
Wie Maschinen sprechen, singen und uns nahekommen lernten mit KI-Audio.
Der Song, den niemand gesungen hat
Es war Mitte April 2023, kurz nach Ostern, als auf TikTok ein Track die Runde machte, der wie ein gemeinsamer Song von Drake und The Weeknd klang. Die Stimme ungeschminkt, der Beat seidig, das Songwriting routiniert, alles, was man von einem unangekündigten Feature der beiden Superstars erwarten würde. Innerhalb von 24 Stunden über eine Million Aufrufe. Auf Spotify ähnlich. Hörer schrieben begeistert in die Kommentare, dass das endlich mal wieder ein guter Drake sei.
Nur: Weder Drake noch The Weeknd hatten je einen Ton dazu gesungen. Der Track, bereits am 4. April auf Streaming-Diensten erschienen, ab dem 15. April als TikTok-Snippet viral, stammte von einem anonymen Nutzer namens Ghostwriter977. „Heart on My Sleeve“ war komplett mit KI erzeugt: Stimmen, Lyrics, Produktion. Universal Music Group ließ den Song am 17. April über DMCA-Takedown-Notices von den Plattformen entfernen, interessanterweise mit der Begründung, dass Ghostwriter977 in der Aufnahme einen Metro-Boomin-Producer-Tag (eine kurze Audio-Signatur, die UMG tatsächlich gehörte) eingebaut hatte. Da war es zu spät. Die Tonspur war kopiert, weiterverbreitet, in Reaction-Videos eingebettet, auf Servern dupliziert. Wer den Song hören wollte, konnte ihn hören. Und das Vertrauen in die Echtheit von Aufnahmen war für immer verschoben.
Neun Monate später, am 21. Januar 2024, in New Hampshire: Tausende Wähler erhalten einen Anruf. Joe Bidens Stimme, vertraut aus tausend Reden, fordert sie auf, der demokratischen Vorwahl fernzubleiben. Forensische Analysten von Pindrop und Hany Farid (UC Berkeley) brauchten weniger als eine Woche, um zu bestätigen, was viele schon ahnten: Die Stimme war mit ElevenLabs erzeugt, einem KI-Werkzeug, das damals jeder mit einer Kreditkarte für ein paar Dollar nutzen konnte. Der Initiator wurde später belangt. Aber der eigentliche Punkt blieb: Stimmen, die wir aus dem Fernsehen kennen, lassen sich in Sekunden klonen. Für den Preis eines Cappuccinos.
Diese beiden Momente der Drake-Song und der Biden-Anruf sind die kulturellen Klammern dieser Geschichte. Dazwischen entfaltet sich die rasanteste audiovisuelle Umwälzung seit der Erfindung des MP3. Und sie betrifft uns intimer, als die Bilderflut der vergangenen Jahre uns je betroffen hat. Eine Stimme ist näher an der Identität als jedes Foto. Musik ist näher an der Erinnerung als jedes Bild. Geräusch ist näher an der Anwesenheit als jedes Video. Und alle drei sind seit Anfang 2022 in einem Tempo generierbar geworden, das niemand vorhergesehen hat auch nicht die, die daran gearbeitet haben.

Warum dieser Artikel sein muss
Wer heute mit ChatGPT redet, statt zu tippen, ein Lied auf Suno generiert, einen englischen Brand-Spot in 30 Sprachen lokalisieren lässt oder eine Voicemail von einem Menschen bekommt, der dieser Mensch eigentlich gar nicht ist — der bewegt sich in einer akustischen Welt, die es vor vier Jahren noch nicht gab.
Bilder sehen wir an. Klänge gehen direkt durch uns durch.
Dieser Artikel zeichnet vier Jahre nach: 2022 bis 2026. Er erklärt, was technisch passiert ist, was rechtlich gerade verhandelt wird, welche Werkzeuge man heute kennen sollte und welche Fragen offen bleiben. Vor allem aber will er etwas bewahren, das in der Tech-Berichterstattung oft verlorengeht: die Aufmerksamkeit dafür, dass eine Stimme intimer wirkt als jedes Bild und dass diese Intimität gerade neu verhandelt wird.
Audio war schon immer ein Computertraum
Bevor wir 2022 betreten, ein kurzer Schritt zurück. Computerstimmen sind keine Erfindung des KI-Zeitalters. Schon 1939 baute Homer Dudley in den Bell Labs den Voder — eine elektronische Sprechmaschine, die ein Mensch wie ein Akkordeon „bediente“, um Worte zu formen. 1961 sang ein IBM 7094 „Daisy Bell“ ein historisches Tondokument, das Stanley Kubrick sieben Jahre später in 2001: A Space Odyssey als HALs Sterbeszene zitierte. Lejaren Hiller komponierte 1957 mit der Illiac Suite for String Quartet das erste vollständig algorithmisch erzeugte Musikstück.
In den 2010er-Jahren beschleunigte sich das Tempo. WaveNet von DeepMind (2016) zeigte, dass neuronale Netze rohe Audio-Wellenformen Sample für Sample erzeugen können. Tacotron 2 (Google, 2017) machte Text-to-Speech für Endprodukte tauglich. OpenAI Jukebox (2020) erzeugte erstmals ganze Songs im Stil bekannter Künstler rauschig, langsam, kaum kontrollierbar, aber vorhanden. Und 2021/22 kamen die unscheinbaren, aber entscheidenden Bausteine: SoundStream (Google) und EnCodec (Meta), neuronale Audio-Codecs, die Klang in diskrete Token (kleine, durchnummerierte Bausteine, die ein Sprachmodell verarbeiten kann) verwandelten.
Das war die stille Revolution. Denn wenn Audio plötzlich aussieht wie Text also wie eine Folge von Token, dann lassen sich Sprachmodelle, die für Text gebaut wurden, auf Audio anwenden. Der Rest der Geschichte ist die Konsequenz dieser einen Einsicht.
Was 2022 begann, ist also nicht die Erfindung künstlichen Klangs. Es ist der Moment, in dem künstlicher Klang von Menschen nicht mehr unterscheidbar wurde.
