien und Flipcharts, und genau in diesem Moment, irgendwo zwischen Bratwurststand und Anzeigetafel, kommt ihm dieser eine Satz. Eine Idee, die seinen Kunden im nächsten Projekt weiterbringen würde. Eine Idee, die er morgen früh um halb acht garantiert vergessen haben wird, wenn er sie jetzt nicht festhält.
Mark zückt das Handy. Öffnet Telegram. Tippt nicht, er spricht. Eine knappe Sprachnachricht an einen Chat, der einfach „Vault“ heißt: „Idee für Kunde Müller, bei der Roadmap im Kapitel Q3 sollte ich noch das Thema Pricing Tiering aufgreifen, mit Verweis auf das, was wir letzte Woche zu wertbasierter Preisgestaltung besprochen haben.“Senden. Handy in die Innentasche. Einsteigen.

Drei Stunden später, zu Hause am Küchentisch. Mark klappt den Laptop auf, öffnet Obsidian, und stutzt. In seinem digitalen Notizbuch, einem Ordner mit mittlerweile fast achthundert Dateien, liegt schon eine neue Notiz. Sie heißt 2026-05-22 – Pricing Tiering für Müller. Sie ist im richtigen Projekt-Ordner abgelegt. Sie hat die passenden Schlagworte bekommen: #kunde-mueller, #pricing, #roadmap-q3. Und sie verlinkt, das ist das eigentlich Erstaunliche, auf eine andere Notiz vom Mittwoch, in der Mark tatsächlich über wertbasierte Preisgestaltung gesprochen hatte.
Vier Monate vorher hätte Mark dieselbe Sprachnachricht wahrscheinlich in Telegram vergessen, irgendwo zwischen Bestellbestätigungen und Hochzeitsfotos seiner Schwester. Aber im Laufe des Frühjahrs hat er sich etwas aufgebaut, das diese Nachrichten nicht mehr verloren gehen lässt. Nicht ohne Reibung. Nicht ohne ein, zwei verlorene Wochenenden, in denen das System Dinge tat, die er nicht gewollt hatte, und in denen er mehr Zeit mit Aufräumen verbrachte als mit Arbeiten. Aber es funktioniert jetzt.
Wer Mark hier über die Schulter schaut, könnte denken: Cloud-Magie. Ein bisschen ChatGPT, ein bisschen Notion, irgendwo dazwischen ein Zapier-Workflow. Tatsächlich passiert etwas anderes. Kein einziges Wort von Marks Sprachnachricht hat seinen Wohnsitz verlassen. Der Bot, der Marks Idee einsortiert hat, läuft auf einem kleinen Server in Marks Heizungskeller, drei Meter neben dem Wäschetrockner.
Was hier eigentlich passiert
Mark ist nicht allein. Eine wachsende, leise Gruppe von Beratern, Wissensarbeitern, Forschern und neugierigen Entwicklern baut sich derzeit etwas, das man bis vor wenigen Jahren unter „Enterprise-Lösung“ verbucht hätte: ein eigenes, KI-gestütztes Wissenssystem. Die Personal-Knowledge-Management-Szene nennt das gern ein zweites Gehirn. Der Begriff ist mittlerweile etwas abgenutzt und beschreibt nichts Magisches, sondern schlicht ein vernetztes, maschinenlesbares Notizsystem, in dem einzelne Notizen über Verlinkungen, Tags und semantische Ähnlichkeiten zueinander in Beziehung stehen. Neu daran ist nur: Mit KI obendrauf antwortet dieses Notizsystem jetzt zurück.
