
How machines learned to speak, sing and grow close to us with AI audio.
The Song Nobody Sang
It was mid-April 2023, shortly after Easter, when a track started circulating on TikTok that sounded like a collaboration between Drake and The Weeknd. The voice was raw, the beat silky, the songwriting polished — everything you’d expect from an unannounced feature between the two superstars. Within 24 hours, over a million plays. Similar numbers on Spotify. Listeners left enthusiastic comments saying it was finally a good Drake again.
Only: neither Drake nor The Weeknd had sung a single note of it. The track — released on streaming services on April 4th and going viral as a TikTok snippet from April 15th — came from an anonymous user called Ghostwriter977. “Heart on My Sleeve” was created entirely with AI: voices, lyrics, production. Universal Music Group had the song removed from platforms on April 17th via DMCA takedown notices — interestingly citing the fact that Ghostwriter977 had embedded a Metro Boomin producer tag (a brief audio signature that actually belonged to UMG) in the recording. By then it was too late. The audio track had been copied, shared, embedded in reaction videos, duplicated across servers. Anyone who wanted to hear the song could hear it. And trust in the authenticity of recordings had shifted forever.
Nine months later, on January 21, 2024, in New Hampshire: thousands of voters receive a phone call. Joe Biden’s voice, familiar from a thousand speeches, urges them to stay away from the Democratic primary. Forensic analysts from Pindrop and Hany Farid (UC Berkeley) needed less than a week to confirm what many had already suspected: the voice had been generated using ElevenLabs, an AI tool that anyone with a credit card could use at the time for a few dollars. The perpetrator was later prosecuted. But the real point remained: voices we know from television can be cloned in seconds. For the price of a cappuccino.
These two moments — the Drake song and the Biden call — are the cultural bookends of this story. Between them unfolds the most rapid audiovisual upheaval since the invention of the MP3. And it affects us more intimately than the flood of images of the past few years ever did.

Why This Article Had to Be Written
Anyone who today talks to ChatGPT instead of typing, generates a song on Suno, has an English brand spot localised into 30 languages, or receives a voicemail from a person who isn’t actually that person — they are moving through an acoustic world that didn’t exist four years ago.
We look at images. Sounds go straight through us.
This article traces four years: 2022 to 2026. It explains what has happened technically, what is currently being negotiated legally, which tools you should know about today, and which questions remain unanswered. It is aimed at anyone who uses audio professionally or privately — and who wants to understand what has actually changed and why.
Audio Was Always a Computer Dream
Before we enter 2022, a brief step back. Computer voices are not an invention of the AI age. As early as 1939, Bell Labs demonstrated the VODER — a device capable of synthesising human speech, operated by a trained human at a keyboard. The concept proved valid. What was missing for decades was quality.
In the 2010s the pace accelerated. WaveNet from DeepMind (2016) showed that neural networks can generate raw audio sample by sample — and sound more natural than any previous TTS system. At the same time, Transformers showed that long-range dependencies in sequences could be modelled extremely well. The crucial insight came when researchers began representing audio not as raw waveforms but as sequences of discrete tokens: sound compressed into a kind of “vocabulary”.
That was the silent revolution. Because once audio suddenly looks like text — like a sequence of tokens — it can be processed with all the same tools. Language models, attention mechanisms, reinforcement learning. The same architectures that produce text can now produce sound.
What began in 2022, then, is not the invention of artificial sound. It is the moment when artificial sound became indistinguishable from human sound — and simultaneously freely accessible.
2022: Machines Learn to Listen
The story begins with a tool that most people don’t even perceive as AI. On September 21, 2022, OpenAI released Whisper — a speech recognition model trained on 680,000 hours of audio across 99 languages, released under an MIT licence (i.e. largely free to use). Whisper was no demo. It was free, could run locally, and the word error rate (the proportion of incorrectly recognised words) halved compared to commercial predecessors. Suddenly any developer could build a transcription feature into an app that was as good as what corporations had previously paid five-figure licence fees for.
Whisper became the invisible backbone of an entire generation of products — Otter.ai, Descript, Fireflies and thousands more. Today, in its large-v3 version, Whisper has over four million monthly downloads on Hugging Face — the open reference for speech recognition worldwide.