2022: Maschinen lernen zuzuhören
Die Geschichte beginnt mit einem Werkzeug, das die meisten gar nicht als KI wahrnehmen. Am 21. September 2022 veröffentlichte OpenAI Whisper ein Spracherkennungsmodell, das auf 680.000 Stunden Audio aus 99 Sprachen trainiert wurde, dazu unter MIT-Lizenz freigegeben (also weitgehend frei nutzbar). Whisper war keine Demo. Es war kostenlos, lokal lauffähig, und die Word Error Rate (also der Anteil falsch erkannter Wörter) halbierte sich gegenüber kommerziellen Vorgängern. Plötzlich konnte jeder Entwickler einer App eine Transkriptions-Funktion einbauen, die so gut war wie das, wofür Konzerne vorher fünfstellige Lizenzgebühren zahlten.
Whisper wurde zum unsichtbaren Rückgrat einer ganzen Generation von Produkten Otter.ai, Descript, Fireflies und Tausende mehr. Heute, in der Version large-v3, ist Whisper auf Hugging Face mit über vier Millionen monatlichen Downloads die offene Referenz für Spracherkennung. Wer ein Meeting transkribieren lässt, einen Podcast automatisch untertitelt oder seine Voice Memos durchsuchbar macht, nutzt mit hoher Wahrscheinlichkeit Whisper auch wenn das Produkt anders heißt.
Die zweite große Veröffentlichung kam im Dezember 2022, etwas leiser. Zwei Hobby-Entwickler trainierten Stable Diffusion das Bild-KI-Modell, das damals gerade die Welt eroberte nicht auf Fotos, sondern auf Spektrogrammen (visuelle Frequenz-Repräsentationen von Audio). Was dabei herauskam, Riffusion, war konzeptionell ein Erweckungserlebnis: Audio ist Bild, Bild ist Diffusion, Diffusion ist Musik. Was als Hack begann, ist heute ein etabliertes Produkt mit eigener App und Millionen Nutzern.
Aber Whisper hat auch eine Schattenseite, die heute zu wenig diskutiert wird. Mehrere Studien eine über 100 Stunden Transkripte, eine andere über 26.000 kürzere Clips fanden Halluzinationen in „nahezu jeder“ Aufnahme bzw. 1,4 Prozent aller Segmente. Davon waren laut der Forscher 38 Prozent „potenziell schädlich“ also etwa frei erfundene medizinische Begriffe oder Zuschreibungen rassistischer Aussagen, die nie gefallen waren. In einem Podcast spielt das keine große Rolle. In einer Patientenakte oder einem Gerichtsprotokoll schon.
2022 war also das Jahr, in dem Sprache endgültig maschinenlesbar wurde durchsuchbar, archivierbar, analysierbar. Und das Jahr, in dem die ersten Risse sichtbar wurden, die in den Folgejahren zu Brüchen wachsen sollten.
2023: Stimme und Musik werden generativ
Wenn 2022 das Jahr des Zuhörens war, dann war Januar 2023 der dichteste Monat in der Geschichte der Audio-KI. Drei Veröffentlichungen innerhalb weniger Wochen verschoben die Tektonik:
Am 5. Januar stellte Microsoft VALL-E vor. Das Modell konnte aus drei Sekunden Audio einer beliebigen Stimme einen kompletten Sprechmodus klonen Tonfall, Akzent, Sprechtempo. Trainiert auf 60.000 Stunden Meta-LibriLight-Daten. Microsoft veröffentlichte das Modell nicht. Zu groß war das Missbrauchsrisiko. Aber das Forschungspapier reichte, um zu zeigen: Voice Cloning ist kein Science-Fiction-Problem mehr, sondern eine Frage der Werkzeugverfügbarkeit.
Am 26. Januar zeigte Google MusicLM: Aus einem Prompt wie „a calming violin melody backed by a distorted guitar riff“ entstand ein hörbarer Track, trainiert auf 280.000 Stunden Audio. Wegen Copyright-Bedenken sperrte Google den öffentlichen Zugang zunächst erst im Mai 2023 wurde MusicLM in der „AI Test Kitchen“ verfügbar.
Und im Januar startete in Warschau ein kleines Startup namens ElevenLabs seine Beta. Die Gründer Mati Staniszewski (zuvor bei Palantir) und Piotr Dąbkowski (zuvor bei Google) hatten 2 Millionen Dollar Pre-Seed-Kapital eingesammelt und ein Modell gebaut, das natürliche Pausen, Lacher, sogar Atemgeräusche erzeugen konnte. Bis Juni 2023 hatte ElevenLabs über eine Million Nutzer.
Der eigentliche Lakmustest kam dann zwei Wochen später. „Heart on My Sleeve“ der Drake/Weeknd-Imitator von Ghostwriter977. Universal Music Group reagierte schnell mit Takedown-Notices über den Producer-Tag-Trick. Aber die kulturelle Wirkung war nicht mehr rückgängig zu machen. Im Herbst 2023 reichte Ghostwriter977 den Song sogar bei der Recording Academy zur Grammy-Nominierung ein Academy-CEO Harvey Mason Jr. erklärte den Track zunächst tatsächlich für berechtigt, weil er kommerziell veröffentlicht worden war, bevor die Nominierung wegen der nicht geklärten Persönlichkeitsrechte zurückgezogen wurde. Zum ersten Mal stellte sich für Millionen Menschen die Frage, was es bedeutet, wenn die Stimme eines lebenden Künstlers ohne sein Wissen und ohne sein Einverständnis in einem neuen Werk auftaucht und ob ein solches Werk Schutz genießt, künstlerische Berechtigung hat oder schlicht Diebstahl ist. Die Antwort wird bis heute verhandelt.
Der Rest des Jahres war eine Welle. Im Juni 2023 brachte Meta MusicGen als Open-Source-Antwort auf MusicLM heraus. Im September 2023 veröffentlichte Stability AI Stable Audio 1.0 das erste kommerziell tragfähige Musikmodell mit 44,1-kHz-Auflösung (also CD-Qualität).
Und im November 2023 geschah etwas Bemerkenswertes: Die Beatles veröffentlichten „Now and Then“ den letzten Beatles-Song. Möglich gemacht hatte das ein Machine-Learning-Tool, das Peter Jackson für seinen Dokumentarfilm Get Back entwickelt hatte. Es konnte John Lennons Stimme aus einem 1979 auf Cassette mitgeschnittenen, akustisch fast unbrauchbaren Demo isolieren. Producer Giles Martin beschrieb es so: Die Maschine erkennt die Stimme einer bestimmten Person und filtert alles andere weg. Das Ergebnis ist nicht synthetisch, sondern restauriert. Lennons echte Stimme. Aus einer schlechten Aufnahme.
