
Was du in diesem Tutorial baust, ist kein Google Alert. Es ist eine vollständige, KI-gesteuerte Nachrichtenredaktion – automatisiert von der ersten Quellensuche bis zum fertigen WordPress-Artikel.
Das System durchforstet das Internet selbstständig nach den wichtigsten Entwicklungen im Bereich Künstliche Intelligenz. Als Gehirn dahinter dient n8n – ein selbst gehostetes Automatisierungswerkzeug, das verschiedene spezialisierte KI-Agenten zu einem digitalen Redaktionsteam zusammenschnürt. Dieses Team filtert die riesige Informationsflut aus RSS-Feeds, bewertet jeden Treffer nach Relevanz und verwandelt die besten Artikel in hochwertige Blog-Beiträge.
Um diese Anleitung verständlicher zu machen, begleiten dich drei Personen:
Die typischen Büro-Charaktere: Die kompetente IT-Kollegin, der selbsternannte Experte und der ehrliche Anfänger. Diese drei Perspektiven helfen dir, typische Stolperfallen zu erkennen und n8n wirklich zu verstehen.
Tanja ist die IT-Expertin. Sie weiß, wie n8n funktioniert, erklärt geduldig und strukturiert – und lässt sich von schlechten Ratschlägen nicht aus der Ruhe bringen. Wenn du eine Frage hast, hat Tanja die Antwort.
Bernd ist der selbsternannte „Experte“, der alles besser weiß – und meistens falsch liegt. Seine Abkürzungen und sein Halbwissen führen regelmäßig zu Problemen. Er steht für alle gefährlichen Mythen und schlechten Praktiken, die du vermeiden solltest.
Ulf ist der Lernende, genau wie du. Er stellt die Fragen, die dir im Kopf herumschwirren, und braucht manchmal einen Vergleich aus dem Alltag, um IT zu verstehen. Wenn Ulf etwas nicht versteht, ist das völlig in Ordnung – dafür ist Tanja da.
Diese drei Perspektiven helfen dir, typische Stolperfallen zu erkennen und n8n wirklich zu verstehen.
„Und… Action!“
Montag, 8:47 Uhr. Im Büro.
Ulf starrt auf seinen Bildschirm. Drei Browserfenster mit KI-Newsseiten, ein halbvolles Glas Kaffee, und das dumpfe Gefühl, dass er gerade wieder eine halbe Stunde damit verschwendet hat, Heise, Golem und t3n nacheinander durchzuklicken, um ja nichts zu verpassen.
Ulf: „Ich will eigentlich nur die wichtigen KI-News haben“, murmelt er. „Ohne selbst stundenlang zu suchen.“
Tanja, die seit zehn Minuten daneben sitzt und ihre Notizen liest, hebt den Kopf. „Dann hör auf, es manuell zu machen. Lass eine Maschine für dich suchen.“
Bernd lehnt im Türrahmen. „Ich mach das auch automatisch. Ich hab einen Google Alert eingerichtet. Auf das Wort ‚KI‘.“ Er nickt sich selbst anerkennend zu. „Kriegst hundert Mails am Tag. Alles drin.“
Kurze Stille.
Tanja: „Das ist ungefähr so, als würdest du den kompletten Supermarkt bestellen und dann schauen, was du davon essen kannst.“
Das Entscheidende: Das System arbeitet als „Human-in-the-Loop“-Konstruktion. Die KI übernimmt Recherche, Qualitätsprüfung und das Schreiben. Du als Admin behältst die Kontrolle – kein Artikel erscheint auf deiner Website, bevor du in WordPress grünes Licht gibst. So kombinierst du die Geschwindigkeit von KI mit menschlichem Urteilsvermögen. Schnell und trotzdem klug.
Technisch gesehen baust du ein Multi-Agenten-System, das die Stärken verschiedener Sprachmodelle geschickt kombiniert: GPT-4o-mini für die schnellen, massenhaften Bewertungsaufgaben – und Claude für die anspruchsvolle Artikelerstellung. Dazu kommt eine eigene Datenbank als „Langzeitgedächtnis“, die Duplikate verhindert und deine Redaktionsprozesse professionalisiert.
Das Redaktionsteam – fünf Agenten:
- Agent 1: Recherche (RSS-Feeds, alle 2 Stunden)
- Agent 2: Redaktionelle Einzelbewertung (GPT-4o-mini, alle 4 Stunden)
- Agent 3: Content-Recherche & Anreicherung (GPT-4o-mini + Tavily, täglich)
- Agent 4: Artikel schreiben + Coverbild erstellen (Claude + Flux-2-Flex, täglich)
- Agent 5: Veröffentlichen auf WordPress (täglich, mit menschlicher Freigabe)
2 Technische Beschreibung
2.1 Systemarchitektur
Ulf: „Warte mal kurz, die fünf Agenten reden die miteinander? Wie im Büro, so mit Slack oder so?“
Tanja schüttelt den Kopf: „Stell dir eine Fabrik vor. Jede Abteilung macht ihren Job und legt das Ergebnis ins Regal. Die nächste Abteilung holt es von dort ab. Niemand ruft niemanden an.“
„Das Regal“, ergänzt Tanja, „ist die Datenbank.“
Bernd: „Ich hätte die alle einfach miteinander verbunden. Direkt. Viel einfacher.“
Tanja: „Dann hast du ein System, das ausfällt, wenn einer der fünf Agenten einen Fehler macht, und du weißt nicht mehr, wo. Die Datenbank ist der Schlüssel. Jeder Agent liest daraus, schreibt zurück, und setzt einen Status. So weiß jeder, was der andere getan hat – ohne direkt miteinander sprechen zu müssen.“
Der KI Newsroom folgt einer Pipeline-Architektur: Fünf spezialisierte n8n-Workflows arbeiten sequenziell, jeder übernimmt genau eine Aufgabe. Der Schlüssel, der sie zusammenhält, ist eine gemeinsame PostgreSQL-Datenbank als zentrales Gedächtnis. Kein Agent spricht direkt mit einem anderen – sie kommunizieren ausschließlich über die Datenbank, indem sie Datensätze lesen, verarbeiten und deren Status hochsetzen. Die gesamte Infrastruktur läuft self-hosted auf einer Synology NAS im Docker-Betrieb.
[Internet / RSS-Feeds]
↓
A1: Recherche → ki_artikel (Status: NEU)
↓
A2: Bewertung → ki_artikel (Status: BEWERTET)
↓
A3: Content-Recherche → ki_story (Status: ANGEREICHERT)
↓
A4: Artikel + Bild → ki_artikel (Status: PUBLISH_READY)
↓
A5: WordPress → ki_artikel (Status: PUBLISHED)
↓
[WordPress / foundic.org]2.2 Datenbankschema
Die Datenbank besteht aus drei Tabellen – stell sie dir wie drei verschiedene Schubladen in einem Aktenschrank vor.
ki_artikelist die große Hauptschublade. Hier landet jeder eingelesene RSS-Artikel und bleibt dort bis zur Veröffentlichung. Die Tabelle speichert Rohdaten aus dem Feed, KI-Bewertungsscores, fertige WordPress-Inhalte und den aktuellen Workflow-Status. Das Feldurl_normalizedverhindert Duplikate: Tracking-Parameter wieutm_source, daswww.-Präfix und überflüssige Trailing Slashes werden aus URLs entfernt, bevor ein Artikel eingetragen wird. So landen Heise-Links mit und ohne?utm_campaign=newsletternicht doppelt in der Datenbank.ki_storyist die Kreativschublade. Hier liegt der angereicherte, tiefenrecherchierte Inhalt – der von Agent 3 erstellte Hintergrundtext und später der von Claude verfasste fertige WordPress-Artikel. Jede Story ist genau einem Eintrag inki_artikelzugeordnet.ki_artikel_edgesist die Verbindungsschublade. Wenn Tavily bei der Recherche verwandte Webseiten findet, dokumentiert diese Tabelle die Verbindung: Welcher Artikel hat welche Quelle gefunden? Mit welchem Suchbegriff? Auf welchem Ranking-Platz? So entsteht im Hintergrund ein kleines Wissensnetz aus verlinkten Artikeln.
2.3 Die fünf Agenten im Detail
Agent 1 – Recherche (alle 2 Stunden): 22 parallele RSS-Feed-Leser versorgen das System mit Nachrichten aus der gesamten deutschsprachigen Tech- und Qualitätspresse: Heise, Golem, t3n, Computerwoche, FAZ, Handelsblatt, Spiegel, Süddeutsche und viele mehr. Jeder Feed ist mit einem Quellnamen gelabelt. Ein Postgres-Node mit Skip on Conflictverhindert doppelte Einträge; die URL-Normalisierung via JavaScript entfernt vor dem Speichern alle Tracking-Parameter.
Agent 2 – Bewertung (alle 4 Stunden): Ein Basic LLM Chain-Node mit GPT-4o-mini bewertet jeden neuen Artikel auf zwei Dimensionen: KI-Anwendungsrelevanz und KI-Entwicklungsbedeutung (je 0–10). Die Gesamtnote gewichtet Anwendungsrelevanz mit 60 % und Entwicklungsbedeutung mit 40 %. Zusätzlich ordnet die KI jeden Artikel einer von 12 vordefinierten Subkategorien zu.
Agent 3 – Content-Recherche (täglich): Artikel mit score_gesamt >= 7,5 werden tiefenrecherchiert. Der Workflow lädt den Volltext von der Quellseite, prüft die Textqualität und ergänzt mit bis zu 20 Tavily-Suchergebnissen. GPT-4o-mini fasst alles zu einem strukturierten Hintergrundtext zusammen.
Agent 4 – Artikel + Bild (täglich): Der Artikel mit dem höchsten Score geht an Claude Sonnet, der daraus einen rechtskonformen WordPress-Artikel schreibt. Gleichzeitig generiert Flux-2-Flex ein eigenes Coverbild im Editorial-Flat-Design-Stil.
Agent 5 – WordPress (täglich): Fertige Artikel landen zunächst als Entwurf in WordPress – und warten auf deine Freigabe. Das ist der Human-in-the-Loop-Kontrollpunkt.
2.4 Technologien & Kosten
| Komponente | Technologie |
|---|---|
| Orchestrierung | n8n (self-hosted, Docker, Synology NAS) |
| Datenbank & Monitoring | PostgreSQL + Metabase |
| Bewertung & Recherche | GPT-4o-mini (OpenAI) + Tavily |
| Artikel-Erstellung | Claude Sonnet (Anthropic) |
| Bildgenerierung | Flux-2-Flex (Black Forest Labs) |
| Publikation | WordPress REST API |
Bei täglicher Publikation eines Artikels bleiben die monatlichen API-Kosten typischerweise unter 5 Euro – dank GPT-4o-mini für das hohe Volumen (Bewertung + Recherche) und Claude Sonnet nur für den einzelnen, täglich erscheinenden Artikel. Flux-2-Flex kostet ca. 1–2 Cent pro Bild, Tavily ist bis 1.000 Suchen/Monat kostenlos.
3 Umsetzung in n8n
3.1 Datenbank-Setup
Tanja: „Bevor wir die Agenten bauen, brauchen wir das Fundament. Die Datenbank.“
Ulf runzelt die Stirn: „Warum können wir nicht einfach alles in Excel speichern?“
Tanja: „Weil 500 Artikel pro Tag in Excel so aussehen wie ein Stadion nach dem Derbysieg – alles durcheinander, nichts mehr auffindbar.“
Bernd: „Ich hab mal alle Kundendaten in einer Excel-Datei gehabt, hat super funktioniert. Bis ich aus Versehen die falsche Spalte gelöscht hab.“
Tanja ignoriert ihn: „Wir nutzen PostgreSQL. Das ist eine Datenbank, die auf der NAS läuft, Dinge ordentlich wegschreibt und auf Anfrage blitzschnell wieder rausgibt. n8n redet mit ihr wie ein Büro mit seinem Aktenschrank.“
3.1.1 Die Verbindung herstellen (Credentials)
Tanja: „Keine Panik – das klingt komplizierter als es ist. Du musst n8n nur einmalig sagen, wo deine Datenbank wohnt und wie das Passwort lautet. Danach merkt es sich das.“
- Logge dich in deine n8n-Oberfläche auf der NAS ein
- Gehe links auf Start from scratch -> Add first step -> „+“ -> suche nach „Postgres“ -> wähle „Execute a SQL query“ aus -> Credential to connect with: „Create a new Credential“
Wie man n8n mit PostGres SQL Datenbank auf einer Synology Diskstation am Beispiel einer DS1621+ installiert findest Du in dem Artikel https://www.foundic.org/n8n-selbst-hosten-synology-nas-docker-installation.