The second major release came in December 2022, somewhat more quietly. Two hobby developers fine-tuned Stable Diffusion to generate images — but trained it on spectrograms instead of photos. A spectrogram is a visual representation of audio: frequency on the Y axis, time on the X axis. The result was Riffusion: a model that generates audio by generating images. The logic was bizarre. The output was usable. And it demonstrated for the first time how audio and image generation are more closely related than they appear.
But Whisper also has a downside that is too little discussed today. Several studies — one analysing over 100 hours of medical transcriptions, another from the University of Zurich examining journalistic interview material — showed systematic errors in certain groups: people with non-native accents, dialects, speech impairments. The word error rate for some African American speakers was up to 50% higher than for standard American English. This is not a marginal problem for a tool used in medical documentation, legal dictation or automated subtitles.
2022 was thus the year in which speech definitively became machine-readable — searchable, archivable, analysable. And that changes things: anyone who spoke in front of a microphone since 2022 — in a meeting, a podcast, a lecture — can assume that every word can be retrieved, contextualised and repurposed. Consent to record is no longer consent to indexing.
2023: Voice and Music Become Generative
If 2022 was the year of listening, then January 2023 was the densest month in the history of AI audio. Three releases, in barely four weeks, each of which would have been a sensation on its own.
On January 5th, Microsoft introduced VALL-E. The model could generate a complete sentence in the voice of any speaker from just three seconds of their audio — complete with their breathing, their rhythm, their vocal colour. The demo was not made publicly available, but the paper described results that were difficult to distinguish from real speech.
On January 26th, Google showed MusicLM: from a prompt like “a calming violin melody backed by a distorted guitar riff” came a fully produced piece of music. Not a MIDI loop, not a library track — audio generated from text.
And in January, ElevenLabs launched in beta in the United States. The company, founded by two former Google employees, offered voice cloning — the ability to create a complete voice model from a brief audio sample — and text-to-speech with emotional nuance. Within days of going viral on Twitter, the platform had thousands of users. And already in the first weeks came the first abuse reports: celebrities’ voices were being used for fake statements, fictional insults, fabricated opinions.
ElevenLabs responded: stricter verification, watermarking, a ban on cloning public figures without consent. But the pattern had already been established: the same technology that enables impressive legitimate use cases enables impressive illegitimate ones with the same ease.
The rest of the year was a wave. In June 2023, Meta released MusicGen as an open-source response to MusicLM. In September 2023, Stability AI released Stable Audio 1.0 — the first commercially viable music model with 44.1 kHz resolution (i.e. CD quality).
And in November 2023 something remarkable happened: The Beatles released “Now and Then” — the last Beatles song. What made it possible was a machine learning tool that Peter Jackson had developed for his documentary film Get Back. It could isolate John Lennon’s voice from a 1979 cassette demo recording that was acoustically almost unusable. Producer Giles Martin described it this way: the machine recognises the voice of a specific person and filters out everything else. The result is not synthetic, but restored. Lennon’s real voice. From a tape that was previously considered unsalvageable.
“Now and Then” and “Heart on My Sleeve” mark the two poles between which the AI audio discussion has moved ever since. The legitimate pole: restoring and completing something real. The illegitimate pole: fabricating something that never existed and presenting it as real. The technology is the same. The intention makes the difference.
2024: AI Audio Becomes Mass Product
2024 was the year when AI audio leapt from research labs into pockets everywhere. Three tools defined this year.
Suno V3 arrived in March 2024. Until then, AI songs had been recognisable — sometimes from a lifeless vocal track, sometimes from a clunky song structure. V3 was different. From a simple prompt came a fully produced song: verse, chorus, bridge, a catchy melody, a convincing voice. By May 2024, Suno had reportedly ten million users. In February 2026, Suno CEO Mikey Shulman on LinkedIn and market research firm Sacra reported two million paying subscribers and $300 million in annual recurring revenue across a cumulative ten million users. In the investor pitch deck for the Series C round in November 2025, Suno also cited a remarkable figure: around seven million tracks are generated on the platform per day.