„Now and Then“ und „Heart on My Sleeve“ markieren die zwei Pole, zwischen denen sich die Audio-KI-Diskussion seither bewegt. Beide nutzen KI, um die Stimmen verstorbener oder nicht beteiligter Menschen wieder hörbar zu machen. Der eine Fall geschah mit Einverständnis, mit den Originalaufnahmen, mit klarer künstlerischer Intention. Der andere ohne all das. Was rechtlich, was ethisch, was kulturell akzeptabel ist, hängt nicht von der Technologie ab sondern von den Verhältnissen, in denen sie genutzt wird.
2024: Audio-KI wird Massenprodukt
2024 war das Jahr, in dem Audio-KI aus den Forschungslabors in die Hosentaschen sprang. Drei Werkzeuge prägten dieses Jahr.
Suno V3 erschien im März 2024. Bis dahin waren KI-Songs erkennbar gewesen manchmal an einer leblosen Vocal-Spur, manchmal an einer holprigen Songstruktur. V3 war anders. Aus einem schlichten Prompt entstand ein vollständig produzierter Song: Strophe, Refrain, Bridge, eingängige Melodie, überzeugende Stimme. Bis Mai 2024 hatte Suno laut eigener Aussage zehn Millionen Nutzer. Im Februar 2026 berichteten Suno CEO Mikey Shulman auf LinkedIn und das Marktforschungsunternehmen Sacra zwei Millionen zahlende Abonnenten und 300 Millionen Dollar Annual Recurring Revenue bei kumuliert über zehn Millionen Nutzern. Im Investoren-Pitch-Deck zur Series-C-Runde im November 2025 nannte Suno außerdem eine bemerkenswerte Zahl: rund sieben Millionen Tracks werden auf der Plattform pro Tag erzeugt.
Udio startete am 10. April 2024. Hinter dem Tool standen vier ehemalige Forscher von Google DeepMind, finanziert mit 10 Millionen Dollar Seed-Kapital von Andreessen Horowitz, will.i.am, Common und Mike Krieger (Mitgründer von Instagram). Udio wirkte musikalisch nuancierter als Suno, mit etwas mehr instrumentaler Tiefe was Geschmacksfrage ist, aber für viele Profis den Ausschlag gab.
Im Mai 2024 dann ein Moment, der die Absurdität der neuen Verhältnisse zeigte: Mitten im legendären Beef zwischen Drake und Kendrick Lamar schrieb der Comedian Willonius Hatcher ein paar Zeilen, jagte sie durch Udio und heraus kam „BBL Drizzy„, ein Motown-Pastiche, das Drake auf eine Weise verspottete, wie es kein menschlicher Songwriter so schnell hätte machen können. Wenige Tage später samplete der Star-Produzent Metro Boomin den Track auf seinem Instagram, lobte 10.000 Dollar für den besten Remix aus, und schließlich landete das Sample sogar auf Drakes eigenem Track „U My Everything“ mit Sexyy Red.
Es war der erste Fall, in dem ein vollständig KI-generiertes Sample legal in einem Major-Release einer der größten Künstler der Welt landete. Möglich war das aus einem Grund, der die kommende Lizenzdebatte vorwegnimmt: Nach der aktuellen Linie des U.S. Copyright Office sind rein maschinell erzeugte Bestandteile ohne menschliche schöpferische Kontrolle nicht urheberrechtlich schutzfähig menschliche Beiträge wie Lyrics, Auswahl, Arrangement oder Bearbeitung dagegen schon. Hatcher, der die Lyrics geschrieben hatte, behielt also seine Rechte am Text und wurde so zum ersten Künstler, der einen KI-Sample-Major-Deal lizenzierte. Der Beat war in den USA gemeinfrei verwendbar, weil maschinell erzeugt die Lyrics darüber waren es nicht.
Und dann, am 13. Mai 2024, der Skandal, der die KI-Branche bis heute verfolgt. OpenAI stellte GPT-4o vor — ein neues Multimodal-Modell, das in einer Live-Demo natürlich, schnell, mit Witz und musikalischen Talenten sprach. Eine der Stimmen hieß „Sky„. Sie klang erstaunlich ähnlich wie Scarlett Johansson in dem Film Her von Spike Jonze (2013), in dem Johansson eine Sprach-KI namens Samantha vertonte. Sam Altman twitterte am selben Tag schlicht: „her“. Das Internet machte sich seinen Reim.
Scarlett Johansson hatte das Angebot, eine Stimme für GPT-4o zu sprechen, zuvor abgelehnt zweimal. Ihre Anwälte kontaktierten OpenAI. Am 19. Mai 2024, sechs Tage nach der Demo, deaktivierte OpenAI „Sky“. Das Unternehmen behauptet bis heute, dass eine andere, real existierende Sprecherin ihre eigene natürliche Stimme verwendet habe eine Stimme, die Johanssons eben „zufällig“ ähnele. Da OpenAI die Identität der Sprecherin schützt, lässt sich das öffentlich nicht endgültig klären.
Was sich klären lässt: Der Sky-Vorfall war der Moment, in dem die Frage nach Persönlichkeitsrechten an einer Stimmlage im Mainstream ankam. Wenn eine Stimme einer berühmten Stimme zum Verwechseln ähnelt gehört diese Ähnlichkeit dem Original? Tennessee verabschiedete sechs Wochen später, am 1. Juli 2024, den ELVIS Act die erste US-Gesetzgebung, die „Voice“ explizit als Persönlichkeitsrecht definiert, inklusive einer „Simulation“ der Stimme einer Person.
Sechs Wochen nach dem Sky-Vorfall, am 24. Juni 2024, eröffnete die RIAA (der amerikanische Verband der Plattenindustrie) eine zweite juristische Front. Sony Music, Universal Music Group und Warner Music Group verklagten Suno und Udio gemeinsam wegen Urheberrechtsverletzung. Die Klage zitierte verblüffende Beispiele: Suno-generierte Tracks ähnelten James Browns „I Got You (I Feel Good)“, Chuck Berrys „Johnny B. Goode“ und Mariah Careys „All I Want For Christmas Is You“ derart deutlich, dass die Major-Labels argumentierten, die Modelle müssten auf urheberrechtlich geschützten Aufnahmen trainiert worden sein. Schadensersatzforderung: 150.000 Dollar pro Werk.