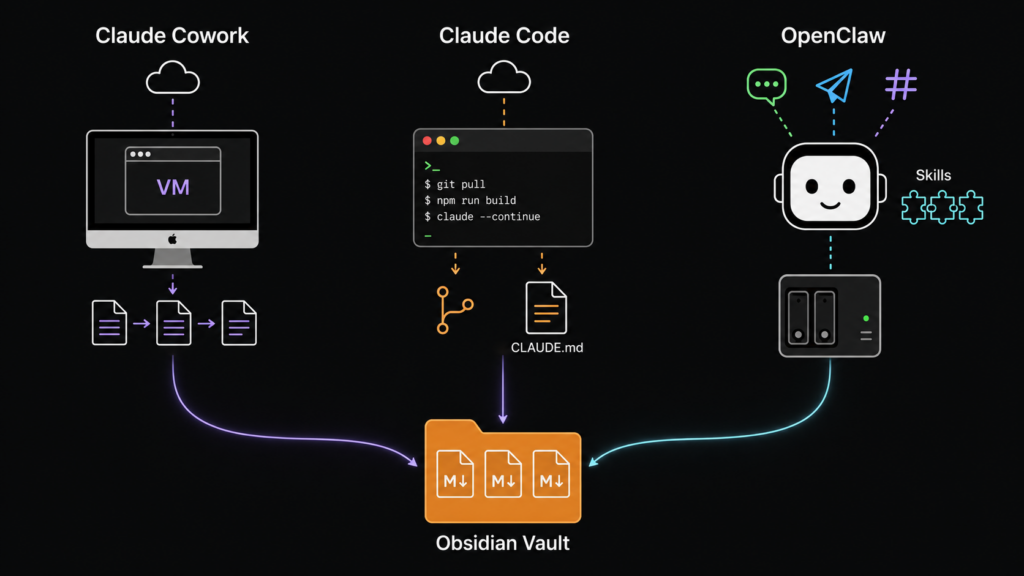
Die Bausteine sind dabei erstaunlich profan. Auf der einen Seite ein Vault (so heißt der Ordner in Obsidian, in dem alle Notizen liegen) mit hunderten kleiner Textdateien. Auf der anderen Seite ein KI-Agent (ein Programm, das nicht nur Fragen beantwortet, sondern selbständig Aktionen ausführt, Dateien lesen, sortieren, schreiben). Dazwischen eine Brücke, die je nach Setup ein paar Zeilen Code, ein lokales Plugin oder eben, bei Mark, ein selbst betriebener Bot im Heizungskeller ist.
Was diese Kombination interessant macht, ist nicht die Technik. Die Technik gibt es seit zwei, drei Jahren. Interessant ist die Verschiebung dahinter: Auf einmal können Einzelpersonen Dinge tun, für die Unternehmen vor kurzem noch ein sechsstelliges Budget bewilligt hätten. Und sie können es tun, ohne dabei ihre Notizen an einen Anbieter zu verschenken, der morgen seine Geschäftsbedingungen ändert.
Drei Wege haben sich dafür herauskristallisiert. Sie heißen Claude Cowork, Claude Code oder OpenClaw, und unterscheiden sich vor allem im Verhältnis zwischen Komfort, Kontrolle und Aufwand.
Drei Wege im Überblick
Bevor wir uns die drei Werkzeuge im Detail anschauen, eine kompakte Gegenüberstellung. Sie hilft, die richtige Schublade für den eigenen Anwendungsfall zu erkennen, der nachfolgende Text vertieft dann, was hinter den jeweiligen Stichworten steckt.
| Aspekt | Claude Cowork | Claude Code | OpenClaw |
|---|---|---|---|
| Komfort | Sehr hoch, Desktop-App mit Grafik | Mittel, Terminal-basiert | Hoch nach Setup, Bedienung per Messenger |
| Datenschutz | Claude-Verarbeitung über Anthropic; lokale Datei-Freigabe erforderlich | Claude-Verarbeitung über Anthropic; lokale Datei-Freigabe erforderlich | Je nach Modell lokal oder API-basiert; Kontrolle liegt beim Betreiber |
| Setup-Aufwand | Minuten | Minuten | 4–8 Stunden initial |
| Laufende Kosten | ~20 €/Monat (Claude-Abo) | ~20 €/Monat (Claude-Abo) | 5–95 €/Monat (Server + API) |
| Verfügbarkeit | Solange Desktop läuft | Solange Terminal-Session läuft | 24/7, auch unterwegs |
| Zielgruppe | Wissensarbeiter ohne Terminal-Lust | Entwickler und Bastler | Self-Hoster und Tech-Begeisterte |
| Größtes Risiko | Datenabfluss bei sensiblen Notizen | Versehentliche Schreibaktionen | Komplexität und Token-Kostenfallen |
Wer schnell entscheiden will: Für die meisten Knowledge Worker ohne Programmierhintergrund ist Cowork der bequemste Einstieg, für Entwickler Claude Code, und für Tech-affine Self-Hoster mit Synology oder ähnlicher Hardware OpenClaw. Aber wie immer steckt der Teufel in den Übergängen, und genau die schauen wir uns jetzt an.