Udio launched on April 10, 2024. Behind the tool stood four former Google DeepMind researchers, backed by $10 million seed capital from Andreessen Horowitz, will.i.am, Common and Mike Krieger (co-founder of Instagram). Udio felt musically more nuanced than Suno, with somewhat more instrumental depth — a matter of taste, but one that swayed many professionals.
In May 2024 came a moment that illustrated the absurdity of the new landscape: in the middle of the legendary beef between Drake and Kendrick Lamar, comedian Willonius Hatcher wrote a few lines, ran them through Udio, and out came “BBL Drizzy” — a Motown pastiche that mocked Drake in a way no human songwriter could have managed so quickly. A few days later, star producer Metro Boomin shared the track on his Instagram, praised it, and offered $10,000 for the best flip. The track was eventually sampled on a commercially released song by a major-label artist.
It was the first case in which a fully AI-generated sample was legally embedded in a major release by one of the biggest artists in the world. No copyright claim. No takedown. Because there was nothing to claim.
And then, on May 13, 2024, the scandal that has dogged the AI industry to this day. OpenAI introduced GPT-4o — a new multimodal model with a new voice mode. The demo was spectacular: fluid, natural-sounding dialogue, emotional inflection, a voice character called Sky. The problem: Sky sounded unsettlingly similar to actress Scarlett Johansson — specifically to her role as the AI “Samantha” in the film Her.
Scarlett Johansson had previously declined an offer to voice GPT-4o — twice. Her lawyers contacted OpenAI. OpenAI took Sky offline, and CEO Sam Altman posted a single word on X: “her.” Whether this was a deliberate allusion, an unfortunate coincidence, or a test to see how far one could go — that remains disputed.
What can be established: the Sky incident was the moment when the question of personality rights to a vocal quality entered mainstream public consciousness. Voices have signatures. Signatures can be copied. And the copy can be deployed at scale, without compensation, without consent.
Six weeks after the Sky incident, on June 24, 2024, the RIAA (the American recording industry association) filed suit — against Suno and Udio simultaneously. The allegation: mass copyright infringement through training on unlicensed recordings. It was the first major lawsuit in the AI audio space and signalled that the industry had shifted from lobbying to litigation.
2024 was thus also the year when AI audio became a tool for everyone — and simultaneously a court case.
2025: Voice Agents Go Mainstream, Licence Wars Are Fought
If 2024 brought the tools into people’s pockets, then 2025 brought the consequences. On two stages simultaneously: technical maturity and legal reckoning.
Until now, AI voices had mainly been reading aloud — audiobooks, voiceovers, commercials. They were good, but they were loudspeakers: one-directional, scripted, interruptible only in a very limited sense. In February 2025, the company Sesame changed that with its Conversational Speech Model (CSM). Two voice agents were introduced: Maya and Miles.
Maya made pauses. Miles breathed. Both said “um”. Both could be interrupted. And both responded in real time, with emotional resonance that previous voice AI had not achieved. A demo video released at the time accumulated twelve million views in a week. The comment sections were polarised: some found Maya’s voice disturbing — too human, in an uncanny valley way. Others used it immediately as a companion app.
OpenAI also stepped up in 2025. In June, ElevenLabs brought its v3 model into alpha with support for 70 languages, multiple speakers in a single dialogue, and so-called Audio Tags such as [whispers], [excited], [sighs], [laughing]. Anyone wanting a voice AI to whisper softly before a key line could now control this directly in the prompt. In August 2025 came gpt-realtime, OpenAI’s own response: a voice model that jumped from 65.6% to 82.8% accuracy in Big-Bench Audio benchmarks, with support for tools, image processing in voice sessions, and even SIP telephony (i.e. direct connection to traditional phone lines).