2024 war damit auch das Jahr, in dem aus Audio-KI ein Werkzeug für alle wurde und gleichzeitig ein Gerichtsfall.
2025: Voice Agents werden präsent, Lizenzkriege werden geführt
Wenn 2024 die Tools in die Hosentaschen brachte, dann brachte 2025 die Konsequenzen. Auf zwei Bühnen gleichzeitig: technisch wurde die Stimme zur Schnittstelle, juristisch zum Streitfall.
Bisher hatten KI-Stimmen vor allem vorgelesen Hörbücher, Voiceovers, Werbespots. Sie waren gut, aber sie waren Lautsprecher. Im Februar 2025 stellte ein bis dahin unbekanntes Startup namens Sesame zwei Voice-Companions vor: Maya und Miles. Was sie konnten, war neu.
Maya machte Pausen. Miles atmete. Beide sagten „ähm“. Beide ließen sich unterbrechen. Und beide reagierten in Echtzeit, mit einer Gesprächsdynamik, die nicht mehr nach „Antwortmaschine“ klang, sondern nach Gegenüber. Sesame nannte das Konzept dahinter „Voice Presence“ also nicht „bessere Klangqualität“, sondern das Gefühl, mit einer präsenten, reagierenden Stimme zu sprechen. Innerhalb der ersten Wochen unterhielten sich über eine Million Menschen kumuliert mehr als fünf Millionen Minuten lang mit Maya und Miles. Im März 2025 stellte Sesame das zugrundeliegende Conversational Speech Model (CSM-1B) unter Apache-2.0-Lizenz quelloffen ins Netz. Im Oktober folgte eine 250-Millionen-Dollar-Finanzierungsrunde unter Führung von Sequoia.
Auch OpenAI legte 2025 nach. Im Juni brachte ElevenLabs sein v3-Modell in die Alpha-Phase mit Unterstützung für 70 Sprachen, mehreren Sprechern in einem Dialog und sogenannten Audio Tags wie [whispers], [excited], [sighs], [laughing]. Wer eine Voice-KI dazu bringen wollte, vor einer entscheidenden Zeile leise zu flüstern, konnte das jetzt direkt im Prompt steuern. Im August 2025 folgte mit gpt-realtime OpenAIs eigene Antwort: ein Voice-Modell, das in Big-Bench-Audio-Benchmarks von 65,6 Prozent Genauigkeit auf 82,8 Prozent sprang, mit Unterstützung für Tools, Bildverarbeitung in Voice-Sessions und sogar SIP-Telefonie (also direkter Anbindung an klassische Telefonleitungen).
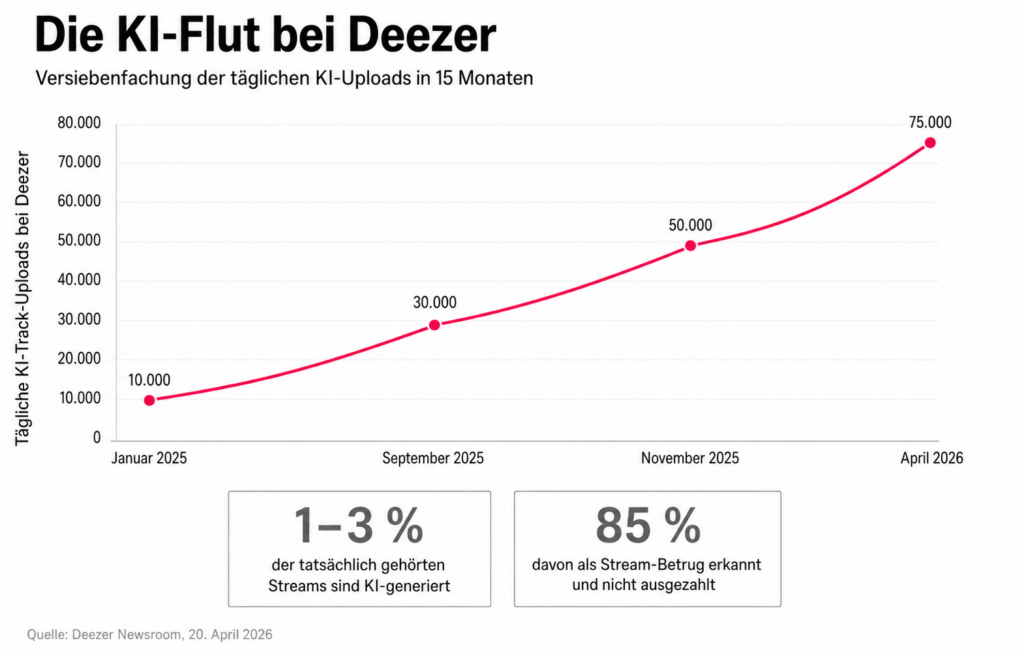
Auf der Musik-Seite passierte 2025 dreierlei gleichzeitig. Erstens: Die Tools wurden besser. Suno veröffentlichte im September 2025 sein v5-Modell und kurz darauf Suno Studio die erste „generative audio workstation“ der Welt, also ein Werkzeug, das Songs nicht nur erzeugt, sondern auch fein editierbar macht. Zweitens: Die Plattformen mussten reagieren. Spotify verkündete am 25. September 2025, dass es in den vergangenen zwölf Monaten 75 Millionen Spam-Tracks gelöscht habe viele davon KI-generiert. Deezer meldete am 20. April 2026 eine Zahl, die in der Branche eingeschlagen hat: 44 Prozent aller täglichen Uploads sind inzwischen KI-Material — etwa 75.000 Tracks pro Tag, mehr als zwei Millionen pro Monat. Im Januar 2025, als Deezer sein KI-Erkennungs-Tool startete, waren es noch 10.000 pro Tag. Eine Versiebenfachung in 15 Monaten.
Bemerkenswert ist die zweite Zahl, die Deezer mitlieferte: Trotz dieser Schwemme machen KI-Tracks nur ein bis drei Prozent aller tatsächlich gehörten Streams aus. Davon werden laut Deezer 85 Prozent als betrügerische Streams (also künstlich aufgeblähte Abrufzahlen, vermutlich mit Bots) erkannt und nicht ausgezahlt. Das heißt: Die KI-Flut speist sich offenbar nicht aus Hörerinteresse, sondern aus dem Versuch, Royalty-Pools auszubeuten also die Tantiemen-Töpfe, aus denen Streaming-Dienste ihre Künstler bezahlen. Was wie ein kreatives Phänomen aussieht, ist über weite Strecken ein automatisierter Betrugsversuch.