Der Vault, oder warum Markdown plötzlich strategisch wird
Bevor wir zu den drei Werkzeugen kommen, ein kurzer Halt bei der Grundlage. Obsidian, das Programm, mit dem Mark seine Notizen schreibt, hat eine Eigenschaft, die in Zeiten von KI-Agenten plötzlich strategisch wichtig wird: Es speichert nichts in einer eigenen Datenbank. Keine Cloud. Keine proprietäre Datei. Sondern stinknormale Markdown-Dateien (schlanke Textdateien mit einfachen Formatierungen, eine Raute am Zeilenanfang ist eine Überschrift, zwei eckige Klammern ergeben einen Link). In einem Ordner. Auf der eigenen Festplatte.
Das klingt unspektakulär, aber für die KI-Anbindung ist es entscheidend. Ein KI-Agent muss kein proprietäres Format „verstehen“. Er muss keine API ansprechen, deren Anbieter morgen die Preise erhöht. Er liest Text. Aus einem Ordner. So wie ein Mensch auch.
Ein anderes Detail wird wichtig: Weil alles in Textdateien liegt, lassen sich Änderungen zeilengenau nachvollziehen. Mit Git (einem Versionskontrollsystem, ursprünglich für Software-Entwickler, das jeden Zustand der Dateien speichert und nachvollziehbar macht, wer wann was geändert hat) wird der Vault zu einem System, in dem jede KI-Aktion mit einem Mausklick rückgängig gemacht werden kann. Wir kommen darauf zurück, denn das ist der Sicherheitsgurt der ganzen Geschichte.
Was hinter den drei Optionen steckt
Claude Cowork: der Schreibtisch-Assistent
Anfang 2026 hat Anthropic, das Unternehmen hinter dem KI-Modell Claude, ein Programm namens Cowork auf den Markt gebracht. Es ist im Kern eine Desktop-Anwendung, die das tut, was man bis dahin nur über die Kommandozeile haben konnte: Claude bekommt Zugriff auf lokale Dateien und kann darin selbständig arbeiten.
Für Mark und sein Obsidian wäre Cowork der bequemste Einstieg. Man gibt Claude einen Ordner frei, beschreibt eine Aufgabe, und Claude legt los. „Schau dir mal die Notizen im Ordner Inbox an und schlag mir vor, in welche Projekt-Ordner sie gehören.“ Oder: „Aus den Meeting-Notizen der letzten zwei Wochen, fass mir die offenen Entscheidungen zusammen, gruppiert nach Projekt.“ Cowork läuft das alles ab, zeigt vorher, was es vorhat, und legt das Ergebnis im Vault ab.
Der Komfort hat einen Preis. Cowork läuft zwar lokal auf dem Desktop und hat sogar eine kleine isolierte virtuelle Maschine (VM) für die Code-Ausführung mit an Bord, aber die eigentliche Verarbeitung jeder Aufgabe läuft über Claude und braucht eine aktive Verbindung zu Anthropic. Die Dateien bleiben also nicht automatisch „privat“, nur weil sie auf der eigenen Festplatte liegen. Alles, was Claude zur Bearbeitung lesen muss, wird Teil der KI-Verarbeitung beim Anbieter. Für allgemeine Recherche, Blogentwürfe oder Lernnotizen ist das kein Drama. Für Mandantenakten eines Anwalts oder Krankenakten eines Therapeuten ist es ein Problem.
Cowork braucht außerdem ein bezahltes Claude-Abo (etwa zwanzig Euro im Monat) und eine geöffnete Desktop-Anwendung, damit der Agent läuft. Wer den Laptop zuklappt, schickt seinen Assistenten in den Feierabend.