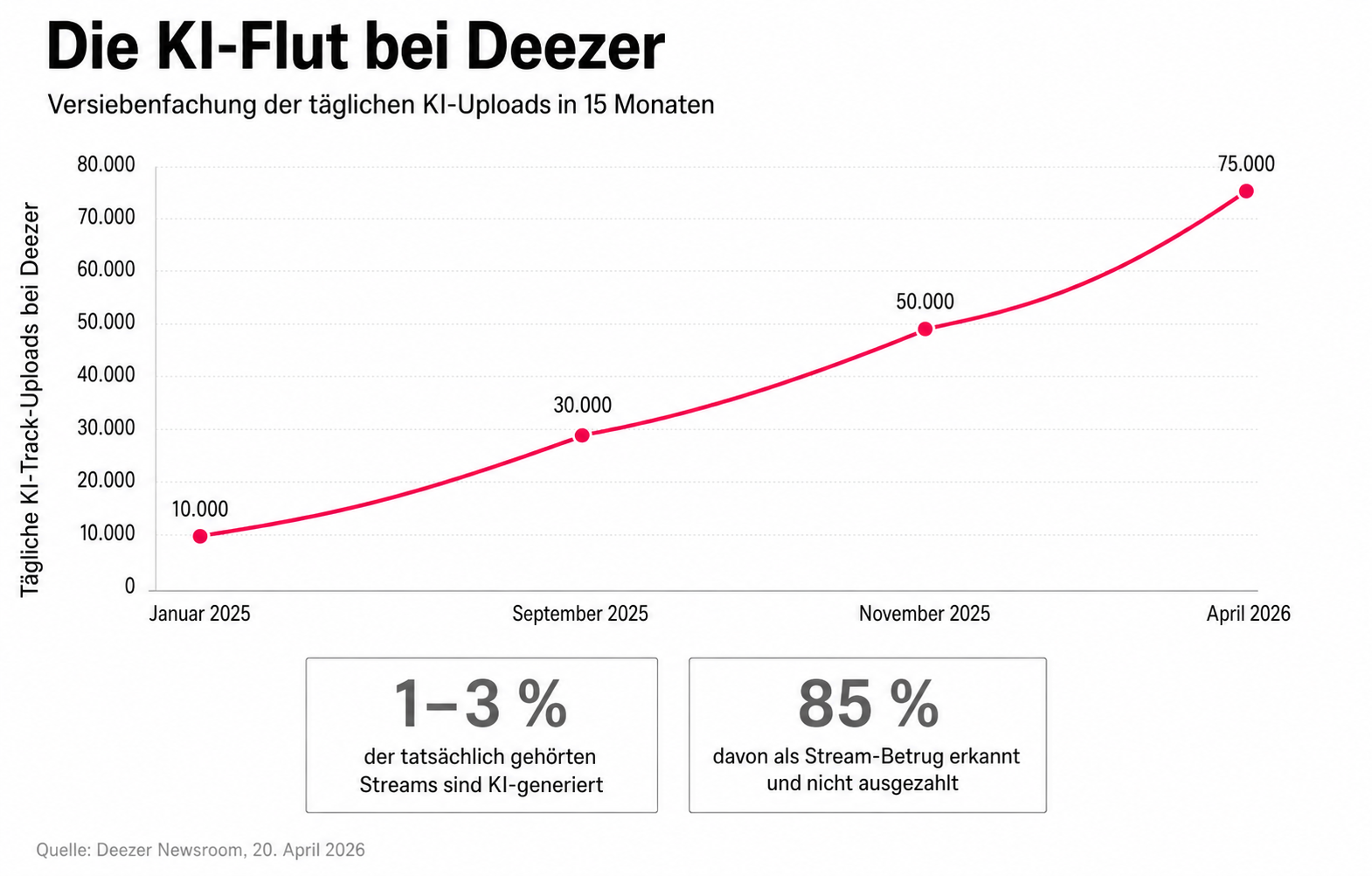
On the music side, three things happened simultaneously in 2025. First: the tools got better. Suno released v5 in September 2025 — the biggest update since V3 — with significantly improved instrumentals, better mixing of vocal and instrument tracks, and a new “Style” parameter that enables more precise genre control. Second: the volume became a topic. Deezer reported in April 2026 that at peak times up to 75,000 new AI tracks were being uploaded per day — compared to 10,000 in January 2025.