Drittens, und das war juristisch das wichtigste: Die ersten Vergleiche wurden geschlossen. Im Oktober 2025 einigte sich Universal Music Group mit Udio auf eine gemeinsam lizenzierte Plattform, deren Launch für Q2 2026 angekündigt ist. Im November 2025 folgte der Paukenschlag: Warner Music Group und Suno beendeten ihre Klage und kündigten stattdessen eine Partnerschaft für „next-generation licensed AI music“ an. Die finanziellen Konditionen wurden nicht offengelegt Suno übernahm im Zuge des Deals von Warner die Konzert-Discovery-Plattform Songkick. Sechs Tage zuvor hatte Suno seine Series-C-Runde mit 250 Millionen Dollar bei einer Bewertung von 2,45 Milliarden Dollar abgeschlossen. Zwischen Klage und Lizenzdeal lagen anderthalb Jahre.
Eine Geschichte, die das neue Geschäftsmodell auf den Punkt bringt: Telisha Jones, 31, aus Mississippi, verwandelte mit Suno eines ihrer Gedichte in den R&B-Song „How Was I Supposed to Know“ der Track ging viral, schaffte es in die Charts, und Jones unterschrieb daraufhin einen Plattenvertrag bei Hallwood Media. Der Deal wurde laut Berichten auf rund drei Millionen Dollar taxiert. Was vor drei Jahren noch Diebstahl gewesen wäre, ist heute der Karrierestart einer Songwriterin, die ohne KI nie ein Studio betreten hätte.
Sony allerdings klagt weiter. Ein erstes Urteil wird Mitte 2026 erwartet. Auch in Deutschland wurde es ernst: Die GEMA (die deutsche Verwertungsgesellschaft) reichte am 21. Januar 2025 Klage gegen Suno vor dem Landgericht München ein. Die Klage betrifft konkret die Werke „Forever Young“ (Alphaville), „Atemlos durch die Nacht“ (Kristina Bach), „Mambo No. 5″ (Lou Bega) und drei weitere. Das Urteil wird für den 12. Juni 2026 erwartet und es wird der Präzedenzfall für ganz Kontinentaleuropa sein.
Während die Großen klagen und vergleichen, ist parallel eine kleinere Bewegung entstanden: KI-Anbieter, die von Anfang an nur lizenziertes Trainingsmaterial nutzen. Im Januar 2024 gründete Ed Newton-Rex ehemaliger Stability-AI-Vize, der dort gekündigt hatte, weil er das Training auf urheberrechtlich geschütztem Material nicht mittragen wollte — die Non-Profit Fairly Trained. Sie zertifiziert Modelle, deren Trainingsdaten vollständig lizenziert sind, und vergibt das Licensed Model-Siegel; Universal Music Group unterstützt die Initiative offiziell. Zu den ersten zertifizierten Tools gehört Beatoven.ai, ein indisches Startup, das eine eigene Datenbank lizenzierter Musik aufgebaut hat und Komponisten an den Einnahmen beteiligt. Nicht das Modell der KI-Konzerne aber ein Modell. Eines, das die Branche in zwei Lager teilt und in der Mitte stehen Tools wie Suno und Udio, die gerade unter den Augen aller das Lager wechseln..
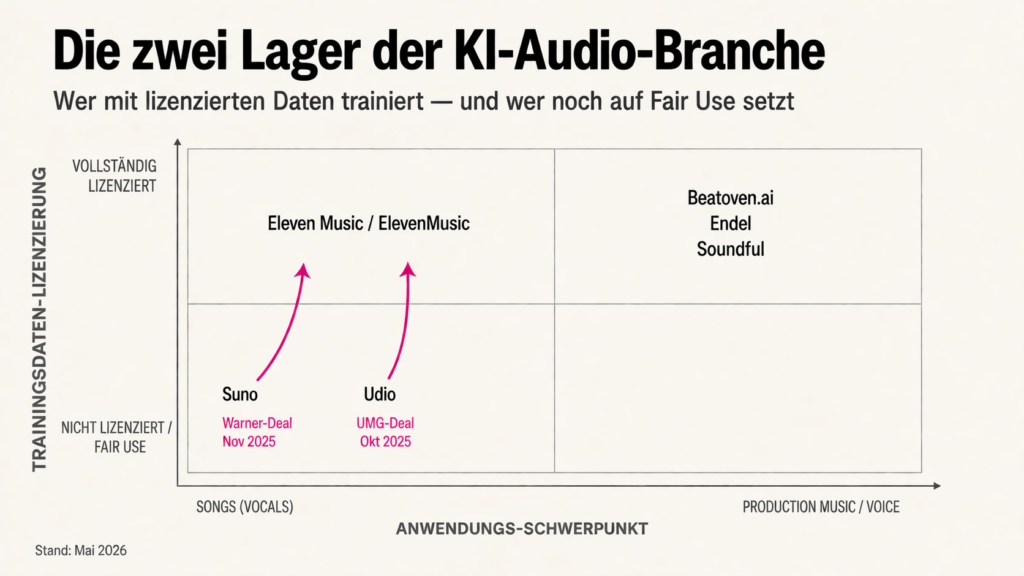
So lautete die Verschiebung 2025: nicht mehr „Kann KI Musik und Stimme erzeugen?“, sondern „Wer darf daran verdienen?“
2026: Audio wird Schnittstelle, Studio und Identitätsmaschine
Im Jahr, in dem dieser Artikel erscheint, hat sich die Szene konsolidiert. Die Werkzeuge sind reifer, die Geschäftsmodelle klarer, und die Regulierung wird zur greifbaren Realität.
Im März 2026 veröffentlichte Suno v5.5. Drei neue Features stehen im Zentrum: „Voices“ lässt eigene Stimmen als Persona einbinden also etwa die eigene Sprechstimme als Sänger eines Songs. „Custom Models“ erlaubt zahlenden Pro- und Premier-Nutzern bis zu drei eigene, fein-getunte Modelle, trainiert auf eigenen Tracks. Und „My Taste“ lernt automatisch Genre- und Mood-Vorlieben mit. Personalisierung ist die nächste Front.