Claude Code: das Werkzeug der Bastler
Claude Code ist der Bruder von Cowork, älter, technischer, ohne Grafik. Eigentlich ist er für Softwareprojekte gebaut: Anthropic beschreibt das Tool als agentischen Assistenten fürs Terminal (jenem schwarzen Textfenster, vor dem viele Nutzer reflexhaft den Browser schließen), der Codebases versteht, Dateien editiert, Tests laufen lässt und Git-Workflows unterstützt. Aber weil ein Obsidian-Vault am Ende nichts weiter ist als ein Ordner mit Textdateien, und weil Software-Repositories auch nichts wesentlich anderes sind, lässt sich Claude Code erstaunlich gut zweckentfremden.
Der Reiz von Claude Code liegt in der Reproduzierbarkeit. Man kann dem Agenten Skills beibringen, wiederverwendbare Anweisungs-Pakete, die festlegen, wie er bestimmte Aufgaben angeht. Man kann ihm eine Datei namens CLAUDE.md in den Vault legen, in der die Regeln des Hauses stehen: Welche Ordner sind tabu? Welche Tags gibt es? Wie sollen neue Notizen aussehen? Bei jedem Start liest Claude Code diese Regeln, bevor er auch nur eine einzige Datei anfasst.
Für Entwickler, die ohnehin im Terminal leben, ist das eine natürliche Verlängerung ihres Arbeitsalltags. Für alle anderen ist es eine kleine Hürde, aber eine, die sich oft lohnt. Wer einmal verstanden hat, wie man Claude Code mit einer guten CLAUDE.md-Datei dressiert, hat einen Assistenten, der präziser arbeitet als jede Chat-Oberfläche es zulässt.
OpenClaw: der Bot im Heizungskeller
Und dann ist da OpenClaw. Der eigenwillige Außenseiter, der genau das macht, was bei Mark den Unterschied ausmacht.
OpenClaw ist ein Open-Source-Projekt, also frei verfügbarer, einsehbarer Quellcode, an dem eine globale Community arbeitet. Es startete unter dem Namen Clawdbot, hieß zwischenzeitlich Moltbot und heißt seit etwa einem Jahr OpenClaw. Was es macht: Es bietet ein Gerüst, mit dem man sich seinen eigenen, persönlichen KI-Agenten zusammenbauen kann. Auf der eigenen Hardware. Selbst betrieben. Mit selbst gewählten KI-Modellen im Hintergrund (Claude, GPT-4, oder ein lokal laufendes Open-Source-Modell, ganz nach Belieben).
Das Besondere ist die Architektur. OpenClaw besteht aus fünf Bausteinen: einem Gateway (dem Verkehrsknoten, der alle Anfragen entgegennimmt), einem LLM-Backend (also dem eigentlichen KI-Modell, das die Sprache versteht), modularen Skills (etwa einem Skill zum Lesen und Schreiben im Obsidian-Vault), einem Langzeitgedächtnis (das sich merkt, was der Agent über die Sessions hinweg gelernt hat) und schließlich den Messaging-Kanälen, und hier kommt die Pointe.
OpenClaw lässt sich an WhatsApp, Telegram, Slack, Discord, Microsoft Teams, Signal und iMessage anbinden. Mit anderen Worten: Marks Bot ist über die Messenger-App erreichbar, die ohnehin auf seinem Handy läuft. Er muss kein neues Programm öffnen, keine spezielle App installieren, keinen Browser-Tab aufrufen. Er sagt Telegram Bescheid, und der Rest passiert.
Die Kosten für so ein Setup liegen 2026 zwischen fünf und fünfundneunzig Euro pro Monat, etwa fünf Euro für den Server, zehn bis neunzig für API-Aufrufe an das KI-Modell. Wer auf einem heimischen Netzwerk-Speicher (einem NAS, also einem kleinen Server-Gerät mit Festplatten, das man oft sowieso für Backups zu Hause stehen hat) seine Notizen ablegt, kann OpenClaw direkt dort installieren, und hat einen Always-on-Assistenten, der nichts kostet außer Strom.
Was die KI eigentlich mit dem Vault macht
Hier wird es konkret. Ein KI-gestütztes Second Brain klingt nach Science-Fiction, ist aber im Alltag erstaunlich nüchtern. Die spannendsten Anwendungen sind selten die, bei denen die KI etwas „Neues“ erfindet. Die spannendsten sind die, bei denen sie Reibung wegnimmt.