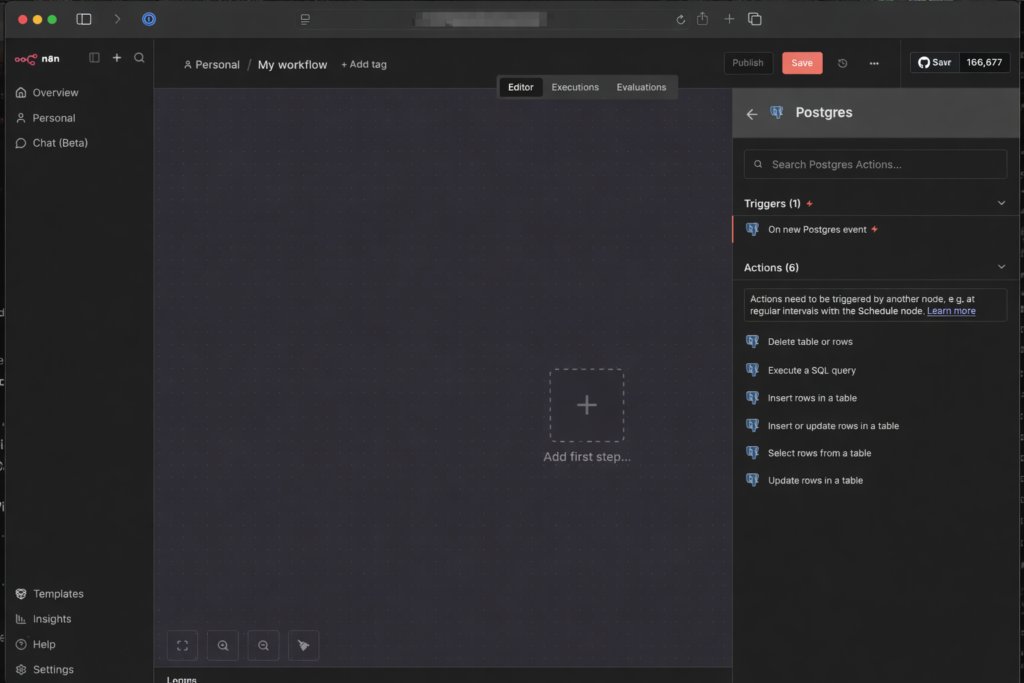
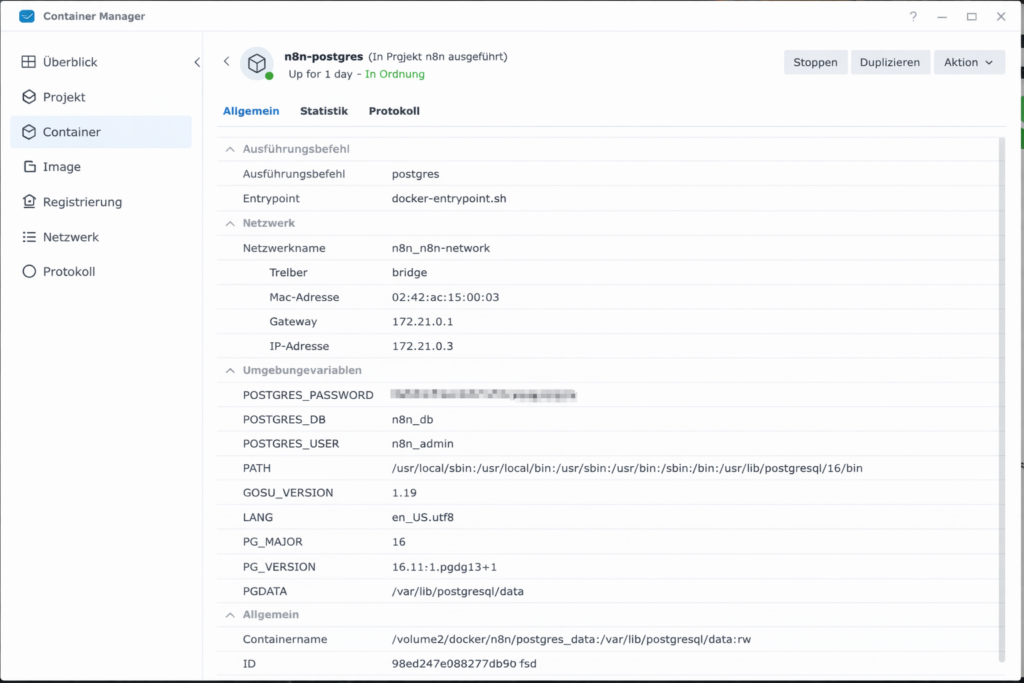
- Jetzt musst du die Daten eingeben, die du im Synology Container Manager findest unter Container -> postgres container -> Details
- Host: IP-Adresse oder Containername (wenn im gleichen Projekt)
- Database: Meistens
postgresodern8n_db(je nachdem, was bei der Installation alsPOSTGRES_DBangegeben wurde) - User: Der Name, den du vergeben hast (oft
postgresoderadmin) - Password: Dein festgelegtes Passwort
- Klicke auf Save. Wenn oben ein grünes Schild mit „Connection tested successfully“ erscheint, steht die Leitung!
- Nenne ihn oben links in der Workflow Übersicht:
Set-up Database
3.1.2: Erste Tabellen in der Datenbank erstellen
Die Tabelle ki_artikel ist das zentrale digitale Gedächtnis deines Newsrooms – hier landen alle gesammelten Nachrichten, Bewertungen und der Veröffentlichungsstatus.
Stell dir vor, du richtest einen neuen Aktenschrank ein. Bevor du Dinge hineinlegen kannst, musst du die Fächer beschriften. Genau das macht das folgende SQL-Skript: Es legt die Fächerstruktur an.
- Schließe das Credential-Fenster (oben rechts auf das X klicken).
- Du befindest dich nun wieder im Fenster der Postgres-Node (Execute a SQL query), ggf. Doppel Klick auf „Execute a SQL query“
- Lösche die 1 im Feld Query komplett heraus.
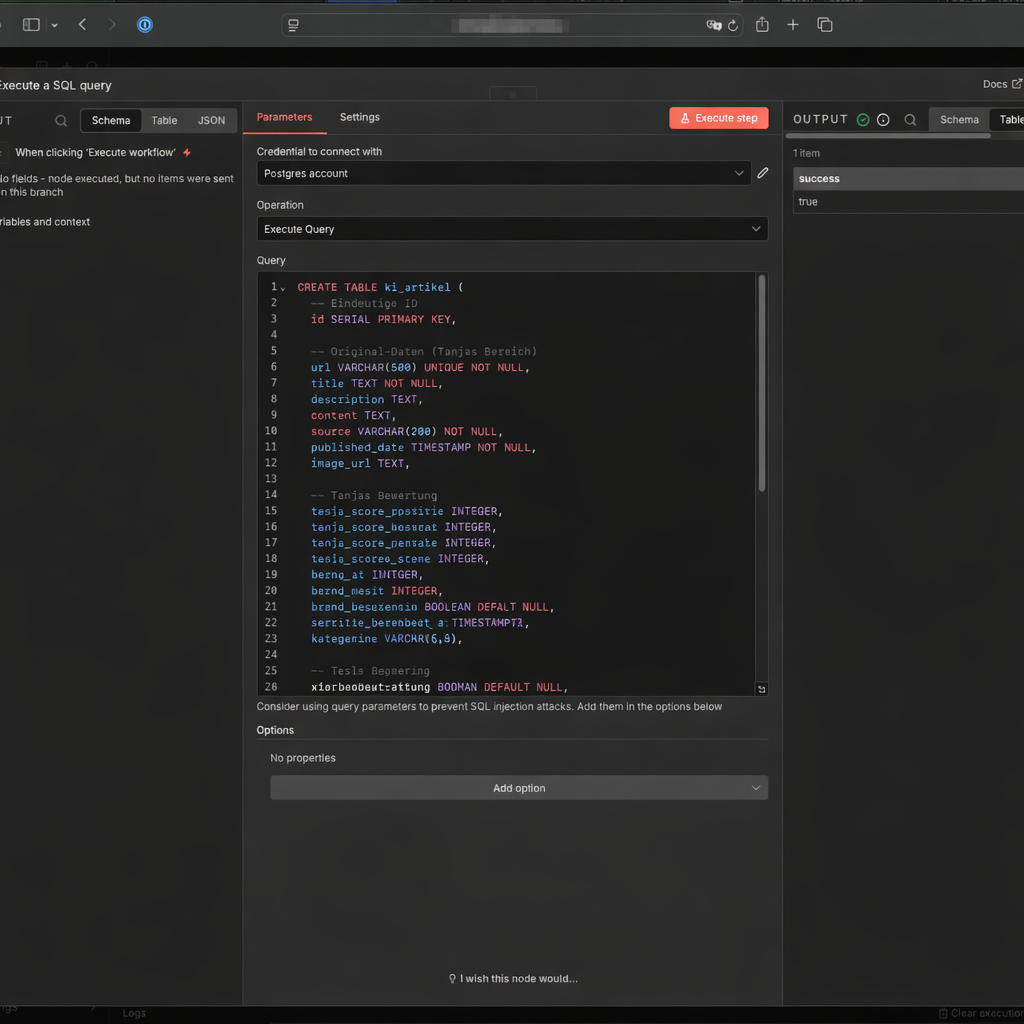
- Kopiere das folgende SQL-Skript und füge es dort ein:
CREATE TABLE ki_artikel (
-- Eindeutige ID
id SERIAL PRIMARY KEY,
-- Original-Daten
url VARCHAR(500) UNIQUE NOT NULL,
title TEXT NOT NULL,
description TEXT,
content TEXT, -- für später
source VARCHAR(200) NOT NULL, -- z.B. 'Heise'
published_date TIMESTAMP,
image_url TEXT,
source_type TEXT -- z.B. 'rss'
first_seen_at TIMESTAMPTZ NOT NULL DEFAULT now()
url_normalized TEXT
-- Workflow-Status
status VARCHAR(50),
-- Bewertung
score_relevanz INTEGER,
score_bedeutung INTEGER,
score_gesamt DECIMAL(3,1),
subkategorie VARCHAR(80) DEFAULT NULL,
bewertung_begruendung TEXT,
-- Zeitstempel
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Index für schnelle Abfragen (Top-News)
CREATE INDEX idx_published_date ON ki_artikel(status, published_date DESC);
CREATE INDEX ki_artikel_url_normalized_idx ON ki_artikel(url_normalized);Klicke auf Execute step.
Danach erstellst du zwei weitere Tabellen. Die erste verbindet Artikel miteinander (ki_artikel_edges), die zweite speichert den angereicherten Redaktionsinhalt (ki_story).
Tabelle ki_artikel_edges – das Verbindungsnetz zwischen Artikeln:
CREATE TABLE IF NOT EXISTS ki_artikel_edges (
id BIGSERIAL PRIMARY KEY,
from_artikel_id BIGINT NOT NULL
REFERENCES ki_artikel(id) ON DELETE CASCADE,
to_artikel_id BIGINT NOT NULL
REFERENCES ki_artikel(id) ON DELETE CASCADE,
relation_type TEXT NOT NULL, -- z.B. 'tavily_related'
query TEXT, -- optional: Suchquery
rank INT, -- Reihenfolge im Tavily Result
score NUMERIC, -- optional: Tavily score/relevance
retrieved_at TIMESTAMPTZ NOT NULL DEFAULT now(),
UNIQUE (from_artikel_id, to_artikel_id, relation_type)
);
CREATE INDEX IF NOT EXISTS ki_artikel_edges_from_idx
ON ki_artikel_edges(from_artikel_id);
CREATE INDEX IF NOT EXISTS ki_artikel_edges_to_idx
ON ki_artikel_edges(to_artikel_id);
CREATE INDEX IF NOT EXISTS ki_artikel_edges_type_idx
ON ki_artikel_edges(relation_type);Tabelle ki_story – der Ort, an dem die fertigen Artikel reifen:
CREATE TABLE IF NOT EXISTS ki_story (
id BIGSERIAL PRIMARY KEY,
primary_artikel_id BIGINT NOT NULL
REFERENCES ki_artikel(id) ON DELETE RESTRICT,
content_enriched TEXT NOT NULL,
enrichment_source TEXT, -- 'direct' | 'search_llm'
score_gesamt_enriched NUMERIC(4,2),
tavily_link_count INTEGER,
status TEXT NOT NULL DEFAULT 'DRAFT',
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT now(),
-- WordPress
wp_title TEXT,
wp_content TEXT,
wp_excerpt TEXT,
wp_tags TEXT,
image_file_path TEXT,
wordpress_post_id BIGINT,
wordpress_url TEXT
);
CREATE INDEX IF NOT EXISTS ki_story_primary_idx
ON ki_story(primary_artikel_id);3.1.3: Workflow-Status Logik
Das status-Feld in ki_artikel ist die Ampelanlage deines Systems. Jeder Agent schaut, ob eine Ampel auf sein Farbe steht, bearbeitet den Artikel und schaltet die Ampel weiter:
NEU(Insert)BEWERTET(Bewertung fertig)ANGEREICHERT(Hintergrundtext fertig)PUBLISH_READY(Artikel gezogen/„reserviert“)PUBLISHED(WordPress veröffentlicht)PUBLISH_BLOCKED(wenn irgendwas rechtlich/technisch nicht passt)
3.2 Agent 1: Recherche über RSS Feeds
Ulf: „RSS-Feeds, sist das nicht Technologie von vor zwanzig Jahren?“
Tanja: „Fußball gibt es seit 150 Jahren, trotzdem ist es die effektivste Art, 22 Leute auf einem Feld zu koordinieren. RSS ist das Gleiche: simpel, robust, funktioniert überall.“
Bernd: „Ich habe gehört, RSS ist tot“.
Tanja: „Dann haben Heise, Spiegel, FAZ und die Süddeutsche es noch nicht mitbekommen. Die betreiben alle noch aktiv RSS-Feeds.“
3.2.1 Den Arbeitsplatz einrichten
- Gehe zurück zur Workflow-Übersicht und klicke auf Create new workflow
- Nenne ihn oben links:
1 Agent: Recherche über RSS Feeds - Klicke auf Add First Step und wähle Schedule Trigger
- Trigger Interval: Hours
- Stelle ihn zunächst auf Manual (= Custom Cron) – damit der Trigger beim Bauen nicht ständig feuert. Den echten Takt stellst du am Ende ein.
- Hours Between Triggers: 2
- Trigger at Minute: 0
3.2.2 Die Quellen anzapfen (RSS-Feed)
- Klicke auf das + hinter dem Schedule-Trigger
- Suche nach der Node RSS Feed Read
- Node: rssFeedRead
- URL: RSS-Feed eintragen (z.B.
https://www.heise.de/rss/heise-atom.xml)
- Klicke auf Test Step. Du solltest jetzt eine Liste mit Titeln und Links sehen
- Du kannst beliebig viele RSS Feed Reader parallel in den Workflow setzen und mit dem Trigger verbinden. Klicke dazu auf den Ausgangspunkt des Triggers und dann auf den Eingangspunkt des jeweiligen RSS Feed Readers.
3.2.3 RSS Feed die Quelle zuordnen
- Klicke auf das + Symbol am Ausgang deiner RSS-Nodes
- Suche nach der Node Edit Fields (Brauchst diesen Node für jeden RSS-Feed)
- Einstellung: * Klicke auf „Add Field“ -> „String“.
- Node: Edit Fields
- Name des Feldes:
source_name-> String - Wert (Value): z.B.
Heise - Include Other Input Fields: aktivieren
- Wiederholung: diese zwei Knoten für alle Deine weitere RSS-Feeds (RSS Feed -> Edit Fields -> Wert:
abc) die Du regelmäßig auslesen möchtest.
3.2.4 Archiv in Datenbank aufbauen
Jetzt zeigst du n8n, wo das Archiv liegt – und wie die Zeitungsschnipsel dort einsortiert werden. Denk an einen Bibliothekar, der eingehende Bücher nach einem festen Schema einräumt.