Während Suno und Udio sich juristisch sortieren, baute ElevenLabs parallel eine lizenzbasierte Alternative auf. Am 5. August 2025 veröffentlichte das Unternehmen sein Musikmodell Eleven Music und gleichzeitig Trainingsdaten-Deals mit den Verwertungsgesellschaften Merlin (30.000 unabhängige Labels) und Kobalt (größter unabhängiger Music-Publisher). Zunächst zielte das Modell auf Geschäftskunden für Production Music, Werbung, Brand-Audio, Studio-Anwendungen. Am 29. April 2026 baute ElevenLabs das Angebot zur Streaming-, Remix- und Creator-Plattform ElevenMusic aus (das Unternehmen unterscheidet selbst sorgfältig: zwei Wörter für das Modell, ein Wort für die Plattform). Mit täglich neu generierten KI-Mixes Focus, Energy, Relax, Late Night, Cosmic, Chill und einem Pro-Tier von 9,99 Dollar im Monat für 500 Tracks. Eine direkte Ansage an Suno und Udio, mit einem entscheidenden Unterschied: ElevenMusic operiert von Anfang an in einem lizenzgesicherten Rahmen. Für Werbespots, Podcasts und Brand-Audio ist das ein erheblicher Vorteil.
Voice-Agents wachsen 2026 in den Geschäftsalltag hinein. Cartesia mit seinem Sonic-3-Modell schiebt die Latenz unter 100 Millisekunden das ist die Reaktionszeit, ab der wir Gespräche als wirklich flüssig empfinden. Damit werden Voice-Agents in der Telefonie ernsthaft konkurrenzfähig zu menschlichen Mitarbeitern. Hume AI spezialisiert sich auf emotionale Steuerung ihr EVI-3-Modell kann Empathie, Wärme oder professionelle Distanz feinjustiert ausgeben. Und Sesame bereitet die nächste Version seiner Voice-Companions in Kombination mit AR-Brillen vor.
Was 2026 von 2024 unterscheidet, ist nicht nur die technische Qualität. Es ist die regulatorische Realität. Am 2. August 2026 greifen in der EU die Transparenzpflichten aus Artikel 50 des AI Act. Für synthetische oder manipulierte Audioinhalte, insbesondere Deepfakes (also synthetische Audio- oder Videoaufnahmen, die echte Personen imitieren), werden Kennzeichnung und Offenlegung deutlich wichtiger. Der Code of Practice der EU AI Office, dessen finale Fassung im Juni 2026 erwartet wird, soll konkretisieren, wie genau diese Pflichten umzusetzen sind — etwa, ob bei Audio-Deepfakes ein gesprochener Disclaimer am Anfang reicht oder ob auch Mitte und Ende markiert werden müssen.
Wer ab August 2026 synthetische Stimmen oder geklonte Personenstimmen in einem deutschen Podcast einsetzt, sollte sehr genau prüfen, ob und wie dies offenzulegen ist. Wer eine geklonte Stimme in einem Werbespot ohne Einverständnis nutzt, riskiert ohnehin juristische Konsequenzen sowohl nach dem Tennessee ELVIS Act (für US-Künstler) als auch nach dem dänischen Digital-Likeness-Gesetz (das voraussichtlich 2026 in Kraft tritt und Stimme, Gesicht und Persönlichkeitsmerkmale bis 50 Jahre nach Tod schützt).
2026 ist Audio-KI nicht mehr nur Ausgabe. Sie wird zur Schnittstelle. Und gleichzeitig zur regulierten Industrie.
Drei kulturelle Verschiebungen, die bleiben werden
Hinter den Tools und Releases liegt eine kulturelle Tiefenschicht, die sich quer durch die Jahre zieht. Drei Bewegungen sind besonders sichtbar.
Die erste ist die Memeisierung von Stimme. „KI-Trump“, „KI-Biden“, „KI-Drake“ wurden zur Standardform politischer und popkultureller Satire. Auf TikTok kursieren bis heute Endlosschleifen, in denen Trump, Biden und Obama gemeinsam Minecraft spielen. Lionel Messi „spricht“ über HeyGen fließend Englisch ein Clip, den der argentinische Sportjournalist Javi Fernandez im September 2023 als Demo veröffentlichte. „BBL Drizzy“ wurde, wie schon erwähnt, zum ersten legalen KI-Sample im Major-Release eines globalen Stars. Die Imitation prominenter Stimmen ist im Jahr 2026 kein technisches Problem mehr. Sie ist ein juristisches und ethisches.
Die zweite Bewegung ist das, was die englischsprachige Presse „AI Resurrection“ nennt die akustische Wiederbelebung verstorbener oder stimmlich beeinträchtigter Künstler. „Now and Then“ der Beatles ist der saubere Pol: Lennons echte Stimme, ML-isoliert aus einer schlechten Aufnahme, mit Einverständnis aller Beteiligten. Die Suno-Kooperation mit dem Hip-Hop-Pionier The D.O.C., der seit einem Autounfall 1989 nicht mehr richtig sprechen kann und jetzt einen KI-rekonstruierten Voice-Clone seiner früheren Stimme nutzt, ist die graue Zone kommerziell, aber mit voller Zustimmung. Drakes Verwendung einer KI-Tupac-Stimme auf seinem Track „Taylor Made Freestyle“ im April 2024 wiederum war der kontroverse Pol: Die Tupac-Stiftung schickte umgehend eine Cease-and-Desist-Aufforderung. Drake nahm den Track aus dem Netz.
Hier kollidieren Trauerarbeit, kommerzielle Ausbeutung und persönlichkeitsrechtlicher Schutz. Die zentrale Frage der Audio-KI-Ethik lautet: Wer darf wessen Stimme imitieren und wann? Der Status der Person (lebt, tot, einwilligungsfähig)? Der Zweck (Kunst, Kommerz, Satire, Erpressung)? Der Kontext (Studio-Aufnahme, Demo, Erinnerungsstück)? Es gibt darauf keine einfachen Antworten aber die Antworten dürfen nicht der Software überlassen werden.