Remarkably, the second figure Deezer provided: despite this flood, AI tracks account for only one to three percent of all actually listened streams. Of those, 85 percent are identified by Deezer as fraudulent streams (i.e. artificially inflated plays, presumably with bots) and not paid out. AI music exists in enormous volume — but it is not yet heard.
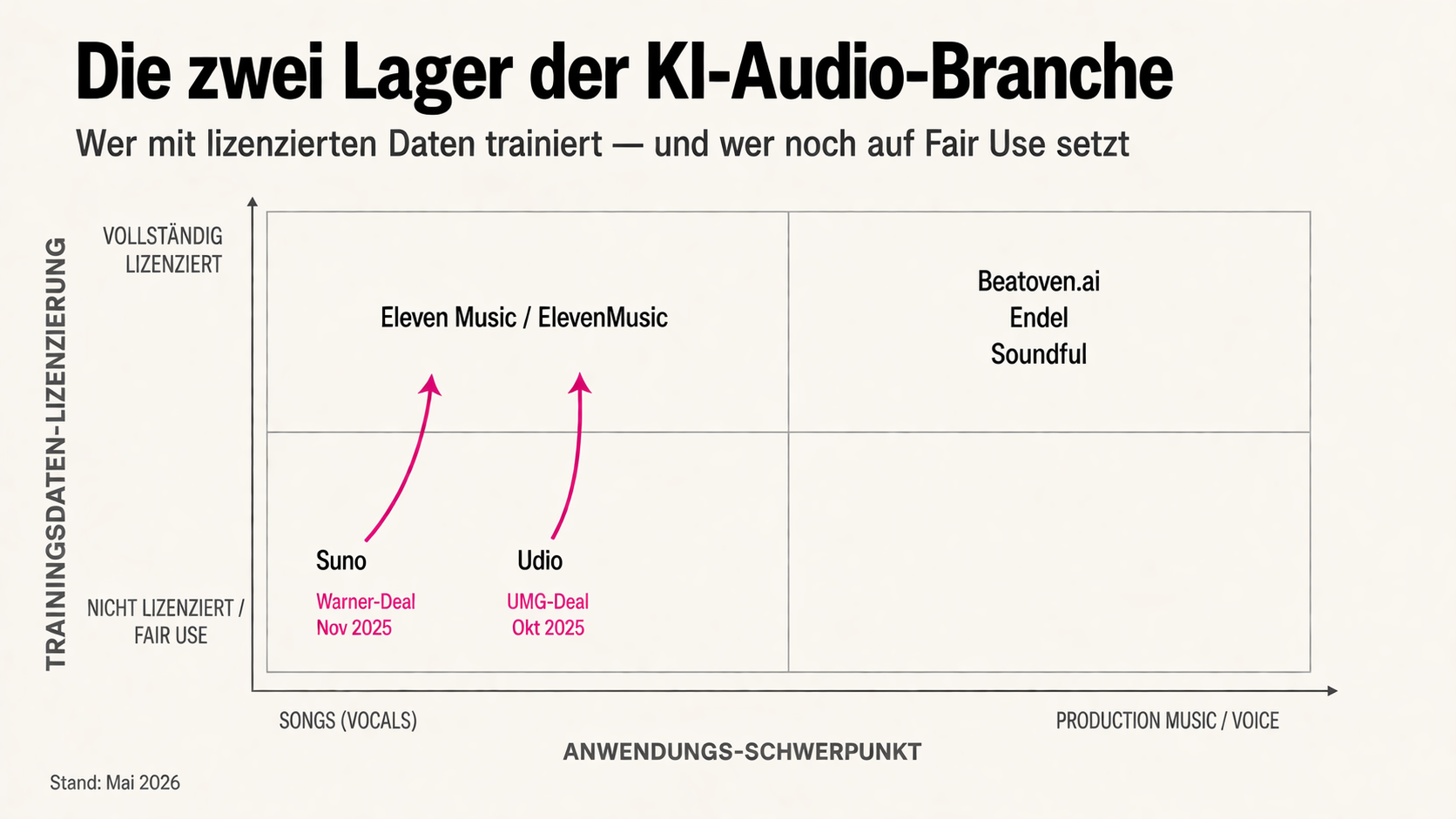
Third, and legally the most important: the first settlements were reached. In October 2025, Universal Music Group settled with Udio on a joint licensing model — the terms of which remain undisclosed, but Udio subsequently gained the right to make pre-licensed music from UMG catalogues available to users. An industry signal: licences are the price for legitimacy.