Eine erste Klasse von Aufgaben sind die unsichtbaren Hausmeister-Arbeiten. Tags vereinheitlichen, kaputte Links reparieren, neue Notizen aus der Inbox in die richtigen Projektordner einsortieren, doppelte Einträge finden. Eine Beraterin, die seit vier Jahren in Obsidian arbeitet, beschreibt diesen Bereich als „die Stunde Aufräumen, die ich jeden Sonntag nicht mehr selbst machen muss“. Es ist nichts Glamouröses. Es ist genau das, was wertvoll wird, wenn der Vault auf ein paar tausend Notizen anwächst.
Eine zweite Klasse sind die Synthese-Aufgaben. Mark, der Berater aus dem Eingang, lässt seinen Bot wöchentlich einen kurzen Statusbericht über alle aktiven Kundenprojekte erstellen, auf Basis der Notizen, die er selbst geschrieben hat. Was ist offen, was sind die nächsten Schritte, wo gibt es Risiken. Drei Absätze pro Kunde, fertig zum Lesen am Sonntagabend. Was vorher zwei Stunden Eigenarbeit war, ist jetzt eine Telegram-Nachricht.
Eine dritte Klasse, die für Content Creator wie Mark besonders attraktiv ist, ist die Wiki-zu-Blog-Pipeline. Notizen, die über Wochen entstanden sind, werden vom Agenten zu einem ersten Entwurf zusammengezogen. Er weiß, welche Themen Mark bereits behandelt hat, in welchem Stil Mark schreibt, welche Quellen Mark bevorzugt. Der Output ist kein fertiger Artikel, niemand sollte ungeprüft veröffentlichen, was ein Agent ausspuckt, aber er ist ein deutlich besserer Startpunkt als das leere Blatt.
Eine vierte Klasse, exklusiv für OpenClaw-Setups, ist die Capture per Messenger. Sprachnachricht im Auto, Foto eines Whiteboards nach dem Meeting, kurze Texteingabe auf der Joggingrunde, alles landet im Vault, getaggt, verlinkt, mit Datum und Quellenangabe. Die Reibung zwischen Idee und Festhalten ist so klein wie technisch möglich.
Das stille Risiko: Was die KI alles sieht
Bis hierhin liest sich die Geschichte wie eine Werbebroschüre. Sie ist es nicht. Wer ein Wissenssystem öffnet, das jahrelang gewachsen ist, und einer KI Zugriff darauf gibt, sollte sich ein paar Dinge klarmachen, bevor er auf „Verbinden“ klickt.
Das erste Ding ist eine Frage der Sortierung. In einem gut gepflegten Vault wohnen drei Sorten von Inhalten in friedlicher Koexistenz. Da sind die grünen Notizen: Blogideen, allgemeine Recherchen, Lernmaterial. Mit denen darf eine KI machen, was sie will. Da sind die gelben Notizen: aktive Projekte, Kundenkontext, interne Strategiepapiere. Hier ist Vorsicht angebracht, und der Vertrag mit dem KI-Anbieter sollte stimmen. Und da sind die roten Notizen: Passwörter, Mandantendaten, Personalakten, Gesundheitsdaten. Diese dürfen in keinem Setup je in einen Cloud-Dienst gelangen. Punkt.
Die Versuchung, alles in einen einzigen Vault zu werfen und der KI „mal eben so“ Zugriff zu geben, ist groß. Sie ist auch der häufigste Fehler. Wer rote Daten in einem Vault hat, durch den ein Cloud-Modell krabbelt, hat diese Daten an den Anbieter geschickt, auch wenn er nur „mal kurz nachschauen“ wollte.
Das zweite Ding sind versehentliche Geheimnisse. Ein Obsidian-Vault wächst über Jahre. In ihm sammeln sich Kostproben aus dem Alltag: API-Schlüssel aus einem alten Projekt, Recovery-Codes, eine schnell hingekritzelte .env-Datei mit Datenbank-Zugangsdaten, vielleicht ein paar Passwörter, die mal kurz „nur für eine Minute“ notiert wurden und dann nie gelöscht wurden. Sobald ein KI-Agent Lesezugriff bekommt, können all diese Schnipsel im Kontext landen, und bei Cloud-Modellen auf den Servern des Anbieters. Wer das vermeiden will, scannt seinen Vault vor dem ersten KI-Zugriff einmal mit einem Werkzeug wie gitleaks oder trufflehog und räumt das gefundene Material in einen Passwortmanager. Keine Geheimnisse im Vault. Diese Regel klingt banal und wird trotzdem ständig verletzt.