Die dritte Verschiebung ist ökonomisch und sie betrifft, wer mit Musik Geld verdient. Schon vor der KI-Welle hatte sich gezeigt, dass anonyme Hintergrundmusik Milliarden-Reichweite erreichen kann der Lofi Girl-Stream auf YouTube hat 14 Millionen Abonnenten und 1,9 Milliarden Aufrufe gesammelt. Seit 2025 wachsen ähnliche Kanäle mit komplett KI-generiertem Material exponentiell. Sogenannte „Faceless Music Channels“ produzieren 24/7 Lofi-, Synthwave- oder Ambient-Streams, gefüttert direkt aus Suno und visualisiert mit Tools wie Freebeat. Die schon erwähnten Deezer-Zahlen 44 Prozent KI-Uploads, davon 85 Prozent der Streams als Betrug entlarvt zeigen, dass diese Verschiebung längst keine künstlerische Bewegung mehr ist, sondern ein industrieller Versuch, automatisiert Tantiemen abzuzweigen.
Die Frage, vor der die Streaming-Industrie steht, ist nicht mehr, ob KI-Musik geduldet wird. Sondern, ob menschliche Künstler überhaupt noch ein wirtschaftlich tragfähiges Streaming-Modell haben. Die Antwort wird in den nächsten Jahren mit Lizenzdeals, Plattform-Filtern und politischen Vorgaben verhandelt werden und sie wird bestimmen, wie sich die Musikindustrie der 2030er Jahre aufstellt.
Praxis: Welche Werkzeuge man heute kennen sollte
Genug Theorie. Wer im Mai 2026 KI-Audio einsetzt, hat eine ausgereifte Auswahl. Hier eine kompakte Übersicht nach Anwendungsbereich sortiert.
Für Sprechstimmen, Voiceovers und Voice Cloning ist ElevenLabs unverändert die Referenz. Das Starter-Abo für 5 Dollar im Monat liefert kommerzielle Nutzungsrechte, 30.000 Credits (gut für ein paar Stunden Audio) und Voice Cloning. Wer mehrere Sprecher braucht, mehrsprachiges Dubbing oder emotional fein justierte Stimmen erzeugen will, findet in ElevenLabs eine professionelle Werkbank. Alternativ lohnt ein Blick auf Hume AI (besser für emotional besetzte Inhalte wie Therapie- oder Coaching-Apps) oder Cartesia (für Echtzeit-Telefonie mit minimaler Latenz).
Für Voice-Agents also KI-Stimmen, die in Dialogen reagieren statt Texte vorzulesen sind OpenAI gpt-realtime und Sesame die führenden Optionen. gpt-realtime ist über die OpenAI-API zugänglich, kostet je nach Nutzung 32 bis 64 Dollar pro Million Audio-Tokens und ist derzeit das technisch ausgereifteste Modell, vor allem dank seiner Werkzeug-Integration. Sesame wirkt menschlicher, präsenter ist aber noch in der Beta-Phase und für komplexe Geschäftsanwendungen weniger weit.
Für Transkription bleibt Whisper das Maß aller Dinge. Wer es lokal betreiben möchte (also auf dem eigenen Rechner, ohne Daten in die Cloud zu schicken), findet auf GitHub eine vollständige Open-Source-Implementierung. Wer Komfort schätzt, nutzt die OpenAI-API für 0,006 Dollar pro Minute. Für Enterprise-Anwendungen mit Diarization (also der automatischen Unterscheidung verschiedener Sprecher) und Echtzeit-Streaming sind Deepgram und AssemblyAI stärker sie kosten zwischen 0,4 und 1 Cent pro Minute, je nach Modell.
Im Bereich Musikgenerierung lohnt eine kurze Sortierung der Werkzeug-Logik, weil die Begriffe oft durcheinander laufen. Suno und Udio sind Songmaschinen sie erzeugen aus einem Prompt einen vollständigen Track mit Strophen, Refrain und Vocals. Stable Audio denkt in Soundtracks, Loops und Sounddesign also in Bausteinen, die in eine größere Produktion eingebettet werden, nicht in fertigen Songs. Riffusion wiederum operiert auf einer dritten Ebene: Es ist ein experimentelles Werkzeug für Klangideen, Loops und Skizzen, das mit der Spektrogramm-Diffusion eine eigene musikalische Logik bedient. Wer einen Hit produzieren will, nimmt Suno. Wer einen 30-Sekunden-Werbe-Soundtrack braucht, nimmt Stable Audio. Wer in einer kreativen Sackgasse einen unerwarteten Klang sucht, der einen weiterträgt, geht zu Riffusion.
Konkrete Empfehlungen: Suno nach dem v5.5-Update (März 2026) ist die führende Wahl für komplette Songs mit Vocals, mit Custom Models und Voices als zentralen Personalisierungs-Features. Das Pro-Abo für 10 Dollar im Monat liefert kommerzielle Rechte und 2.500 Credits. Udio ist klanglich oft brillanter, vor allem bei mainstream-popigem Material. Stable Audio (von Stability AI) bietet zusätzlich BPM-Steuerung (also Tempo-Vorgaben) und eine Trainingsbasis, die rechtlich sauberer ist als die der Mitbewerber.
Wer Werbe-Jingles und Brand-Audios braucht und Wert auf rechtliche Unbedenklichkeit legt, sollte ElevenMusic ausprobieren. Das Pro-Abo für 9,99 Dollar im Monat enthält 500 Tracks und nutzt das lizenzierte Trainingsmaterial der Verwertungsgesellschaften Merlin und Kobalt eine Garantie, die kein anderes Tool auf dem Markt aktuell bieten kann.
Wenn ausschließlich rechtliche Sicherheit zählt etwa bei Markenkampagnen, in denen jedes urheberrechtliche Risiko vermieden werden muss, lohnt zusätzlich der Blick auf eine wachsende Familie von Tools mit Fairly-Trained-Zertifikat. Allen voran Beatoven.ai (rund 2,50 Dollar monatlich für die Einstiegsversion, mit der Möglichkeit, ein Video hochzuladen, sodass die Musik automatisch dynamisch zur Tonspur passt also bei Sprache leiser, bei Action intensiver wird). Auch Endel (spezialisiert auf adaptive Wellness- und Konzentrations-Soundscapes) und Soundful (mit echten Studio-Samples als Trainingsbasis) gehören dazu. Diese Tools können bei Songqualität und Vocals nicht mit Suno oder Udio mithalten, aber sie bieten eine rechtliche Sicherheit, die in kommerziellen Großproduktionen Gold wert ist — und sie zahlen die Komponisten, deren Material im Training verwendet wurde, anteilig aus.