A story that captures the new business model perfectly: Telisha Jones, 31, from Mississippi, turned one of her poems into the R&B song “How Was I Supposed to Know” using Suno — and in June 2025 released it through a mid-size distributor. The song reached 2.8 million Spotify streams within two months. No production budget. No label. Income: around $11,000 in streaming royalties, entirely for the writer/producer. Jones later said in an interview: “I didn’t need a studio. I needed a story.”
Sony, however, continues to litigate. A first ruling is expected in mid-2026. In Germany too, things became serious: the GEMA (the German collection society) filed suit on January 21, 2025 against Suno and Udio — citing unlicensed use of GEMA-protected music for training. The case is being followed with attention across Europe, as the outcome may shape whether the EU’s approach under the AI Act’s training-data provisions goes further than US copyright law.
While the major players litigate and settle, a smaller movement has emerged in parallel: AI providers who build on licensed material from the outset. Beatoven.ai (India) and Mubert (Russia/Germany) carry the Fairly Trained certification from the nonprofit of the same name, which audits that training data was licensed from rights holders. ElevenMusic operates on licensed catalogues from Merlin and Kobalt. This camp is smaller, the tools often less spectacular — but they stand on legally clear ground.
So ran the shift in 2025: no longer “Can AI generate music and voice?” but “Who is allowed to profit from it?”
2026: Audio Becomes Interface, Studio and Identity Machine
In the year this article appears, the scene has consolidated. The tools are more mature, the business models clearer, and regulation is becoming tangible reality.
In March 2026, Suno released v5.5. Three new features are at the centre: “Voices” allows users to incorporate their own voices as a persona — for example, your own speaking voice as the singer of a song. “Custom Models” allows paying Pro and Premier users up to three individually fine-tuned models, trained on their own tracks. And “My Taste” automatically learns genre and mood preferences. Personalisation is the next frontier.
While Suno and Udio sort out their legal positions, ElevenLabs built a licence-based alternative in parallel. On August 5, 2025, the company released its music model Eleven Music — trained exclusively on licensed material from the Merlin and Kobalt catalogues. On launch day, the model’s output was clearly more limited than Suno’s in terms of musical richness and genre variety. The bet is on legal clarity rather than artistic maximalism.
Voice agents are growing into everyday business life in 2026. Cartesia with its Sonic-3 model pushes latency below 100 milliseconds — that is the response time at which we perceive conversations as truly fluid. This makes voice agents technically deployable wherever real-time feedback is required: customer service, telephone ordering, medical triage. The threshold between “voice bot” and “voice colleague” is shifting.
What distinguishes 2026 from 2024 is not just the technical quality. It is the regulatory reality. On August 2, 2026, the transparency obligations from Article 50 of the EU AI Act come into force. For synthetic or manipulated voice content, this means: disclosure obligation. Anyone who deploys a synthetic voice in a way that could mislead a natural person about the artificial nature of the content must disclose this — with exceptions for clearly artistic or satirical purposes.
Anyone using synthetic voices or cloned individual voices in a German podcast from August 2026 onwards should check very carefully whether and how this must be disclosed. Anyone using a cloned voice in a commercial without consent is already risking legal consequences — regardless of the AI Act.
In 2026, AI audio is no longer just output. It is becoming an interface. And simultaneously a regulated industry.
Three Cultural Shifts That Will Endure
Behind the tools and releases lies a cultural depth dimension that runs across all the years. Three movements are particularly visible.
The first is the memeification of voice. “AI Trump”, “AI Biden”, “AI Drake” became the standard form of political and pop-cultural satire. On TikTok, endless loops still circulate in which Trump, Biden and Obama play Minecraft together. Lionel Messi “speaks” fluent English via HeyGen — a clip that Argentine sports journalist Javi Fernandez published as a demo in September 2023. “BBL Drizzy” became, as already mentioned, the first legal AI sample in a major release by a global star. The imitation of prominent voices is no longer a technical challenge in 2026. It is a legal and ethical one.