Eine dritte Risikoart ist subtiler und wird gern unterschätzt: die Prompt Injection. Eine vom OWASP-Konsortium (einer etablierten Organisation für IT-Sicherheits-Standards) im Top-10-Risikenkatalog für KI-Anwendungen unter der Nummer LLM01:2025 geführte Angriffsmethode. Das Prinzip: Wenn ein Agent auch nur lesenden Zugriff auf externe Daten hat, Webseiten, E-Mails, fremde Notizen, geteilte Dokumente, kann ein Angreifer dort Anweisungen verstecken, die der Agent fälschlicherweise als Befehle interpretiert. Aus einer harmlosen Markdown-Datei, die jemand per E-Mail in den Inbox-Ordner geschickt hat, wird so unter Umständen ein Befehl, der den Agenten dazu bringt, einen Passwort-Ordner einzulesen und auszuleiten. Selbst die OpenClaw-Dokumentation sagt unverblümt: Prompt Injection ist nicht gelöst. System-Prompts sind weiche Leitplanken. Harte Sicherheit kommt nur über Sandbox-Mechanismen, Berechtigungs-Allowlists und sauber konfigurierte Container.
Und es gibt ein viertes, OpenClaw-spezifisches Thema, das in den Marketing-Texten gern verschwiegen wird: die Skills selbst. OpenClaw lebt von einem Marktplatz namens ClawHub, über den sich Erweiterungen installieren lassen, der Obsidian-Skill ist nur einer von Dutzenden. Jeder dieser Skills ist im Wesentlichen ein kleines Stück Software, das im Namen des Agenten Aktionen ausführen darf. Wer einen Skill aus einer wenig bekannten Quelle installiert, gibt dieser Quelle effektiv Vollzugriff auf den Workspace seines Bots. Eine Faustregel der OpenClaw-Community: Nur signierte Skills aus dem offiziellen Repository, niemals fremde Executables ohne Code-Review.
Die Goldene Regel, und warum sie unbestechlich ist
Aus all dem ergibt sich eine einzige Faustregel, die so robust ist, dass sie auf einem Aufkleber Platz hätte: Nie direkt mit einem autonomen Agenten auf dem einzigen Original-Vault starten. Erst Kopie. Dann Git. Dann kleine Schreibbereiche. Dann kontrollierte Automatisierung.
Was das in der Praxis bedeutet, folgt weiter unten als konkrete Checkliste. Kurz zusammengefasst: kopieren, versionieren, erst lesen lassen, dann in einem klar abgegrenzten Ordner schreiben lassen, dann erst skalieren. Es klingt umständlich. Es ist auch der Unterschied zwischen einem System, das einem über Jahre dient, und einem Wochenend-Experiment, das die mühsam aufgebaute Wissensbasis in dreißig Sekunden korrumpiert.
Ein Wort zu den Kosten
Bei Cloud-basierten Setups (Claude Cowork, Claude Code) sind die Kosten kalkulierbar. Etwa zwanzig Euro Abonnement pro Monat, fertig.
Bei OpenClaw wird es interessanter, und gefährlicher. Ein Always-on-Agent, der ständig läuft und auf jede Anfrage reagiert, kann Token verbrauchen wie ein Kachelofen Holz. Ein Token ist die Recheneinheit, in der KI-Anbieter abrechnen, grob gesprochen ein Wortstück, manchmal eine Silbe. Und wenn ein Agent in eine Schleife gerät, eine fehlerhafte Wiederholung, oder einen sehr breiten Rechercheauftrag bekommt, dann zählen diese Token sich erstaunlich schnell zu erstaunlich großen Summen zusammen.
Wer einen Always-on-Agenten betreibt, braucht deshalb harte Grenzen: Tagesbudgets pro API-Schlüssel, Rate Limits, automatische Alarmierung bei Schwellwert-Überschreitung. Wer das nicht einrichtet, baut sich eine Falle. Es gibt dokumentierte Fälle, in denen außer Kontrolle geratene Agenten innerhalb eines Monats fünf- bis sechsstellige Dollar-Beträge verbraucht haben, die meisten davon hätten sich mit drei Klicks vermeiden lassen.