- Klicke auf das + am Ausgang deiner Edit Fields-Nodes
- Suche nach Postgres und wähle „Insert rows in a table“ aus:
- Node: Insert rows in table
- Credential to connect with: deine
n8n-postgres-Verbindung aus Schritt 3.1.1 - Operation: Insert
- Schema: From list: public
- Tabel: From list:
ki_artikel - Mapping Column Mode: Map Each Column Manually (Daten einsortieren)
- Jetzt kommt der wichtigste Teil: Du musst n8n sagen, welches RSS-Feld in welche Datenbankspalte gehört. Klicke auf Add Column und trage nacheinander folgende Zuordnungen ein:
| Spalte (Column) | Wert (Value) – So machst du es: |
|---|---|
| id | Diese Zeile komplett löschen – die ID zählt automatisch hoch |
| titel | Klicke in das Feld. Suche links im Menü unter „RSS Feed Read“ title und ziehe per drag&drop in title, oder alternativ{{ $json.title }} |
| url | {{ $json.link }} |
| description | {{ $json.summary || $json.content || $json.contentSnippet || “ }} |
| source | {{ $json.source_name }} |
| published_date | {{ $json.isoDate }} |
| image_url | {{ $json.enclosure?.url || “ }} |
| status | NEU (von Hand eintippen, nicht aus dem Menü wählen) |
| source_type | rss (von Hand eintippen) |
| url_normalized | Expression (siehe Code unten) |
Für url_normalized kopiere diesen JavaScript-Ausdruck in das Value-Feld:
{{
(() => {
const raw = $json.link || $json.url || "";
try {
const u = new URL(raw.startsWith("http") ? raw : "https://" + raw);
// Fragment entfernen
u.hash = "";
// Tracking-Parameter entfernen
const dropExact = new Set([
"fbclid","gclid","dclid","msclkid","igshid",
"mc_cid","mc_eid","mkt_tok","yclid","cmpid"
]);
for (const k of Array.from(u.searchParams.keys())) {
const key = k.toLowerCase();
if (key.startsWith("utm_") || dropExact.has(key)) {
u.searchParams.delete(k);
}
}
// Host & Protokoll normalisieren
u.hostname = u.hostname.replace(/^www\./i, "").toLowerCase();
u.protocol = "https:";
// Trailing slash nur bei Root entfernen
if (u.pathname === "/") u.pathname = "";
u.search = u.searchParams.toString()
? "?" + u.searchParams.toString()
: "";
return u.toString();
} catch (e) {
return raw;
}
})()
}}Warum dieser Aufwand? Weil derselbe Artikel von Heise mit fünf verschiedenen Tracking-URLs auftauchen kann – ?utm_source=twitter, ?utm_campaign=newsletter usw. Ohne Normalisierung würde jede Variante als neuer Artikel landen. Mit diesem Code landen alle Varianten als ein einziger Datensatz.
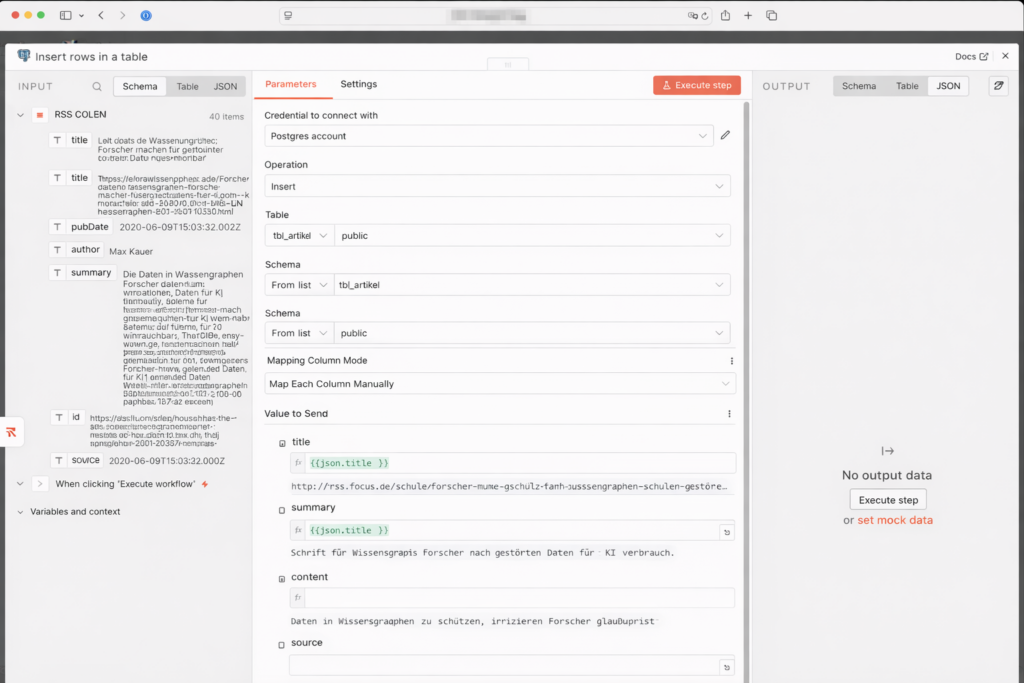
- Lösche alle anderen vorausgefüllten „Values to Update“, damit nur die oben definierten Felder geschrieben werden.
- Ganz unten: Options → Add option → Skip on Conflict aktivieren. Damit wird ein Artikel, dessen URL bereits in der Datenbank liegt, einfach übersprungen statt einen Fehler zu werfen.
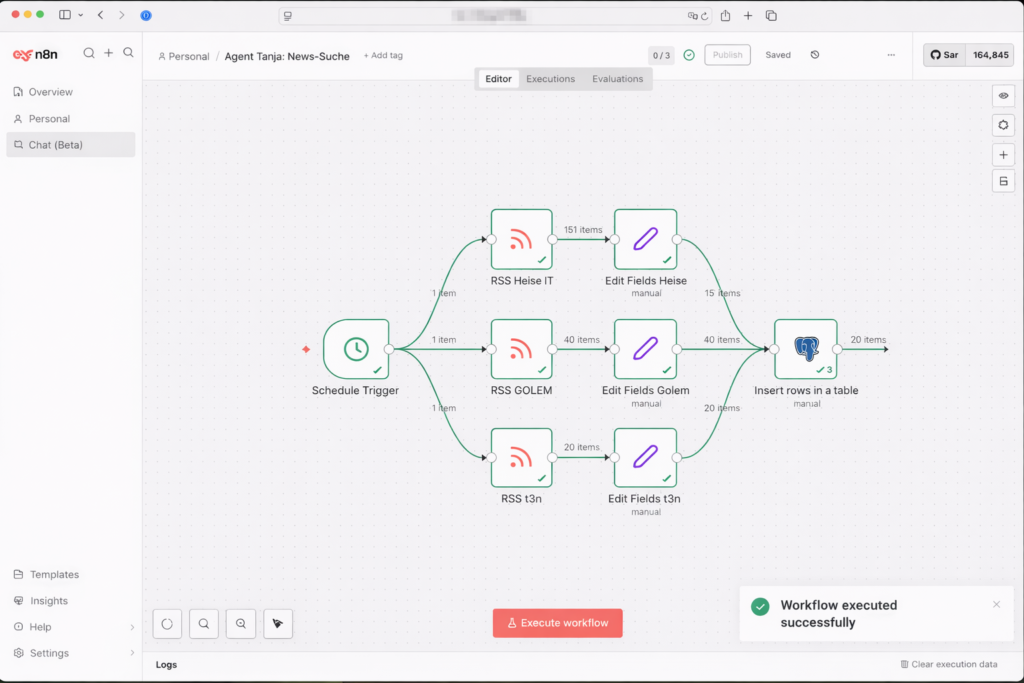
- Testlauf: Klicke auf den orangefarbenen Button „Execute Workflow“. Was jetzt passieren sollte: n8n zieht die News aus den Feeds (grüne Zahlen erscheinen), schickt sie zur Postgres-Node (nächste grüne Zahl) und speichert sie auf deiner NAS. Wenn du die Zahlen siehst – Glückwunsch, dein erstes Archiv lebt.
3.2.5 Workflow veröffentlichen
Stelle den Schedule Trigger auf 2 Stunden und aktiviere den Workflow über Publish.
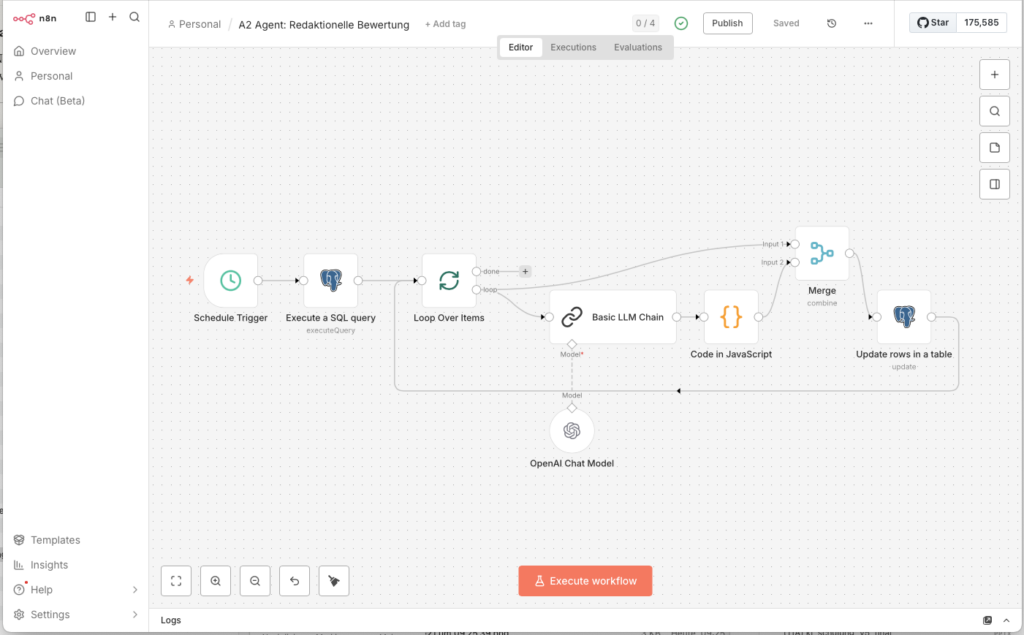
3.3 Agent 2: Redaktionelle Einzelbewertung
Ulf: „Okay, wir haben jetzt ein Archiv voller Artikel, aber wie wissen wir, welche davon gut sind?“
Tanja: „Indem wir eine KI fragen, die liest Titel und Beschreibung, gibt eine Note von 0 bis 10 und ordnet den Artikel einer Kategorie zu.“
Bernd schnaubt. „Ich bewerte das manuell. Mit Bauchgefühl. Das ist viel besser als jede KI.“
Tanja: „Du hast gestern einen Artikel über ‚KI in der Landwirtschaft‘ als Top-News markiert. Wir schreiben einen Blog über KI-Tools für Wissensarbeiter.“
Stille.
Bernd: „Es war ein interessanter Artikel“.
3.3.1 Den Workflow starten
- Gehe zurück zur Workflow-Übersicht und klicke auf Create new workflow
- Nenne ihn oben links:
2 Agent: Redaktionelle Einzelbewertung - Füge einen Schedule Trigger hinzu:
- Trigger Interval: Hours
Stelle sie für den Anfang auf Manual (= Custom (Cron)), damit wir beim Bauen nicht ständig neue Daten ziehen. Später stellen wir sie auf „Alle 4 Stunden“ - Hours Between Triggers: 4
- Trigger at Minute: 0
- Trigger Interval: Hours
3.3.2 Datensatz aus Datenbank auslesen
- Füge eine Postgres-Node „Execute a SQL query“ hinzu:
- Credtial to connect with:
n8n-postgres - Query:
- Credtial to connect with:
SELECT id, title, description, url
FROM ki_artikel
WHERE status = 'NEU'
LIMIT 5;Mit LIMIT 5 starten wir ruhig – zum Testen reichen fünf Artikel. Später kannst du das Limit hochsetzen.
3.3.3 Loop einbauen
Die KI soll jeden Artikel einzeln bewerten – nicht alle auf einmal. Dafür kommt ein Loop-Node:
- Node: Loop Over Items
- Bartch Size: 1
- Done: bleibt leer
- Loop: nächster Knoten
Stell es dir vor wie ein Fließband: Artikel rein, bewerten, nächster Artikel.
3.3.4 Basic LLM Chain
Bernd: „Moment, wenn wir schon KI einsetzen, dann richtig. Ich würde hier GPT-5.2 nehmen. Das Beste vom Besten.“
Tanja dreht sich zu ihm. „Wie viele Artikel bewertet Agent 2 pro Tag?“
Bernd zuckt die Schultern. „Weiß ich nicht. Hundert? Zweihundert?“
Tanja: „Nehmen wir 150. GPT-5.2 kostet etwa $15 pro Million Input-Token. GPT-4o-mini kostet $0,15 – also hundertmal weniger.“ Sie schreibt zwei Zahlen auf einen Zettel. „Pro Artikel gehen wir von rund 500 Token für Titel und Beschreibung aus, plus nochmal 200 Token Ausgabe. Bei 150 Artikeln täglich und 30 Tagen im Monat kommst du mit GPT-4o auf etwa 33 Euro im Monat. Nur für die Bewertung.“
Ulf: „Und mit mini?“.
Tanja: „33 Cent“
Kurze Pause.
Bernd: „Aber, GPT-5.2 ist doch viel schlauer.“
Tanaj: „Für diese Aufgabe brauchen wir kein Genie, wir fragen: Ist dieser Artikel relevant? Welche Kategorie? Begründung in 25 Wörtern. Das ist eine strukturierte Klassifikationsaufgabe – kein Raketenantrieb, kein Gedicht, keine Rechtsberatung. GPT-4o-mini löst das genauso zuverlässig wie der große Bruder. Der Unterschied: Geschwindigkeit und Preis.“
Ulf: „Wann würde man dann das große Modell nehmen?“
Tanja: „Agent 4. Artikel schreiben. Da steckt Nuancen drin, Argumentation, Stil, Urheberrechtssensibilität. Dafür nehmen wir Claude Sonnet. Aber für ‚Note 0 bis 10 vergeben‘ – da ist mini schlau genug und 100-mal günstiger.“
Bernd schaut auf seinen Bildschirm. „Ich hätte trotzdem das große genommen.“
Tanj: „Das weiß ich, deshalb entscheide ich das.“
Jetzt kommt das Herzstück von Agent 2. Warum der „Basic LLM Chain“ und nicht der „AI Agent“? Ganz einfach: Der AI Agent ist wie ein Allrounder, der theoretisch Werkzeuge benutzen, recherchieren und selbst entscheiden kann. Wir brauchen hier aber nur einen einzigen Durchgang: Text rein -> Prompt anwenden -> JSON raus. Der Basic LLM Chain macht genau das – schneller und günstiger.
- Node: Basic LLM Chain
- Source for Prompt (User Message): Define below
- Prompt (User Message):
Rolle: Du bist eine kritische Analystin und KI-Trend-Scout.
Aufgabe: Bewerte den folgenden Artikel nach seinem Nutzen für interessierte KI-Anwender, die KI im Alltag (privat & beruflich) besser einsetzen und zukünftige Entwicklungen verstehen wollen. Ordne den Artikel zudem präzise den vorgegebene Subkategorien zu.