Eine deutsche Alternative im Hintergrundmusik-Segment ist Loudly aus Berlin (Einstieg ab 8 Dollar monatlich). Vorteil: deutschsprachiger Support, Distribution direkt in Spotify und Apple Music. Aber: Loudly ist nicht Fairly-Trained-zertifiziert, und mehrere unabhängige Reviews dokumentieren Berichte, wonach Loudly-Tracks trotz „royalty-free“-Versprechen YouTube-Copyright-Claims auslösen können. Wer rechtlich auf Nummer sicher gehen will, ist mit Beatoven besser bedient.
Eine Sonderrolle spielt Mureka.ai, ein Newcomer mit einem ungewöhnlichen Feature: Man kann seine eigene Stimme als „Sänger“ einbinden wenige aufgenommene Samples reichen, dann singt die KI in der eigenen Stimme. Damit verschmelzen erstmals Voice Cloning und Musikgenerierung in einem Werkzeug. Noch nicht so ausgereift wie Suno oder Udio, aber für persönliche Songprojekte (etwa Geburtstagslieder mit der eigenen Stimme als Sänger) ein interessanter Spezialfall.
Für Sounddesign und Foley (also die Geräuschuntermalung von Videos, Schritte, Türen, Wind) gibt es seit 2024 FoleyCrafter, ein akademisches Open-Source-Modell, das Stummvideos automatisch passende Geräusche hinzufügt. In Kombination mit KI-Video-Tools wie Sora oder Runway entsteht damit zum ersten Mal eine vollständig synthetische audiovisuelle Pipeline.
Zur schnellen Orientierung eine kompakte Übersicht der wichtigsten Werkzeuge nach Anwendungsfall:
| Anwendung | Tool | Stärke | Risiko / Hinweis |
|---|---|---|---|
| Transkription | Whisper | Lokal lauffähig, 99 Sprachen, gratis | Halluzinationen prüfen, gerade bei Medizin/Recht |
| Voiceover | ElevenLabs | Realistische Stimmen, Audio-Tags | Consent bei Voice Cloning fremder Stimmen |
| Voice Agents | OpenAI gpt-realtime | API, Tool-Anbindung, SIP-Telefonie | Token-Kosten, Latenz prüfen |
| Voice Presence | Sesame | Natürliches Gesprächsgefühl | Beta, noch nicht enterprise-reif |
| Echtzeit-Telefonie | Cartesia Sonic-3 | Latenz unter 100 ms | Wenig deutsche Stimmen |
| Dubbing | HeyGen | Videoübersetzung mit Lip-Sync, 175+ Sprachen | Persönlichkeitsrechte beachten |
| Songs | Suno (v5.5) | Komplette Songs, beste Vocals | Trainingsdaten-Klage Sony noch offen |
| Songs | Udio | Klanglich brillant, post-UMG-Lizenz | Walled garden, kein Export auf Drittplattformen |
| Soundtracks / SFX | Stable Audio | BPM-Steuerung, lizenzierte Daten | Kein Gesang, max. 3 Min |
| Brand-Audio | ElevenMusic | Merlin/Kobalt-Lizenz, kommerziell unbedenklich | Beta, kürzere Tracks |
| Hintergrundmusik | Beatoven.ai | Fairly-Trained-zertifiziert, ab $2,50/Monat | Kein Gesang, weniger kreative Freiheit |
| Experimente / Loops | Riffusion | Spektrogramm-Logik, Skizzen, Klangideen | Kein Tool für fertige Songs |
Mein Vorschlag für Hobby-Kreative, die einen produktiven Stack mit minimalen Kosten suchen: Suno Pro (10 Dollar) plus ElevenLabs Starter (5 Dollar) plus Whisper (gratis, lokal). 15 Dollar im Monat. Das ist die produktivste Audio-Pipeline aller Zeiten und sie ersetzt, was vor drei Jahren ein sechsstelliges Studio-Investment erfordert hätte.
Drei Faustregeln noch: Free-Tier-Suno nicht für kommerzielle Tracks nutzen ein nachträgliches Upgrade legalisiert ältere Songs nicht. KI-Audio jetzt schon freiwillig kennzeichnen ab 2. August 2026 ist es ohnehin EU-Pflicht. Und beim Klonen fremder Stimmen immer schriftliche Einwilligung holen sonst greifen Tennessee ELVIS Act, dänisches Likeness-Gesetz oder DSGVO.
Was bleibt offen
Vielleicht werden wir in zehn Jahren auf 2024 bis 2026 zurückblicken wie heute auf die ersten Jahre nach Erfindung der Schallplatte. Damals stellten sich vergleichbare Fragen: Wer spielt noch Konzerte, wenn Musik beliebig kopierbar ist? Wer bezahlt Komponisten, wenn jeder eine Aufnahme besitzen kann? Die Antworten kamen durch Verträge, Verwertungsgesellschaften, Streiks, politische Regulierung. Durch all das, was hinter dem technischen Wandel her hechelt und ihn am Ende einrahmt.
Die Audio-KI-Revolution wird ähnlich enden: mit Lizenzen, Kennzeichnungspflichten, Persönlichkeitsrechten an Stimmen, Plattform-Filtern gegen synthetischen Spam, neuen Geschäftsmodellen für menschliche Künstler, die Authentizität als Wertversprechen anbieten. All das ist im Werden.
Was sich nicht ungeschehen machen lässt, ist eine Verschiebung in unserer Wahrnehmung. Bei Bildern haben wir gelernt, kritisch hinzusehen wir prüfen Schatten, achten auf Hände, stutzen bei zu glatten Hauttexturen. Bei Stimmen müssen wir lernen, kritisch hinzuhören. Das ist anstrengender. Stimmen umgehen den Verstand und gehen direkt ins Gefühl. Und genau dort, wo wir Vertrauen empfinden bei der Stimme der Mutter am Telefon, beim Lieblingssong, bei der vertrauten Werbeansage beginnt jetzt die Arbeit, die wir bisher den Augen abverlangt haben.
In Zukunft werden wir nicht nur fragen, ob ein Song gut ist oder ob eine Stimme echt klingt. Sondern: Wer durfte hier klingen? Wer wurde imitiert? Wer wurde bezahlt? Und wann wird aus einem Werkzeug eine Täuschung?
Die KI hat gelernt zu schreiben, zu malen und zu filmen. Jetzt lernt sie zu sprechen und zu singen. Damit berührt sie etwas, das näher an uns ist als jedes Bild: unsere Stimme. Und vielleicht ist genau das der Grund, warum diese Welle uns gerade so unruhig macht.