Wer das nicht braucht
So begeisternd die Möglichkeiten klingen, so klar lohnt sich der Hinweis: Nicht jeder profitiert davon. Wer nur fünfzig Notizen hat, wer Obsidian gar nicht regelmäßig benutzt, wer keine Lust hat, Backups einzurichten oder gelegentlich auf einen Diff zu schauen, der baut sich mit einem KI-gestützten Second Brain keinen Helfer, sondern eine zweite Hausarbeit.
Und wer mit hochsensiblen Berufsgeheimnissen umgeht, Anwaltskanzleien, Arztpraxen, Steuerberatungen, Therapeuten, und nicht bereit ist, in ein vollständig lokales Setup zu investieren (also ein KI-Modell, das auf der eigenen Hardware läuft, ohne dass jemals Daten die Wohnung verlassen), sollte ehrlich zu sich sein: Die einfachen Cloud-Wege sind dann keine Option. Punkt.
Auch der umgekehrte Fall ist real: Wer eine fertige Software erwartet, die man einmal installiert und die dann „funktioniert“, für den sind weder Claude Cowork noch Claude Code noch OpenClaw das richtige Werkzeug. Alle drei sind Baukästen, keine fertigen Lösungen. Sie belohnen den, der sich Zeit nimmt. Sie bestrafen den, der nichts einrichten will.
Mark, drei Monate später
Mark, dessen Sprachnachricht aus dem Mannheimer Hauptbahnhof diesen Artikel eröffnet hat, hat sein Setup mittlerweile seit etwas mehr als einem halben Jahr laufen. Er nutzt OpenClaw auf einem kleinen Synology-NAS in seinem Keller, dasselbe Gerät, das bei ihm sowieso die Familienfotos sichert. Sein Bot ist über Telegram erreichbar, ein paar engste Mitarbeiter haben ebenfalls Zugriff. Der KI-Anbieter im Hintergrund ist Claude, mit getrennten API-Schlüsseln für sensible und nicht-sensible Anfragen.
Was hat sich verändert? Mark sagt, am meisten überrascht habe ihn die Reibung, die wegfällt. Er denkt nicht mehr darüber nach, ob er eine Idee jetzt aufschreiben soll oder später. Er schickt sie weg. Er muss nicht mehr alle paar Wochen seinen Vault aufräumen, das macht der Bot in seinem Auftrag, mit nachvollziehbaren Vorschlägen, die Mark jeden Sonntagvormittag in fünf Minuten durchklickt. Und er hat zum ersten Mal das Gefühl, dass sein eigenes Wissen ihm zur Verfügung steht, nicht nur als loser Haufen von Dateien, sondern als etwas, mit dem er reden kann.
Zwei Dinge ärgern ihn auch. Erstens: Drei Mal in den letzten Monaten hat der Bot Unsinn gebaut. Einmal hat er einen Ordner umstrukturiert, ohne dass Mark das wollte, Git hat den Schaden in vierzig Sekunden behoben. Einmal hat er eine Notiz dupliziert, statt sie zu verschieben. Einmal hat er einen Wikilink so missverstanden, dass er auf eine neu erstellte, leere Notiz zeigte. Alles reparabel, alles ohne Datenverlust. Aber nichts davon hätte er ohne Backups und Versionskontrolle so entspannt zur Kenntnis nehmen können.
Und zweitens: Er denkt manchmal über die Frage nach, die diesen Artikel zu seinem Ende führen soll.
Erste Schritte für Leser
Wer Lust hat, das Ganze selbst auszuprobieren, kommt mit sechs simplen Vorkehrungen erstaunlich weit. Sie wirken nach Vorsichtsmaßnahmen, sind aber in der Praxis die Differenz zwischen einem System, das einem über Jahre dient, und einem Wochenend-Experiment, das den Vault in dreißig Sekunden korrumpiert.
- Vault kopieren. Auf gar keinen Fall mit dem KI-Agenten direkt auf dem Original-Vault anfangen, eine Kopie reicht für die ersten Wochen.