Input-Daten:
Titel: {{ $json.title }}
Beschreibung: {{ $json.description }}
---
### 1. Strenge Bewertungs-Logik (Skala 0 bis 10):
KI-Anwendungsrelevanz (Nutzwert heute):
- 0–1: Kein KI-Bezug oder rein abstrakt / technisch ohne Nutzenableitung.
- 2–4: KI wird erwähnt, aber ohne konkrete Nutzungsideen.
- 5–6: Liefert Beispiele, Tools, Produktivitäts- oder Alltagsbezug.
- 7–8: Klare, übertragbare Use-Cases (Arbeit, Lernen, Organisation, Kreativität).
- 9–10: Hoher Mehrwert: verändert konkret, wie man KI sinnvoll nutzt.
KI-Entwicklungsbedeutung (Blick in die Zukunft):
- 0–1: Unbedeutend oder reine Randnotiz.
- 2–4: Allgemeine Entwicklung ohne Tiefgang.
- 5–6: Relevanter Trend (z. B. Copilots, Regulierung, KI im Alltag).
- 7–8: Wichtige Weichenstellung (z. B. neue Einsatzfelder, starke Verbreitung).
- 9–10: Paradigmenwechsel mit klaren Folgen für Nutzer:innen.
---
### 2. Subkategorien (Wähle EXAKT einen Namen aus dieser Liste):
1. Anwendungsfälle & Best Practices (Konkretisierung: Praxisbeispiele, Alltag/Beruf, Produktivitäts-Szenarien)
2. Prompting (Konkretisierung: Operative Assets: Gebrauchsfertige Vorlagen, konkrete Befehlsketten und „Copy & Paste“-Prompts für sofortige Ergebnisse)
3. Lernen & Skill-Aufbau (Konkretisierung: Methodisches Wissen: Tutorials, Lernpfade, Konzepte wie Chain-of-Thought, Methodik, Erklärungen zum „Mitdenken“)
4. Tools & Produkt-Updates (Konkretisierung: Software-Releases, neue Funktionen, UI-Änderungen)
5. Automatisierung & Agenten (Konkretisierung: n8n/Zapier Workflows, Agent-Flows, APIs, Prozessautomatisierung)
6. KI-Kreativität (Konkretisierung: Fokus auf generative Medien-Erstellung: Bild, Video, Audio, Design jenseits reiner Text-Assistenz)
7. News & Entwicklungen (Konkretisierung: Markt- & Strategie-News, Trends, allgemeine Einordnung)
8. Modelle & Open Source (Konkretisierung: LLMs, Open-Source-Modelle, GitHub-Projekte, technischer Deep Dive)
9. Hardware & Lokale KI (Konkretisierung: Gadgets, AI-PCs, Chips wie Nvidia/NPU, Local-AI-Setups)
10. Sicherheit & Privacy (Konkretisierung: Datenschutz, Security, sichere KI-Nutzung)
11. Ethik, Recht & Politik (Konkretisierung: AI Act, Regulierung, Governance, Deepfakes)
12. Kein KI-Fokus (Fokus: Default-Kategorie für alle Inhalte ohne klaren KI-Nutzen oder KI-Bezug, allgemeine Technik-News oder Off-Topic)
WICHTIG: Wenn die Sub-Kategorie "Kein KI-Fokus" gewählt wird, dann müssen Anwendungsrelevanz <= 1 UND Entwicklungsbedeutung <= 1 sein.
---
### 3. Ausgabe-Format & Validierung:
Erzeuge ausschließlich ein valides JSON-Objekt ohne Markdown-Formatierung.
WICHTIG: Das Feld "subkategorie" MUSS buchstabengetreu mit einem der oben genannten 12 Namen übereinstimmen. Ändere keine Sonderzeichen, erfinde keine neuen Namen und achte auf exakte Groß-/Kleinschreibung.
STRICT OUTPUT RULES:
- Gib GENAU EIN JSON-Objekt aus.
- Kein Text vor oder nach dem JSON.
- KEIN Komma nach der schließenden }.
- Verwende ausschließlich doppelte Anführungszeichen für JSON.
{
"anwendungsrelevanz": Zahl,
"entwicklungsbedeutung": Zahl,
"subkategorie": "EXAKTER_NAME_AUS_LISTE",
"begruendung": "Maximal 25 Wörter. Begründung der Kategorie + Begründung der Anwendungsrelevanz und Entwicklungsbedeutung."
}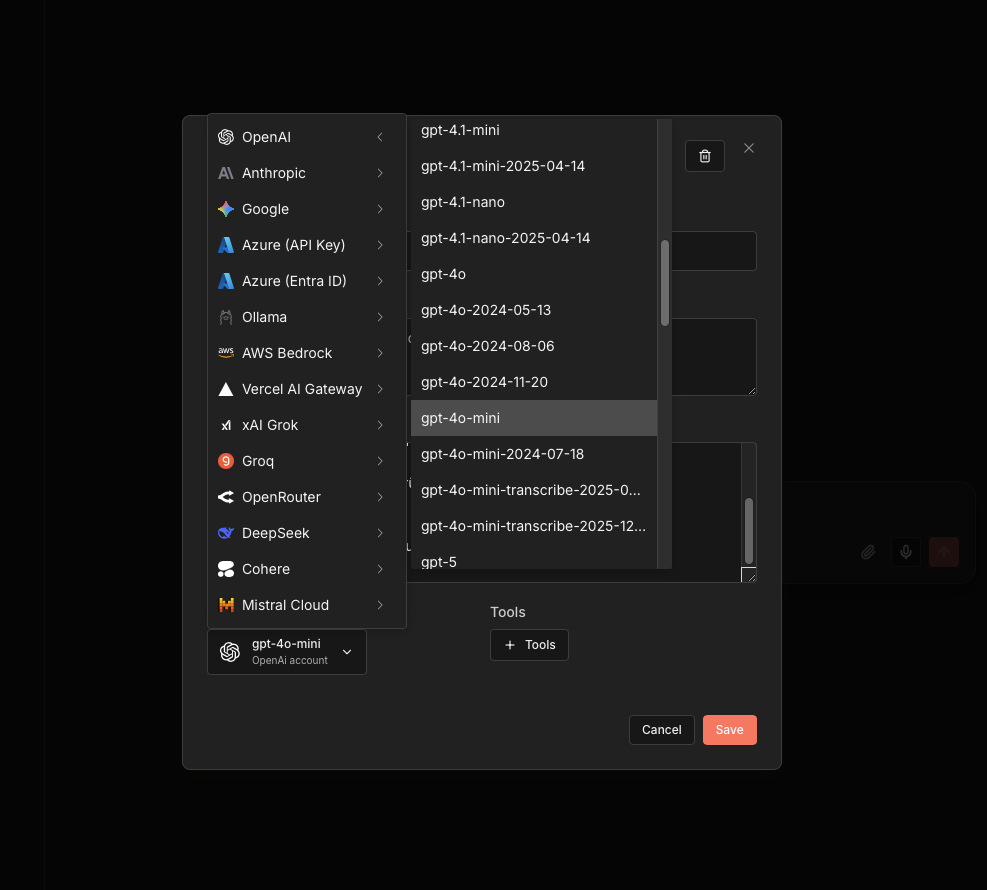
Verbinde den Basic LLM Chain mit dem OpenAI Chat Model:
- Node: OpenAI Chat Model
- Credential to connect with: OpenAI account
- Model:
gpt-4o-mini - Use Response API: active
3.3.5 Code in JavaScript
GPT-4o-mini liefert manchmal JSON mit Markdown-Umrandung zurück (Backticks, json-Tags). Dieser Code-Node räumt das auf und berechnet den Gesamtscore:
- Node: Code in JavaScript
- Mode: Run Once for Each ITem
- Language: JavaScript
let raw = $json.text;
// Entfernt Backticks und säubert den Text
let clean = raw.replace(/```json/g, "").replace(/```/g, "").trim().replace(/,\s*$/, "");
let data = JSON.parse(clean);
// Falls die KI es in "output" verpackt hat
if (data.output) data = data.output;
// Nur EIN return-Block mit allen Feldern:
return {
anwendungsrelevanz: Number(data.anwendungsrelevanz),
entwicklungsbedeutung: Number(data.entwicklungsbedeutung),
subkategorie: data.subkategorie,
begruendung: data.begruendung,
// Hier passiert die wichtige Berechnung für DECIMAL(3,1)
score_gesamt: (Number(data.anwendungsrelevanz)*6 + Number(data.entwicklungsbedeutung)*4)/10
};Die Formel am Ende ist keine Magie: Anwendungsrelevanz zählt sechsfach, Entwicklungsbedeutung vierfach. Das teilen wir durch 10 – fertig ist ein Score zwischen 0 und 10, gespeichert als DECIMAL(3,1).
3.3.6 Merge Combine
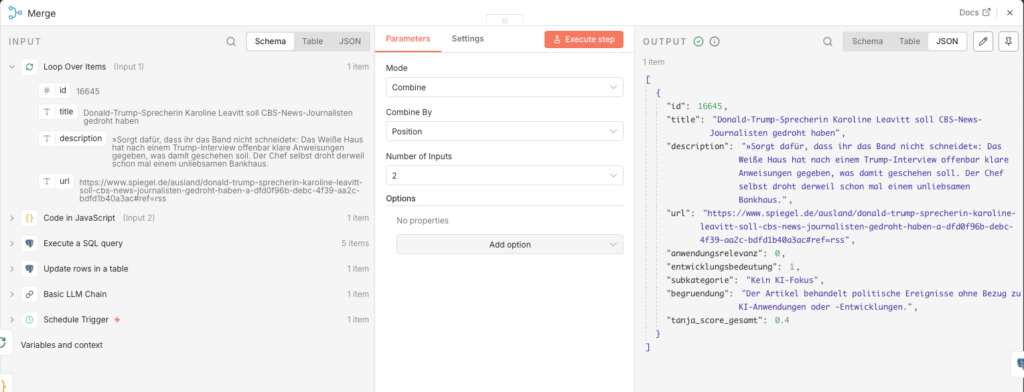
Jetzt haben wir ein Problem: Der Bewertungs-Code kennt nur die KI-Ergebnisse, aber nicht mehr die Datenbank-ID des Artikels. Ohne die ID können wir den Datensatz nicht aktualisieren. Der Merge-Node löst das: Er fügt die Datenbankfelder (inkl. id) und die Bewertungsfelder zu einem gemeinsamen Datensatz zusammen.
- Node: Merge Combine
- Mode: Combine
- Combine by: Position
- Number of Inputs: 2
Verbinde die zwei Eingänge: Ausgang „loop“ des Loop Over Items-Nodes → Eingang 1 des Merge; Ausgang des Code-Nodes → Eingang 2 des Merge.
3.3.7 In Datenbank speichern
- Füge einen Postgres-Node am Ende hinzu:
- Node: Update rows in a table
- Credential to connect with:
n8n-postgres - Operation: Update
- Schema: public
- Table:
ki_artikel - Mapping Column Mode: Map Each Column Manually
- Columns to match on: id
| Feld | Value |
|---|---|
| id (using to match) | {{ $json.id }} |
| score_relevanz | {{ $json.anwendungsrelevanz }} |
| score_bedeutung | {{ $json.entwicklungsbedeutung }} |
| score_gesamt | {{ $json.score_gesamt }} |
| bewertung_begruendung | {{ $json.begruendung }} |
| status | BEWERTET |
| subkategorie | {{ $json.subkategorie }} |
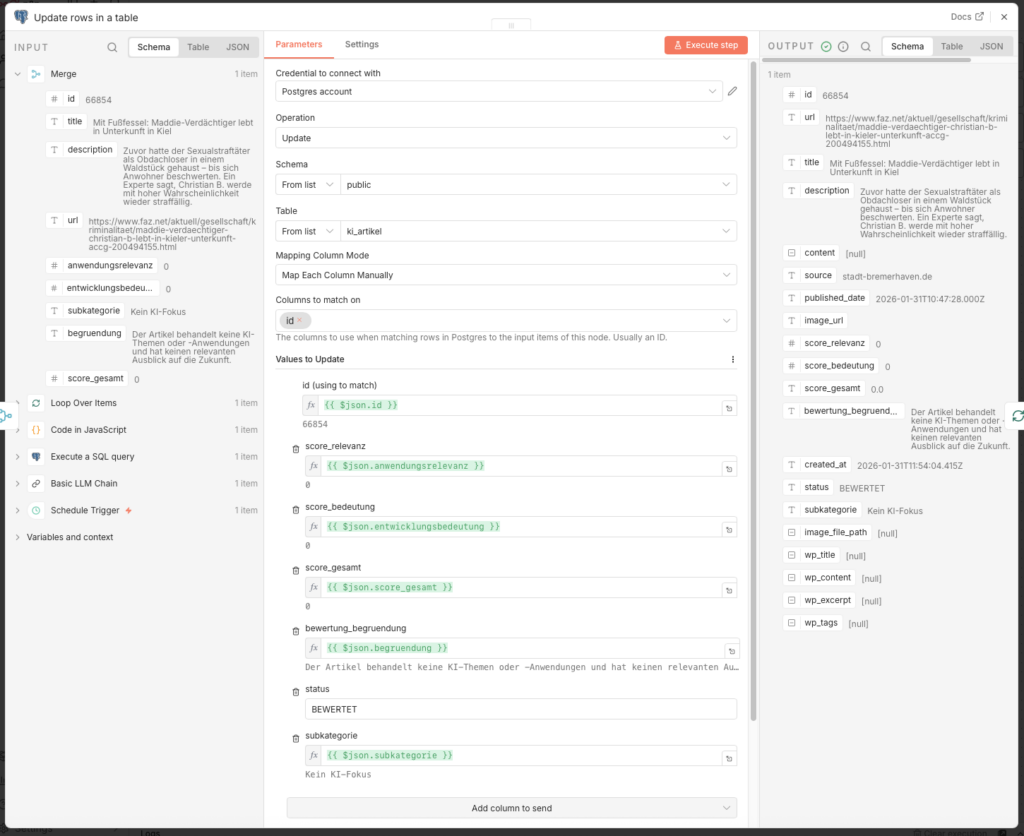
Verbinde den Ausgang dieses Nodes zurück mit dem Eingang des Loop Over Items-Nodes – so läuft die Schleife für alle abgerufenen Artikel durch.
3.3.8 Workflow veröffentlichen
Stelle den Schedule Trigger auf 4 Stunden und aktiviere den Workflow über Publish.