The second movement is what the English-language press calls “AI Resurrection” — the acoustic revival of deceased or vocally impaired artists. “Now and Then” by the Beatles is the clean pole: Lennon’s real voice, ML-isolated from a poor recording, re-embedded in a new context. The murky pole: voice models of deceased musicians, trained on bootlegs and unofficial recordings, marketed as “posthumous albums”. Between these two poles lies a spectrum that existing law has not yet fully mapped.
Here grief, commercial exploitation and personality rights collide. The central question of AI audio ethics is: who is allowed to imitate whose voice, and when? The status of the person (alive, deceased, capable of consent)? The purpose (art, commerce, satire, extortion)? The context (studio, social media, phone call)? The answer is different in the US, in Germany, and — since the AI Act — in the EU.
The third shift is economic, and it concerns who makes money from music. Even before the AI wave, the economics of streaming had already shifted towards catalogue music and background sound: relaxation playlists, concentration soundtracks, white noise. AI accelerated this trend. A lofi track generated in three minutes is technically indistinguishable from a carefully crafted human track on the same playlist — and costs the platform a fraction of the licensing fee.
The question facing the streaming industry is no longer whether AI music will be tolerated. It is whether human artists can still earn enough from it — and whether platforms have any interest in making that possible.
Practical Guide: Which Tools You Should Know Today
Enough theory. Anyone deploying AI audio in May 2026 has a mature range of options. Here is a compact overview, sorted by use case.
For speaking voices, voiceovers and voice cloning, ElevenLabs remains the reference point. The Starter subscription at $5 per month provides commercial usage rights, 30,000 credits (enough for a few hours of audio) and voice cloning. Anyone needing multiple speakers, multilingual dubbing or emotionally finely tuned voices will find a professional workbench in ElevenLabs. Alternatively, it’s worth looking at Hume AI (better for emotionally charged content like therapy or coaching apps) or Cartesia (for real-time telephony with minimal latency).
For voice agents — i.e. AI voices that respond in dialogues rather than reading out texts — OpenAI gpt-realtime and Sesame are the strongest options. OpenAI gpt-realtime scores on tool connectivity and API flexibility; Sesame scores on conversational naturalness. Both are not yet technically final — gpt-realtime in particular has higher latency in complex dialogue flows than the spec promises.
For transcription, Whisper remains the gold standard. Anyone wanting to run it locally (i.e. on their own machine, without cloud uploads) will find a maintained, optimised implementation in faster-whisper (on GitHub). The large-v3 model delivers best-in-class accuracy; the medium model offers a good balance of speed and quality for most use cases.
In the area of music generation, a brief sorting of the tool logic is worthwhile, because the terms often get confused. Text-to-music tools (Suno, Udio, MusicGen) generate complete audio files from a text prompt — including vocals if desired. Audio continuation tools (Stable Audio, some Suno features) extend or vary an existing piece. Sound design tools (Riffusion, FoleyCrafter) generate individual sounds or textures for video, game or atmospheric use. And structured composition tools (Mubert, Beatoven.ai) generate looping background music based on mood and BPM specifications.
Concrete recommendations: Suno after the v5.5 update (March 2026) is the leading choice for complete songs with vocals, with the most convincing results across genres. The Pro plan costs $10 per month, with commercial rights to outputs. Udio is comparable in musical quality, slightly more nuanced but more restricted in export options since the UMG settlement.
Anyone needing advertising jingles and brand audio — and valuing legal certainty — should try ElevenMusic. The model is in beta, the tracks currently shorter (up to 3 minutes), but the licensing foundation is unambiguous.
Where legal certainty is the only thing that matters — for example in brand campaigns where every copyright risk must be avoided — the certification-based providers are the right choice. Beatoven.ai (Fairly Trained certified, from $2.50 per month) generates background music without vocals, well suited to explainer videos or podcasts.