- Git aktivieren. Im Vault-Ordner einmal
git initausführen, einen ersten Commit anlegen. Damit ist jede spätere KI-Änderung zeilengenau nachvollziehbar und rückgängig machbar. - Secrets scannen. Mit Tools wie
gitleaksodertrufflehogeinmal den Vault durchsuchen, bevor irgendeine KI Zugriff bekommt. Vergessene API-Schlüssel und Recovery-Codes in Notizen sind häufiger, als man denkt. - Erst nur Leserechte. Den Agenten in der ersten Woche ausschließlich analysieren lassen. Vorschläge erzeugen, nicht ausführen.
- Testordner einrichten. Einen Unterordner wie
/AI-Vorschlägeanlegen. Hier, und nur hier, darf der Agent in den ersten Wochen tatsächlich schreiben. Alles andere bleibt unangetastet. - Budgetlimits setzen. Im Anbieter-Dashboard (Anthropic, OpenAI) ein Tageslimit konfigurieren. Bei OpenClaw zusätzlich Rate Limits im Gateway und eine Alarmierung bei Schwellwert-Überschreitung. Außer Kontrolle geratene Agenten haben in dokumentierten Fällen fünf- bis sechsstellige Beträge in einem Monat verbraucht, die meisten davon vermeidbar mit drei Klicks.
Wer diese sechs Punkte abhakt, hat die häufigsten Stolperfallen umgangen. Was danach kommt, die spezifische Einrichtung von Cowork, Claude Code oder OpenClaw, ist Fleißarbeit, kein Hexenwerk.
Wenn die Technik aber einmal steht, bleibt die eigentlich spannendere Frage: Was verändert sich, wenn das eigene Archiv nicht mehr nur speichert, sondern antwortet?
Was ist eigentlich, wenn die Erinnerung antwortet?
Eine Notiz hat traditionell eine klare Rolle. Sie wartet. Sie liegt da, bis jemand sie wieder aufschlägt. Sie ist das passive Element in einem Gespräch, das nur in einer Richtung verläuft, vom Menschen zur Notiz.
Was sich gerade verändert, ist diese Asymmetrie. Notizen, die in einem KI-gestützten Vault leben, sind keine passiven Speicher mehr. Sie sind durchsuchbar in einem Sinne, der über Volltextsuche hinausgeht. Sie sind verlinkbar mit Bedeutungen, die nirgendwo wörtlich stehen. Sie sind kombinierbar zu Antworten, die man selbst so vielleicht nie formuliert hätte. Das eigene aufgeschriebene Wissen verwandelt sich, mit einem KI-Layer obendrauf, von einer Bibliothek in einen Gesprächspartner.
Das hat einen praktischen Nutzen, der unbestreitbar ist. Es hat aber auch eine kleine philosophische Pointe. Wenn die eigene Notizensammlung anfängt, einem Antworten zu geben, Antworten, die zur eigenen Denkweise passen, weil sie aus den eigenen Notizen synthetisiert sind, wo verläuft dann eigentlich noch die Grenze zwischen dem, was man weiß, und dem, was man nachschlägt? Zwischen dem eigenen Gedanken und dem, was die KI aus früheren eigenen Gedanken neu zusammensetzt?
Mark, im Heizungskeller, hat darauf keine Antwort. Er hat aber bemerkt, dass er an manchen Abenden, wenn ihm eine knifflige Entscheidung vor der Brust liegt, gar nicht mehr in den Vault schaut. Er fragt seinen Bot. Und der Bot zitiert ihm seine eigenen früheren Überlegungen zurück, manchmal genau die, die er gerade vergessen hatte. Es fühlt sich, sagt Mark, ein bisschen so an, als würde er einen sehr aufmerksamen, sehr geduldigen früheren Ich treffen.
Ob das das zweite Gehirn ist, das die Personal-Knowledge-Management-Szene seit Jahren beschwört, weiß er nicht. Aber er weiß, dass er den Wäschetrockner mittlerweile in einen anderen Raum gestellt hat. Sein Heizungskeller, sagt er, ist jetzt ein Arbeitszimmer.
Wer mehr über die technischen Details, Datenklassifikation, Git-Setup, Vault-Konventionen oder die konkreten Sicherheitsmaßnahmen, wissen möchte, findet in den Folgeartikeln auf foundic.org eine Vertiefung in vier Schritten: Strategie, Sicherheit, Praxis und Self-Hosting.