3.4 Dashboard mit Metabase (Optional)
Ulf: „Moment, ich will mal sehen, was da in meiner Datenbank passiert. Wie schaue ich da rein?“
Tanja: „Mit Metabase, das ist ein Dashboard-Tool, das sich direkt an deine PostgreSQL-Datenbank hängt. Du kannst dann Fragen stellen wie: ‚Wie viele Artikel wurden heute bewertet?‘ und bekommst eine Tabelle oder ein Diagramm zurück.“
Bernd: „Ich guck einfach direkt in die Datenbank, mit dem Terminal. Ist professioneller.“
Ulf: „Du hast letzte Woche eine Tabelle aus Versehen gelöscht, weil du ein Leerzeichen vergessen hast.“
Bernd hustet.
Metabase brauchst du nicht zwingend – die Agenten laufen auch ohne. Aber es ist hilfreich, wenn du einen schnellen Überblick willst: Wie viele Artikel wurden eingelesen? Wie verteilen sich die Scores? Welche Kategorien dominieren?
3.4.1 Ordnerstruktur vorbereiten
Metabase möchte seine eigenen Einstellungen (welche Fragen du gestellt hast, wie dein Dashboard aussieht) irgendwo speichern. Standardmäßig macht es das innerhalb des Containers. Wenn du den Container löschst oder updatest, ist dein Dashboard weg.
Damit dein Dashboard „ewig“ lebt, solltest du unter Volume-Einstellungen (im nächsten Schritt) einen Ordner auf deiner NAS verknüpfen:
- Ordner: Erstelle auf deiner NAS einen Ordner
docker/metabase.
3.4.2 Metabase einrichten
- Image Name:
metabase/metabase - Port: standardmäßig 3000
Vorgehensweise:
- Lade das Image im Container Manager auf der Synology herunter
2. Führe das Image aus: metabase/metabase:latest → Ausführen
- Containername:
metabase-newsroom - Port: 3000
- Volume-Einstellungen: + Ordner hinzufügen
- Ordner
docker/metabaseauswählen (vorher auf der NAS erstellen) - Mount-Pfad:
/metabase.dbeintragen
- Ordner
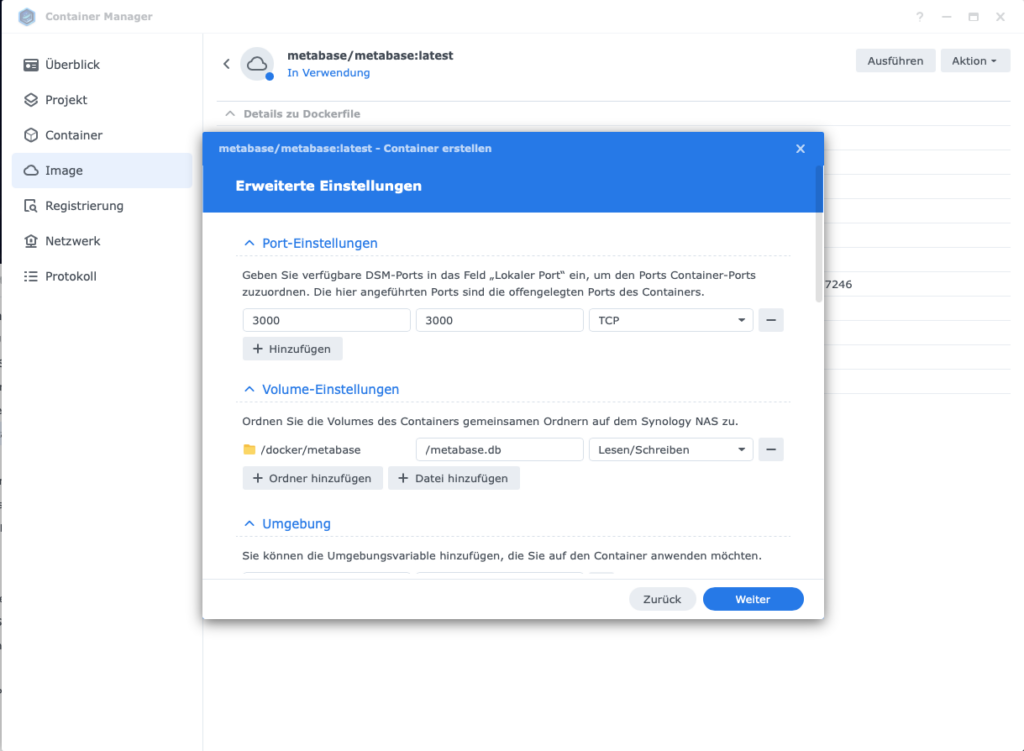
- Umgebungsvariable
GIT_COMMIT_SHA:unknowneintragen
- Container starten
Wichtig: Falls die Firewall auf deiner Diskstation aktiv ist, lege eine Regel für Port 3000 (Protokoll TCP) an – sonst kommst du über den Browser nicht auf Metabase.
Metabase läuft unter http:// (nicht https://). Öffne http://<deine-Synology-IP>:3000 im Browser. Beim ersten Start führt dich ein Setup durch die Datenbankverbindung:
- Database type: PostgreSQL
- Display name: z. B. „KI News Datenbank“
- Host: Containername deiner Postgres-Instanz (z. B.
n8n_db) - Port:
5432 - Database name:
postgres - Username: dein Postgres-Benutzername
- Password: dein Postgres-Passwort
Deine erste SQL-Auswertung erstellst du über + NEU -> >_ SQL-Abfrage. Diese Query gibt dir einen ersten Tagesüberblick:
SELECT
DATE(created_at) AS datum,
-- 1) Wie viele RSS-Feeds wurden eingelesen?
COUNT(*) AS eingelesen_gesamt,
-- 2) Wie viele davon wurden bewertet?
COUNT(*) FILTER (WHERE status = 'bewertet') AS bewertet,
-- 3) Verteilung der Scores (Umwandlung in Zahlenwert mit ::float)
COUNT(*) FILTER (WHERE score_gesamt::float BETWEEN 0 AND 2.9) AS "Score_0_bis_2",
COUNT(*) FILTER (WHERE score_gesamt::float BETWEEN 3 AND 7.9) AS "Score_3_bis_7",
COUNT(*) FILTER (WHERE score_gesamt::float >= 8) AS "Score_8_bis_10"
FROM ki_artikel
GROUP BY DATE(created_at)
ORDER BY datum DESC;3.5 Agent 3: Content-Recherche
Ulf: „Wir haben jetzt bewertete Artikel, was kommt jetzt?“
Tanja: „Jetzt wird es interessant, Agent 3 nimmt die besten Artikel – die mit Score 7,5 oder höher – und recherchiert dazu. Er lädt den Originaltext, sucht verwandte Quellen im Web und lässt GPT-4o-mini daraus einen strukturierten Hintergrundtext schreiben.“
Ulf: „Moment, kann die KI nicht einfach selbst im Internet suchen? Warum der Umweg über Tavily?“
Tanja: „Gute Frage. Schauen wir uns das an.“
3.5.1 Den Workflow starten
- Gehe zurück zur Workflow-Übersicht und klicke auf Create new workflow
- Nenne ihn oben links:
A3 Agent: Content-Recherche - Füge einen Schedule Trigger hinzu:
- Trigger Interval: Hours
- Stelle zunächst auf Manual zum Testen
- Hours Between Triggers: 23
- Trigger at Minute:
3.5.2 Datensatz aus Datenbank auslesen
- Füge eine Postgres-Node hinzu:
- Node: Execute a SQL query
- Credential to connect with:
n8n-postgres - Query:
SELECT a.id, a.url, a.title, a.description
FROM ki_artikel a
LEFT JOIN ki_story s ON s.primary_artikel_id = a.id
WHERE a.score_gesamt >= 7.5
AND s.id IS NULL
AND (a.status IS NULL OR a.status <> 'ANGEREICHERT')
LIMIT 5;Hinweis: Wir holen nur Artikel mit einem Gesamtscore von mindestens 7.5 – das sind die wirklich relevanten Treffer, die eine aufwendige Recherche wert sind. Das LIMIT 5 hält die Laufzeit beim ersten Testen überschaubar.
Der LEFT JOIN mit WHERE s.id IS NULL ist eine elegante Abkürzung: Er findet alle Artikel, zu denen es noch keine Story gibt – also genau die, die noch bearbeitet werden müssen.
Führe außerdem diese zwei Index-Befehle einmalig direkt in der Datenbank aus, um sie abzusichern:
CREATE UNIQUE INDEX IF NOT EXISTS ki_story_primary_uniq ON ki_story(primary_artikel_id);und
CREATE UNIQUE INDEX IF NOT EXISTS idx_ki_artikel_url_normalized ON ki_artikel(url_normalized);3.5.3 Loop einbauen
Damit n8n jeden Artikel einzeln abarbeitet, kommt als nächstes der Loop-Knoten:
- Node: Loop Over Items (Split In Batches)
- Batch Size: 1
- Knoten-Ausgang Done: bleibt leer
- Konten-Ausgang Loop: nächster Knoten
3.5.4 Website-Inhalt abrufen
Wir versuchen zunächst, den Volltext direkt von der Quellwebsite zu laden – als würde ein Mensch den Artikel öffnen und lesen.
- Füge einen HTTP Request-Node hinzu:
- Method: GET
- URL:
={{ $json.url }} - Add Options → Response Format: Text
- Send Headers: ON
| Header Name | Value |
|---|---|
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36 |
| Accept | text/html |
| Accept-Language | de-DE,de;q=0.9,en;q=0.8 |
Diese Header sind wichtig: Viele Websites liefern schönere Inhalte, wenn die Anfrage wie ein echter Browser-Aufruf aussieht – statt wie ein nackter Bot.
- Füge einen Code Node (JavaScript) hinzu, der das rohe HTML in brauchbaren Fließtext verwandelt:
// n8n Code node (JavaScript)
// Erwartet HTML im Feld: $json.data (aus HTTP Request)
const html = ($json.data || '').toString();
// 1) Skripte/Styles entfernen
let cleaned = html
.replace(/<script\b[^<]*(?:(?!<\/script>)<[^<]*)*<\/script>/gi, ' ')
.replace(/<style\b[^<]*(?:(?!<\/style>)<[^<]*)*<\/style>/gi, ' ');
// 2) Häufige Layout-Blöcke grob entfernen (optional, aber hilfreich)
cleaned = cleaned
.replace(/<nav\b[^<]*(?:(?!<\/nav>)<[^<]*)*<\/nav>/gi, ' ')
.replace(/<header\b[^<]*(?:(?!<\/header>)<[^<]*)*<\/header>/gi, ' ')
.replace(/<footer\b[^<]*(?:(?!<\/footer>)<[^<]*)*<\/footer>/gi, ' ');
// 3) HTML-Tags -> Text (mit Zeilenumbrüchen an sinnvollen Stellen)
cleaned = cleaned
.replace(/<\/(p|div|br|li|h1|h2|h3|h4|h5|section|article)>/gi, '\n')
.replace(/<[^>]+>/g, ' ');
// 4) HTML Entities (minimal)
cleaned = cleaned
.replace(/ /g, ' ')
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/</g, '<')
.replace(/>/g, '>');
// 5) Whitespace normalisieren
cleaned = cleaned
.replace(/\r/g, '')
.replace(/[ \t]+/g, ' ')
.replace(/\n{3,}/g, '\n\n')
.trim();
// 6) Optional: begrenzen (für DB/LLM)
const maxLen = 20000;
const content_candidate = cleaned.slice(0, maxLen);
const content_candidate_len = content_candidate.length;
// --- Qualitäts-Check ---
const words = content_candidate.split(/\s+/).filter(w => w.length > 3);
const wordCount = words.length;
const avgWordLength =
words.reduce((sum, w) => sum + w.length, 0) / (wordCount || 1);
const badMarkers = [
'cookie', 'zustimmen', 'abo', 'newsletter', 'anzeigen',
'karriere', 'impressum', 'datenschutz', 'suche', 'login',
'heise+', 'jobs'
];
const badHits = badMarkers.filter(m =>
content_candidate.toLowerCase().includes(m)
).length;
const content_quality_ok =
content_candidate_len > 1500 &&
wordCount > 250 &&
avgWordLength > 4 &&
badHits < 5;
return [{
...$json,
content_candidate,
content_candidate_len,
content_quality_ok,
content_word_count: wordCount,
content_avg_word_len: avgWordLength,
content_bad_hits: badHits,
}];
Das Ergebnis enthält das Flag content_quality_ok. Ein brauchbarer Text braucht mindestens 1.500 Zeichen, 250 Wörter und darf nicht von Boilerplate-Begriffen wie „Cookie“ oder „Impressum“ dominiert sein. Das Flag dient als Metainformation; die Tavily-Recherche läuft in jedem Fall danach – der Web-Kontext ist die eigentliche Basis für den LLM-Text.
3.5.5 Warum Tavily statt OpenAI-Websuche?
Ulf: „Kurze Frage, kann ich nicht einfach GPT mit Internetzugang nehmen? Dann brauche ich Tavily gar nicht.“
Tanja: „Du kannst, aber schau dir kurz die Kosten an.“
| Feature | Basic LLM Chain | AI Agent + Tavily | AI Agent + Serper/Brave | OpenAI Search-Preview |
|---|---|---|---|---|
| Internetzugriff | Nein | Ja (inkl. Textauszüge) | Ja (nur Links) | Ja (integriert) |
| Kosten pro Suche | – | 0 Cent (bis 1.000/Monat kostenlos) | 0,1 – 1,5 Cent | 3 – 10 Cent |
| Ergebnis-Qualität | Nur wenn manuell gefüttert | Sehr gut – Inhalt bereits aufbereitet | Gut – Rohlinks, kein Textinhalt | Sehr gut |
| Kontrolle | Voll | Voll | Voll | Begrenzt |
| Setup-Aufwand | Minimal | Gering (1 API Key) | Gering (1 API Key) | Minimal |
Ulf: „Okay, ich versteh das noch nicht ganz,“ und zeigt auf die Tabelle. „Serper und Brave liefern auch Suchergebnisse. Warum ist Tavily besser?“
Tanja: „Stell dir vor, du schickst einen Praktikanten los, um Informationen über ein Thema zu sammeln. Serper und Brave kommen zurück mit einem Stapel Zeitungsadressen. Tavily kommt zurück mit den ausgeschnittenen Artikeln. Bereits lesbar, bereits sortiert.“
Ulf runzelt die Stirn. „Also liefert Tavily den Inhalt der Seiten gleich mit?“
Tanja: „Genau. Serper und Brave geben dir nur Links – du musst jede Seite noch selbst aufrufen und den Text extrahieren. Tavily liefert bereits aufbereitete Textauszüge. GPT-4o-mini bekommt also sauberen Kontext statt rohem HTML-Müll. Das spart Token – und bessere Eingabe bedeutet bessere Ausgabe.“
Bernd: „Klingt nach wenig Unterschied, ich würde einfach OpenAIs eingebaute Websuche nehmen. Weniger Gedöns.“
Tanja: „Kostet dich 3 bis 10 Cent pro Suche, Tavily ist bis tausend Suchen im Monat kostenlos. Danach 1,5 Cent. Das ist Faktor 10 bis 30 günstiger, bei gleicher oder besserer Qualität für unseren Anwendungsfall.“
Ulf: „Tausend Suchen reichen uns?“
Tanja: „Wir recherchieren täglich für maximal einen Artikel, mit bis zu 20 Tavily-Treffern pro Durchlauf. Das sind rund 600 Suchen im Monat. Passt locker ins kostenlose Kontingent.“
Bernd tippt kurz auf seinem Handy. „Okay, Tavily.“
Tanja: „Danke“.