A German alternative in the background music segment is Loudly from Berlin (from $8 per month). Advantage: GEMA-cleared tracks, which is legally relevant for German-language platforms and broadcasts.
Mureka.ai plays a special role — a newcomer with an unusual feature: you can use your own voice as a “singer” in AI-generated music. The output is not voice-cloned in the ElevenLabs sense, but a blend of your own voice with AI-generated instrumentals and harmonics. Still in beta, but worth watching for musicians looking to experiment with their own vocal identity.
For sound design and foley (i.e. the sound underlaying of videos — footsteps, doors, wind) there has been FoleyCrafter since 2024 — an open-source tool from the Chinese Academy of Sciences that generates foley from video input. For commercial use, ElevenLabs Sound Effects is a faster alternative: text-to-SFX, integrated directly into the ElevenLabs platform.
For quick orientation, a compact overview of the most important tools by use case:
| Use Case | Tool | Strength | Risk / Note |
|---|---|---|---|
| Transcription | Whisper | Runs locally, 99 languages, free | Check for hallucinations, especially in medicine/law |
| Voiceover | ElevenLabs | Realistic voices, audio tags | Consent required for cloning third-party voices |
| Voice Agents | OpenAI gpt-realtime | API, tool connectivity, SIP telephony | Token costs, check latency |
| Voice Presence | Sesame | Natural conversational feel | Beta, not yet enterprise-ready |
| Real-time Telephony | Cartesia Sonic-3 | Latency under 100 ms | Limited non-English voices |
| Dubbing | HeyGen | Video translation with lip-sync, 175+ languages | Respect personality rights |
| Songs | Suno (v5.5) | Complete songs, best vocals | Sony training-data lawsuit still pending |
| Songs | Udio | Sonically brilliant, post-UMG licence | Walled garden, no export to third-party platforms |
| Soundtracks / SFX | Stable Audio | BPM control, licensed data | No vocals, max. 3 min |
| Brand Audio | ElevenMusic | Merlin/Kobalt licence, commercially safe | Beta, shorter tracks |
| Background Music | Beatoven.ai | Fairly Trained certified, from $2.50/month | No vocals, less creative freedom |
| Experiments / Loops | Riffusion | Spectrogram logic, sketches, sound ideas | Not a tool for finished songs |
My suggestion for hobby creatives looking for a productive stack with minimal costs: Suno Pro ($10) plus ElevenLabs Starter ($5) — that’s $15 per month for complete AI audio production, from song generation to polished voiceover. Anyone who also needs transcription adds faster-whisper locally for free.
Three rules of thumb to finish: don’t use free-tier Suno for commercial tracks — a subsequent upgrade does not retroactively licence older outputs. Always watermark or label AI-generated audio in public contexts, even where this is not yet legally required — because the AI Act is coming. And: read the ToS carefully when voice-cloning. Cloning your own voice is unproblematic in most cases. Cloning someone else’s without consent is — depending on jurisdiction — already an infringement today.
What Remains Open
Perhaps in ten years we will look back on 2024 to 2026 the way we now look back at the early years after the invention of photography. There was a lot of confusion then too: about authorship, authenticity, the right to one’s own image. Courts debated whether a photograph could be art. Practitioners adopted the technology regardless.
The AI audio revolution will end similarly: with licences, disclosure requirements, personality rights for voices, platform responsibilities. With a few landmark cases that clarify what is permitted — and many that don’t quite clarify. With a technology that persists, regardless of how slowly the law follows.
What cannot be undone is a shift in our perception. With images, we have learned to think critically: is this real? With audio, that shift is still underway. The deepfake that sounds like a family member, the voice assistant that sounds like a friend, the politician who never said what we just heard him say — these scenarios are no longer futuristic. They are documented cases.
In future, we will not only ask whether a song is good or whether a voice sounds real. But: who was authorised to clone it here? Was there consent? And: does it matter?
AI has learned to write, to paint and to film. Now it is learning to speak and to sing. In doing so, it touches something more intimate than pixels: the voice as the most personal expression of the self. The question is no longer whether we can tell the difference. The question is what it means for us when we can no longer.