3.5.6 Tavily Search einrichten
- Erstelle dir einen Account auf app.tavily.com und kopiere deinen API Key
- Füge in n8n den Node Search: Tavily hinzu
- Erstelle unter Credential to connect with ein neues Credential mit deinem API Key
- Konfiguriere den Node:
- Query:
{{
(
($('Execute a SQL query').item.json.title || '') + ' ' +
($('Execute a SQL query').item.json.description || '')
).slice(0, 380)
}}- Konfiguriere den Node:
- Add Options → Search Depth: Advanced
- Add Options → Max Results: 20
Die Query kombiniert Titel und Beschreibung des Artikels und schneidet bei 380 Zeichen ab. Mit Advanced und 20 Ergebnissen holen wir das Maximum aus dem Tavily-Free-Kontingent.
3.5.7 Schlechte URLs aussortieren
Tavily liefert manchmal SEO-Schrottseiten, Feed-Aggregatoren oder themenfremd. Ein Code-Node filtert diese heraus, bevor sie die Datenbank verschmutzen:
- Node: Code (JavaScript)
- Mode: Run Once for All Items
const input = $input.first().json;
const list = Array.isArray(input.results) ? input.results : [];
// --- Konfiguration ---
const BLOCKED_DOMAINS = [
'feed-reader.net', 'rssingn.com', 'finanztrends.de',
'it-daily.net', 'possible.fm', 'edu.ly',
];
const BAD_TITLE_PATTERNS = [
'die besten', 'tools im vergleich', 'im vergleich', 'ranking', 'best of',
];
const MIN_CONTENT_LENGTH = 250;
const MIN_SCORE = 0.55;
function host(u) {
try { return new URL(u).hostname.replace(/^www\./, ''); } catch { return ''; }
}
const kept = [];
for (const r of list) {
const url = String(r.url || '').toLowerCase();
const title = String(r.title || '').toLowerCase();
const content = String(r.content || '').toLowerCase();
const h = host(url);
let reason = null;
if (!url || !title) reason = 'missing url/title';
else if (BLOCKED_DOMAINS.some(d => h.includes(d))) reason = 'blocked domain';
else if (BAD_TITLE_PATTERNS.some(p => title.includes(p))) reason = 'seo/list title';
else if (content.length < MIN_CONTENT_LENGTH) reason = 'too short content';
else if (typeof r.score === 'number' && r.score < MIN_SCORE) reason = 'low score';
if (!reason) kept.push({ ...r, _quality_flag: 'accepted' });
}
// Fallback: wenn alles rausfliegt, nimm Top 5 nach Score
const final = kept.length > 0
? kept
: [...list].sort((a, b) => (b.score ?? 0) - (a.score ?? 0)).slice(0, 5)
.map(r => ({ ...r, _quality_flag: 'fallback' }));
return final.map(r => ({
json: {
...r,
_debug: {
input_count: list.length,
kept_count: kept.length,
}
}
}));Der Fallback am Ende ist wichtig: Wenn alle Treffer rausgefiltert würden, nimmt der Code trotzdem die Top 5 nach Score – damit der Workflow nie komplett leer weiterläuft.
3.5.8 Tavily-Treffer in der Datenbank speichern
Die gefundenen Quellen werden doppelt verwertet: als Kontext für das LLM (nächster Schritt) und als eigene Datensätze in der Datenbank. Dafür brauchen wir drei Nodes hintereinander.
Node 1: Prepare Tavily Results (Code in JavaScript)
Dieser Code normalisiert die URLs der Tavily-Treffer und bereitet die Felder für die Datenbank vor – analog zur URL-Normalisierung aus Agent 1:
function normalizeUrl(input) {
try {
const url = new URL(input.startsWith('http') ? input : 'https://' + input);
url.hash = '';
const dropKeys = new Set(['fbclid','gclid','mc_cid','mc_eid','msclkid','utm_source']);
for (const k of Array.from(url.searchParams.keys())) {
if (k.toLowerCase().startsWith('utm_') || dropKeys.has(k.toLowerCase()))
url.searchParams.delete(k);
}
url.hostname = url.hostname.replace(/^www\./i, '').toLowerCase();
url.protocol = 'https:';
if (url.pathname === '/') url.pathname = '';
return url.toString();
} catch (e) { return input; }
}
function extractHost(input) {
try { return new URL(input).hostname.replace(/^www\./i, '').toLowerCase(); }
catch (e) { return 'unknown'; }
}
const fromId = $('Execute a SQL query').item?.json?.id ?? null;
const results = items.every(it => typeof it?.json?.url === 'string')
? items.map(it => it.json)
: (Array.isArray(items?.[0]?.json?.results) ? items[0].json.results : []);
return results.filter(r => r?.url).slice(0, 10).map((r, idx) => {
const norm = normalizeUrl(r.url);
const host = extractHost(norm || r.url);
return { json: {
from_artikel_id: fromId,
relation_type: 'tavily_related',
query: items?.[0]?.json?.query ?? '',
rank: idx + 1,
score: r.score ?? null,
url: r.url,
url_normalized: norm,
title: r.title ?? '(no title)',
description: (r.content ?? '').slice(0, 800),
source: host,
source_type: 'tavily',
}};
});Node 2: Upsert Tavily Article (Postgres – Execute a SQL query)
Jeder gefundene Treffer landet als eigener Datensatz in ki_artikel. Durch ON CONFLICT wird ein bereits bekannter Artikel nicht doppelt eingetragen, sondern nur fehlende Felder ergänzt:
INSERT INTO ki_artikel (
url, url_normalized, title, description,
source, published_date, image_url, source_type, status, first_seen_at
)
VALUES (
'{{ ($json.url || "").replace(/'/g, "''") }}',
'{{ ($json.url_normalized || "").replace(/'/g, "''") }}',
'{{ ($json.title || "").replace(/'/g, "''") }}',
'{{ ($json.description || "").replace(/'/g, "''") }}',
'{{ ($json.source || "").replace(/'/g, "''") }}',
NULL, NULL, 'tavily', 'ANGEREICHERT', now()
)
ON CONFLICT (url_normalized)
DO UPDATE SET
title = COALESCE(NULLIF(ki_artikel.title,''), EXCLUDED.title),
description = COALESCE(NULLIF(ki_artikel.description,''), EXCLUDED.description),
source = COALESCE(NULLIF(ki_artikel.source,''), EXCLUDED.source),
status = COALESCE(NULLIF(ki_artikel.status,''), 'ANGEREICHERT')
RETURNING id;Node 3: Upsert Tavily Edge (Postgres – Execute a SQL query)
Die Verbindung zwischen dem Ausgangsartikel und dem gefundenen Tavily-Treffer wird in ki_artikel_edges gesichert:
INSERT INTO ki_artikel_edges (
from_artikel_id, to_artikel_id, relation_type, query, rank, score, retrieved_at
)
VALUES (
{{ $node["Prepare Tavily Results"].json.from_artikel_id }},
{{ $node["Upsert Tavily Article"].json.id }},
'{{ (($node["Prepare Tavily Results"].json.relation_type) || "tavily_related").replace(/'/g, "''") }}',
'{{ (($node["Prepare Tavily Results"].json.query) || "").replace(/'/g, "''") }}',
{{ $node["Prepare Tavily Results"].json.rank || 1 }},
{{ $node["Prepare Tavily Results"].json.score ?? 'NULL' }},
now()
)
ON CONFLICT (from_artikel_id, to_artikel_id, relation_type)
DO UPDATE SET
rank = EXCLUDED.rank,
score = EXCLUDED.score,
query = EXCLUDED.query,
retrieved_at = now();3.5.9 LLM-Kontext aufbereiten
Parallel zur Datenbankspeicherung bereitet ein Edit Fields-Node den kombinierten Kontext für GPT-4o-mini auf:
- Node: Edit Fields
- Field Name:
llm_context - Type: String
- Value (Expression):
=RSS ARTICLE
Title: {{ $('Loop Over Items').item.json.title }}
Description: {{ $('Loop Over Items').item.json.description }}
WEB SEARCH CONTEXT
={{
"RSS ARTICLE\nTitle: " +
$('Loop Over Items').item.json.title +
"\nDescription: " +
$('Loop Over Items').item.json.description +
"\n\nWEB SEARCH CONTEXT\n" +
($node["Search: Tavily"].json.results || [])
.slice(0, 10)
.map((r, i) => "[Source " + (i+1) + "]\n" + (r.content || ""))
.join("\n\n")
}}Damit hat die KI sowohl den Original-RSS-Artikel als auch bis zu 10 aufbereitete Webseitentexte aus Tavily als Kontext.
3.5.10 Hintergrundtext mit GPT-4o-mini erstellen
- Node: Basic LLM Chain
- Source for Prompt: Define below
- Prompt (User Message):
Du erhältst einen Artikel aus einem RSS-Feed sowie zusätzlichen Web-Kontext.
Aufgabe:
- Beschreibe das Thema inhaltlich breiter und tiefer.
- Erkläre Hintergründe, technische Zusammenhänge und Einordnung.
- Struktur: 1) Kurzüberblick (3-4 Sätze) 2) Details (5-10 Bulletpoints) 3) Bedeutung/Implikationen (3 Bulletpoints).
- Keine Quellenangaben, keine Spekulationen.
TEXT:
{{ $json.llm_context }}Den Basic LLM Chain mit dem OpenAI Chat Model verbinden:
- Node: OpenAI Chat Model
- Credential to connect with: OpenAI account
- Model: gpt-4o-mini
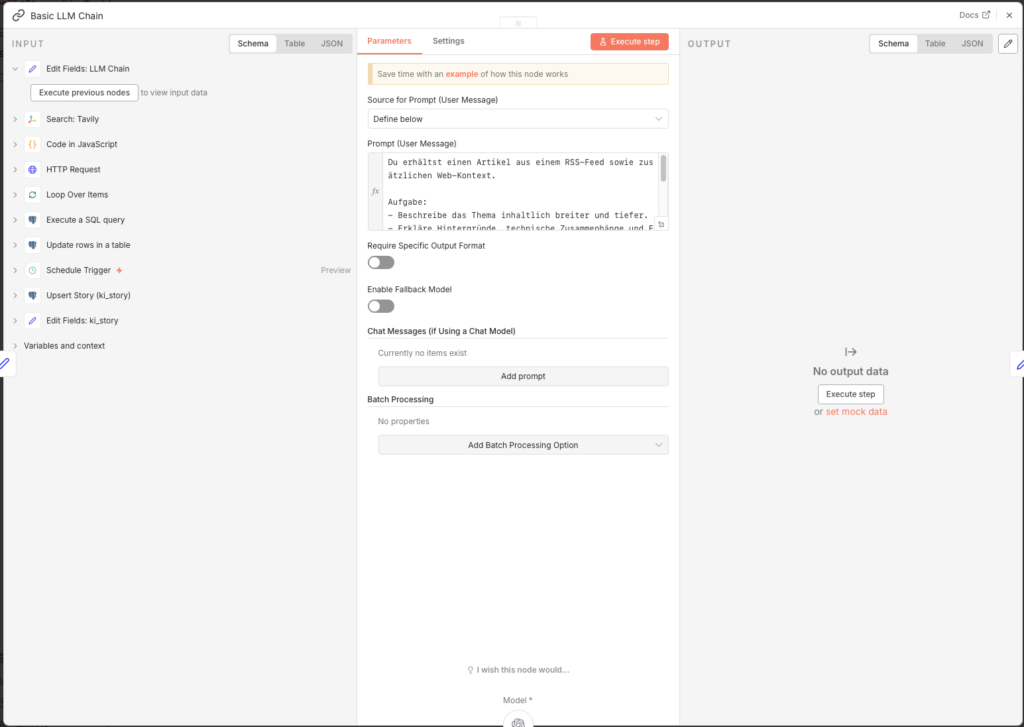
3.5.11 Story-Felder aufbereiten
Ein Edit Fields-Node fasst das LLM-Ergebnis zusammen mit Metadaten aus dem Loop:
- Node: Edit Fields (Name:
Edit Fields: ki_story)
| Name | Type | Value |
|---|---|---|
| id | Number | ={{ $('Loop Over Items').item.json.id }} |
| content_enriched | String | ={{ $json.text }} |
| enrichment_source | String | search_llm |
| tavily_link_count | String | ={{ $items("Code in JavaScript: schlechte url aussortieren").length }} |
| score_gesamt_enriched | Number | ={{ (Math.round(($('Loop Over Items').item.json.score_gesamt | 0) * 10) + ($items("Code in JavaScript: schlechte url aussortieren").length | 0)) / 10 }} |
Der score_gesamt_enriched kombiniert den ursprünglichen Bewertungsscore mit der Anzahl brauchbarer Tavily-Quellen – je mehr gute Quellen gefunden wurden, desto höher steigt der Score leicht an.
3.5.12 Story in Datenbank speichern
- Node: Postgres – Execute a SQL query (Name:
Upsert Story (ki_story))
INSERT INTO ki_story (
primary_artikel_id,
content_enriched,
enrichment_source,
tavily_link_count,
score_gesamt_enriched,
status,
updated_at
)
VALUES (
{{ $json.id }},
'{{ ($json.content_enriched || "").replace(/'/g, "''") }}',
'{{ ($json.enrichment_source || "").replace(/'/g, "''") }}',
{{ parseFloat($json.tavily_link_count) || 0 }},
{{ parseFloat($json.score_gesamt_enriched) || 0 }},
'ANGEREICHERT',
now()
)
ON CONFLICT (primary_artikel_id)
DO UPDATE SET
content_enriched = EXCLUDED.content_enriched,
enrichment_source = EXCLUDED.enrichment_source,
tavily_link_count = EXCLUDED.tavily_link_count,
score_gesamt_enriched = EXCLUDED.score_gesamt_enriched,
updated_at = now();3.5.13 Status aktualisieren und Loop schließen
Zum Abschluss wird der Status des Artikels in ki_artikel auf ANGEREICHERT gesetzt, damit Agent 4 ihn im nächsten Schritt aufgreifen kann.
- Füge einen Postgres-Node hinzu:
- Node: Update rows in a table
- Credential to connect with:
n8n-postgres - Operation: Update
- Schema: public
- Table: ki_artikel
- Mapping Column Mode: Map Each Column Manually
- Columns to match on: id
| Feld | Value |
|---|---|
| id (using to match) | ={{ $('Loop Over Items').item.json.id }} |
| status | ANGEREICHERT |
- Verbinde den Ausgang dieses Nodes zurück mit dem Eingang von „Loop Over Items“, damit alle weiteren Artikel aus der Datenbank der Reihe nach abgearbeitet werden.
3.5.14 Workflow veröffentlichen
Stelle den Schedule Trigger auf 23 Stunden und aktiviere den Workflow über Publish. Agent 3 läuft damit einmal täglich, reichert alle Artikel mit score_gesamt >= 7.5 an und übergibt sie bereit an Agent 4.
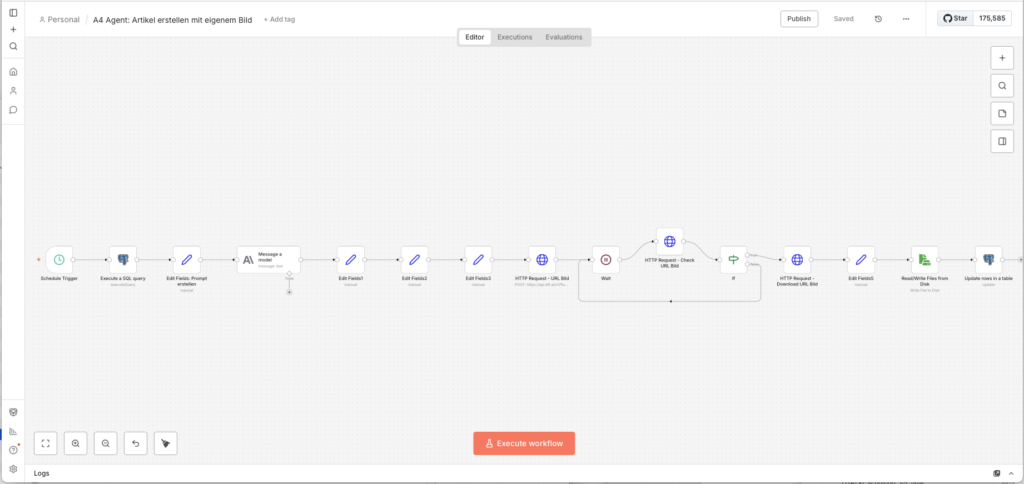
3.6 Agent 4: Artikel erstellen mit eigenem Bild
Ulf: „Jetzt wird es richtig spannend. Jetzt schreibt die KI den Artikel?“
Tanja: „Claude schreibt ihn, und Flux-2-Flex malt dazu ein Coverbild.“
Bernd schaut auf. „Ich habe meinen letzten Artikel einfach von einer anderen Website kopiert und ein bisschen umgeschrieben. Hat keiner gemerkt.“
Stille.
Tanja: „Das, nennt sich Urheberrechtsverletzung.“
Bernd: „Aber …“
Tanja: „Nein.“
3.6.1 Rechtliche Einschätzung
Vorab eine kurze persönliche Einschätzung als Laie, das ist keine Rechtsberatung:
Text: Die KI darf Fakten und Kontext verwenden, aber niemals Sätze aus dem Originalartikel wörtlich übernehmen. Kurze Zitate sind erlaubt, wenn sie als solche gekennzeichnet und mit Quellenlink versehen sind. Claude wird im Prompt explizit angewiesen, alles vollständig neu zu formulieren.
Bilder: Das größte Abmahnrisiko liegt bei Bildern. Das image_url-Feld aus dem RSS-Feed darf nicht einfach als Featured Image übernommen werden – das wäre die Neuveröffentlichung eines urheberrechtlich geschützten Bildes auf deiner Website. Stattdessen generieren wir mit Flux-2-Flex ein eigenes Bild, das zu 100 % uns gehört.
3.6.2 Den Workflow starten
- Gehe zur Workflow-Übersicht und klicke auf Create new workflow
- Nenne ihn:
A4 Agent: Artikel erstellen mit eigenem Bild - Füge einen Schedule Trigger hinzu:
- Trigger Interval: Hours
- Hours Between Triggers: 23
- Trigger at Minute: 0
Für den Aufbau nutzen wir zunächst den Manual Trigger, damit wir beim Testen direkt starten können.
3.6.3 Die beste Story aus der Datenbank holen
Agent 4 liest aus der ki_story-Tabelle – dort liegt der angereicherte Inhalt aus Agent 3. Das SQL-Query ist das komplexeste des gesamten Projekts: Es holt die beste Story und lädt direkt alle zugehörigen Tavily-URLs als Array mit, damit Claude sie im Quellenabschnitt verlinkt.
- Füge eine Postgres-Node hinzu:
- Node: Execute a SQL query
- Query:
SELECT
s.id AS story_id,
s.status,
s.score_gesamt_enriched,
s.content_enriched,
a.title AS original_title,
a.url AS original_url,
a.published_date AS original_published_at,
a.source AS original_source,
COALESCE((
SELECT ARRAY_AGG(x.url ORDER BY x.rank NULLS LAST, x.retrieved_at DESC, x.url)
FROM (
SELECT DISTINCT
a2.url,
e.rank,
e.retrieved_at
FROM ki_artikel_edges e
JOIN ki_artikel a2
ON a2.id = e.to_artikel_id
WHERE e.from_artikel_id = s.primary_artikel_id
AND e.relation_type = 'tavily_related'
AND a2.url_normalized IS DISTINCT FROM a.url_normalized
ORDER BY e.rank NULLS LAST, e.retrieved_at DESC, a2.url
LIMIT 10
) x
), ARRAY[]::text[]) AS tavily_urls
FROM ki_story s
JOIN ki_artikel a ON a.id = s.primary_artikel_id
WHERE s.status = 'ANGEREICHERT'
ORDER BY s.score_gesamt_enriched DESC
LIMIT 1;3.6.4 Artikel-Prompt für Claude aufbauen
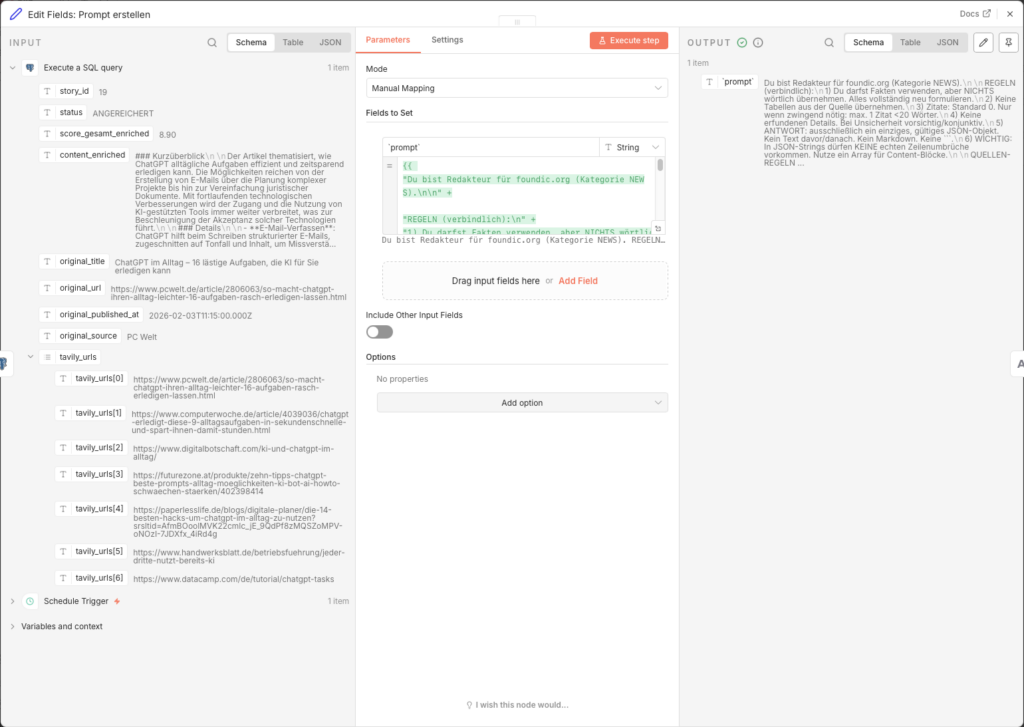
Ein Edit Fields-Node baut den vollständigen Prompt auf. Er ist bewusst restriktiv: sechs verbindliche Redaktionsregeln verhindern Urheberrechtsverletzungen.
- Node: Edit Fields (Name:
Edit Fields: Prompt erstellen) - Add Field → Name:
`prompt`→ Type: String → Value (Expression):
={{
"Du bist Redakteur für foundic.org (Kategorie NEWS).\n\n" +
"REGELN (verbindlich):\n" +
"1) Du darfst Fakten verwenden, aber NICHTS wörtlich übernehmen. Alles vollständig neu formulieren.\n" +
"2) Keine Tabellen aus der Quelle übernehmen.\n" +
"3) Zitate: Standard 0. Nur wenn zwingend nötig: max. 1 Zitat <20 Wörter.\n" +
"4) Keine erfundenen Details. Bei Unsicherheit vorsichtig/konjunktiv.\n" +
"5) ANTWORT: ausschließlich ein einziges, gültiges JSON-Objekt. Kein Text davor/danach. Kein Markdown. Keine ```.\n" +
"6) WICHTIG: In JSON-Strings dürfen KEINE echten Zeilenumbrüche vorkommen. Nutze ein Array für Content-Blöcke.\n\n" +
"ARTIKELDATEN:\n" +
"ORIGINAL_TITEL: " + ($json.title ?? "") + "\n" +
"BESCHREIBUNG: " + ($json.description ?? "") + "\n" +
"INHALT (nur Kontext, NICHT übernehmen): " + (($json.content ?? "").slice(0, 1500)) + "\n" +
"QUELLE: " + ($json.source ?? "") + "\n" +
"DATUM: " + ($json.published_date ?? "") + "\n" +
"URL: " + ($json.url ?? "") + "\n\n" +
"Pflichtregeln für wp_title:\n" +
"- wp_title ist eine kurze Umformulierung des ORIGINAL_TITEL (gleicher Sachverhalt).\n" +
"- wp_title enthält mindestens 2 Kernbegriffe aus ORIGINAL_TITEL (z.B. Siemens/CES/Industrie).\n" +
"- max. 12 Wörter.\n\n" +
"ERWARTETES JSON (Keys nie weglassen, fehlende Werte: \"\" oder []):\n" +
"{\n" +
" \"wp_title\": \"...\",\n" +
" \"wp_excerpt\": \"...\",\n" +
" \"wp_content_blocks\": [\n" +
" \"<h2>Worum geht’s?</h2>\",\n" +
" \"<p>...</p>\",\n" +
" \"<h2>Hintergrund & Einordnung</h2>\",\n" +
" \"<p>...</p>\",\n" +
" \"<p>...</p>\",\n" +
" \"<h2>Was bedeutet das?</h2>\",\n" +
" \"<ul><li>...</li><li>...</li><li>...</li></ul>\",\n" +
" \"<h2>Quelle</h2>\",\n" +
" \"<p><a href=\\\"" + ($json.url ?? "") + "\\\">" + (($json.title ?? "").replace(/"/g, '\\"')) + "</a> (" + ($json.source ?? "") + ", " + ($json.published_date ?? "") + ")</p>\"\n" +
" ],\n" +
" \"<p><i>Dieser Artikel wurde mit KI erstellt und basiert auf den angegebenen Quellen sowie den Trainingsdaten des Sprachmodells.</i></p>\"\n" +
" ],\n" +
" \"wp_tags\": [\"...\",\"...\",\"...\",\"...\",\"...\"]\n" +
"}\n"
}}Der Prompt ist bewusst restriktiv aufgebaut: sechs verbindliche Redaktionsregeln verhindern Urheberrechtsverletzungen, die Quellen-Regeln sorgen dafür, dass Claude nur hochwertige Medien verlinkt, und das JSON-Ausgabeformat ermöglicht die maschinelle Weiterverarbeitung ohne Nachbearbeitung.
3.6.5 Artikel mit Claude Sonnet schreiben
- Node: Message a model (Anthropic)
- Credential to connect with: Anthropic API Key (erstellen unter console.anthropic.com)
- Model: claude-sonnet-4-5-20250929
- Messages → Content:
={{ $json['prompt'] }} - Options → Maximum Number of Tokens: 4000
Das Token-Limit auf 4000 hochzusetzen ist wichtig – ohne diese Einstellung wird der Artikel mittendrin abgeschnitten.
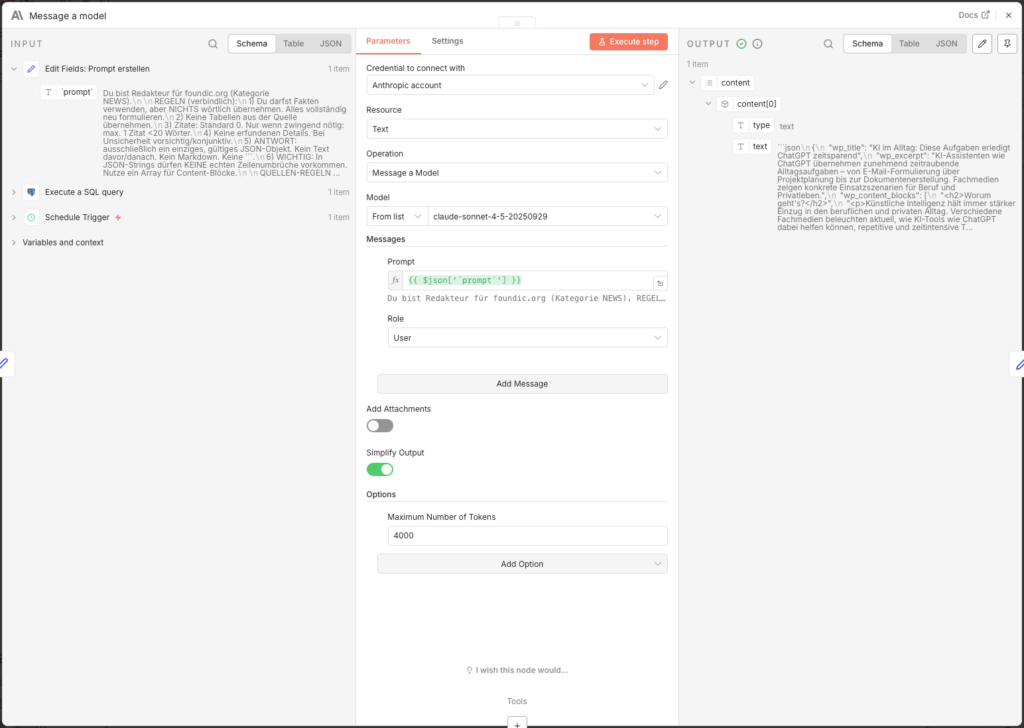
3.6.6 Claude-Output parsen
Claude liefert die Antwort als Rohtext zurück. Ein Edit Fields-Node extrahiert daraus das JSON-Objekt:
- Node: Edit Fields (Name:
Edit Fields1) - Add Field -> Name:
parsed-> Type: Object -> Value:
={{
(() => {
const raw =
$json?.content?.[0]?.text ??
$json?.content?.[0]?.content?.[0]?.text ??
$json?.text ??
"";
const cleaned = raw.replace(/```(?:json)?/gi, "").trim();
try {
return JSON.parse(cleaned);
} catch (e) {
return { error: "JSON konnte nicht gelesen werden", raw: cleaned };
}
})()
}}Der Code probiert mehrere mögliche Pfade im Claude-Response-Objekt durch. Falls das Parsing scheitert, gibt er ein Fehlerobjekt zurück – so bricht der Workflow nicht kommentarlos ab, sondern hinterlässt einen lesbaren Hinweis.
3.6.7 Felder für WordPress aufbereiten
Ein zweiter Edit Fields-Node „entpackt“ die geparsten Felder in eigenständige, benannte Variablen:
- Node: Edit Fields (Name:
Edit Fields2)
| Name | Type | Value |
|---|---|---|
| wp_title | String | ={{ $json.parsed.wp_title }} |
| wp_content | String | ={{ $json.parsed.wp_content_blocks.join('\n\n') }} |
| wp_excerpt | String | ={{ $json.parsed.wp_excerpt }} |
| wp_tags | String | ={{ $json.parsed.wp_tags }} |
Die wp_content_blocks werden durch join('\n\n') zu einem einzigen HTML-String zusammengefügt – genau das Format, das die WordPress REST API erwartet.
3.6.8 Bildprompt für Flux aufbauen
Jetzt startet der Bildgenerierungsprozess. Ein Edit Fields-Node baut den Flux-Prompt auf Basis des fertig geschriebenen Artikels:
- Node: Edit Fields (Name:
Edit Fields3) - Add Field → Name:
`prompt`→ Type: String → Value:
={{
"THEMA (kurz): " + ($json.wp_title ?? "") +
". KONTEXT (kurz): " + ($json.wp_excerpt ?? "") +
". " +
"Erstelle auf Basis des obigen Blogtextes eine moderne, vektorbasierte Editorial-Illustration im Flat-Design, geeignet als ruhiges Coverbild für einen professionellen Tech- oder Wissensblog. " +
"Stil und Gestaltung: Editorial-Flat-Illustration (Flat Design 2.0), vektorbasiert, sauber und minimalistisch. " +
"Klare Linien, einfache geometrische Formen, ruhige Flaechen und harmonische Proportionen. " +
"Reduzierte, professionelle Farbpalette mit warmen, gedämpften Toenen (Beige, Apricot, Orange) kombiniert mit zurueckhaltenden Blau- und Gruentoenen auf hellem Hintergrund. " +
"Weiches, flaechiges Licht mit sehr subtilen Schatten oder leichten Verlaeufen, keine realistische Lichtquelle. " +
"Abstrahierte, neutrale Figuren oder symbolische Objekte ohne individuelle Merkmale. " +
"Aufgeraeumte Komposition mit Fokus auf eine zentrale visuelle Metapher. " +
"Ruhige, sachliche Bildwirkung mit redaktionellem Charakter. " +
"Inhaltliche Vorgaben: Thema visuell abstrahieren, nicht woertlich oder erzählerisch. Keine konkrete Szene mit erkennbarem Ort oder realen Marken. " +
"Zwingende Verbote: Kein Text im Bild (keine Buchstaben, Woerter, Zahlen, Schriftzeichen). Keine Logos/Markenzeichen/firmenspezifischen Symbole. Keine Fotografie, kein Fotorealismus. Keine 3D-Darstellung. Keine Comic- oder Cartoon-Optik. " +
"Technische Vorgaben: Quadratisches Bildformat. Zeitgemaesser, konsistenter Stil fuer redaktionelle Online-Inhalte. "
}}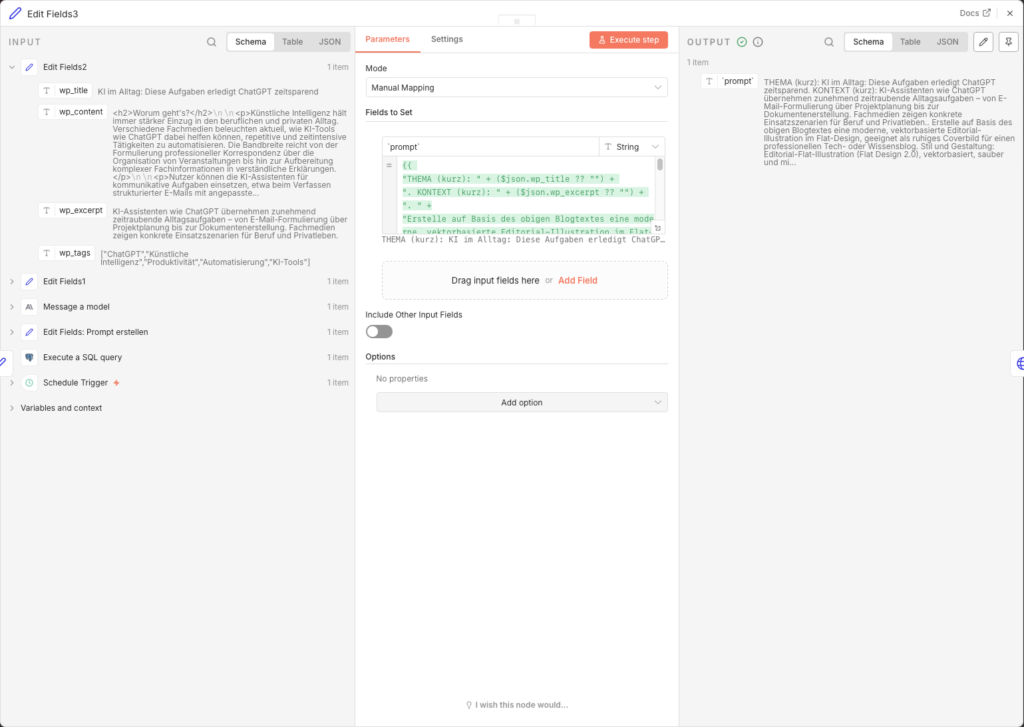
Der Prompt nutzt wp_title und wp_excerpt aus dem gerade erstellten Artikel als inhaltliche Basis. Die detaillierten Stil-Vorgaben (Flat Design 2.0, gedämpfte Farben, kein Text, kein Fotorealismus) sorgen für ein konsistentes, redaktionelles Bildlook über alle generierten Cover hinweg.
3.6.9 Bild bei Black Forest Labs anfordern
Die BFL-API arbeitet asynchron – du stellst einen Auftrag, bekommst eine Auftragsnummer zurück und fragst später nach, ob das Bild fertig ist. Wie eine Bäckerei: Bestellung aufgeben, Zettelchen nehmen, später abholen.
Schritt 1: API Key einrichten
Erstelle auf bfl.ai einen Account, lade Guthaben auf und kopiere deinen API Key. Speichere ihn in n8n als Custom Auth Credential:
- Gehe zu n8n Hauptmenü → Credentials → New
- Type: Custom Auth
- Name: z. B.
BFL API Key - JSON:
{
"headers": {
"x-key": "bfl_DEIN_API_KEY_HIER"
}
}Schritt 2: Bild-Job starten
- Node: HTTP Request (Name:
HTTP Request - URL Bild) - Method: POST
- URL:
https://api.bfl.ai/v1/flux-2-flex - Authentication: Generic Credential Type → Custom Auth → dein BFL-Credential
- Send Headers: ON
- Name:
Content-Type/ Value:application/json
- Name:
- Send Body: ON → Body Content Type: JSON → Specify Body: Using JSON
- JSON Body:
{
"prompt": "={{ $json['`prompt`'] }}",
"prompt_upsampling": true,
"width": 1024,
"height": 1024,
"steps": 35,
"guidance": 5,
"output_format": "jpeg",
"safety_tolerance": 2
}- Response Format: JSON
Die 35 Render-Steps liefern eine gute Balance zwischen Bildqualität und Generierungszeit (ca. 8–15 Sekunden).
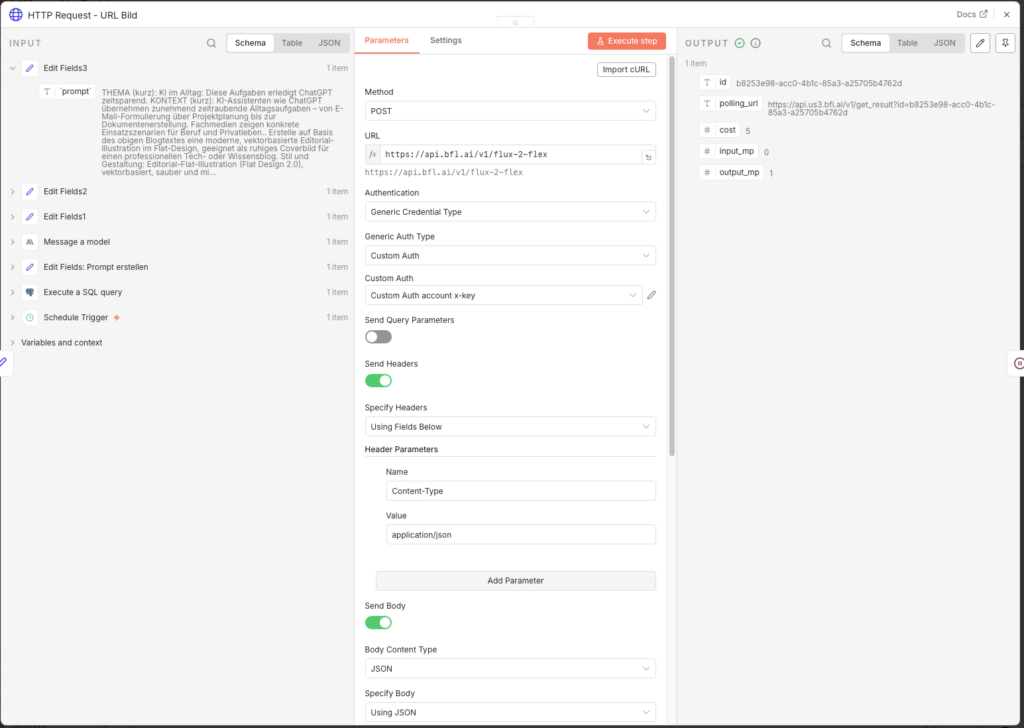
3.6.10 Warten und Bild abrufen
Da die API asynchron arbeitet, brauchen wir eine Poll-Schleife: warten -> nachfragen -> fertig oder nochmal warten.
Wait-Node:
- Node: Wait
- Resume: After Time Interval
- Wait Amount: 11 Sekunden
11 Sekunden ist in der Praxis eine gute Wartezeit für Flux-2-Flex. Zu kurz führt zu vielen unnötigen Check-Requests, zu lang verlängert die Workflow-Laufzeit unnötig.
Check-Node: - Node: HTTP Request (Name:
HTTP Request - Check URL Bild) - Method: GET
- URL:
={{ $('HTTP Request - URL Bild').item.json.polling_url }} - Response Format: JSON
IF-Node (fertig oder weiter warten): - Node: IF
- Condition:
{{ $json.status }}is equal toReady- TRUE → weiter zum Download
- FALSE → zurück zum Wait-Node (Verbindung vom FALSE-Ausgang zurück zu „Wait“)
Achtung: BFL gibtReadymit großem R zurück – nichtREADY. Tippfehler hier führen zu einer Endlosschleife.
Download-Node:
- Node: HTTP Request (Name:
HTTP Request - Download URL Bild) - Method: GET
- URL:
={{ $json.result.sample }} - Response Format: File
Das Bild landet jetzt als Binary-Daten im Felddataund ist bereit zum Speichern.
3.6.11 Dateinamen vergeben
Ein Edit Fields-Node erstellt einen systematischen Dateinamen im Format YYYY-MM-DD_quelle_artikel-slug_img-01.jpg:
- Node: Edit Fields (Name:
Edit Fields5) - Include Other Input Fields: ON
- Add Field → Name:
filename→ Type: String → Value:
={{
(String($('Execute a SQL query').item.json.original_published_at || '').substring(0,10) || '0000-00-00')
}}_{{
String($('Execute a SQL query').item.json.original_source || 'unknown').toLowerCase().replace(/\s+/g, '-').replace(/[^a-z0-9-]/g,'')
}}_{{
String($('Execute a SQL query').item.json.original_title || 'untitled')
.toLowerCase()
.normalize('NFD').replace(/[\u0300-\u036f]/g, '')
.replace(/[^a-z0-9]+/g, '-')
.replace(/^-+|-+$/g, '')
.substring(0, 80)
}}_img-01.jpgDas Ergebnis: 2026-01-20_heise-it_openai-stellt-neues-modell-vor_img-01.jpg. Jeder Dateiname ist eindeutig, lesbar und sortierbar nach Datum.
3.6.12 Bild auf der Synology NAS speichern
- Node: Read/Write Files from Disk
- Operation: Write File to Disk
- Binary Property:
data - File Path:
/data/wpmedia/raw/{{ $json.filename }}
Damit n8n auf dieses Verzeichnis schreiben darf, muss das Volume im Docker-YAML gemountet sein. Falls noch nicht geschehen, ergänze in deinerdocker-compose.ymluntervolumes:
volumes:
- /volume2/docker/n8n/app_data:/home/node/.n8n
- /volume1/WordPress/media:/data/wpmedia # ← diese Zeile hinzufügenDanach den Container neu starten. Außerdem müssen die Schreibrechte für den n8n-Prozess stimmen – falls der Node einen Fehler meldet, hilft dieser SSH-Befehl auf der DiskStation
sudo chown -R 1000:1000 /volume1/WordPress/media/
sudo chmod -R 775 /volume1/WordPress/media/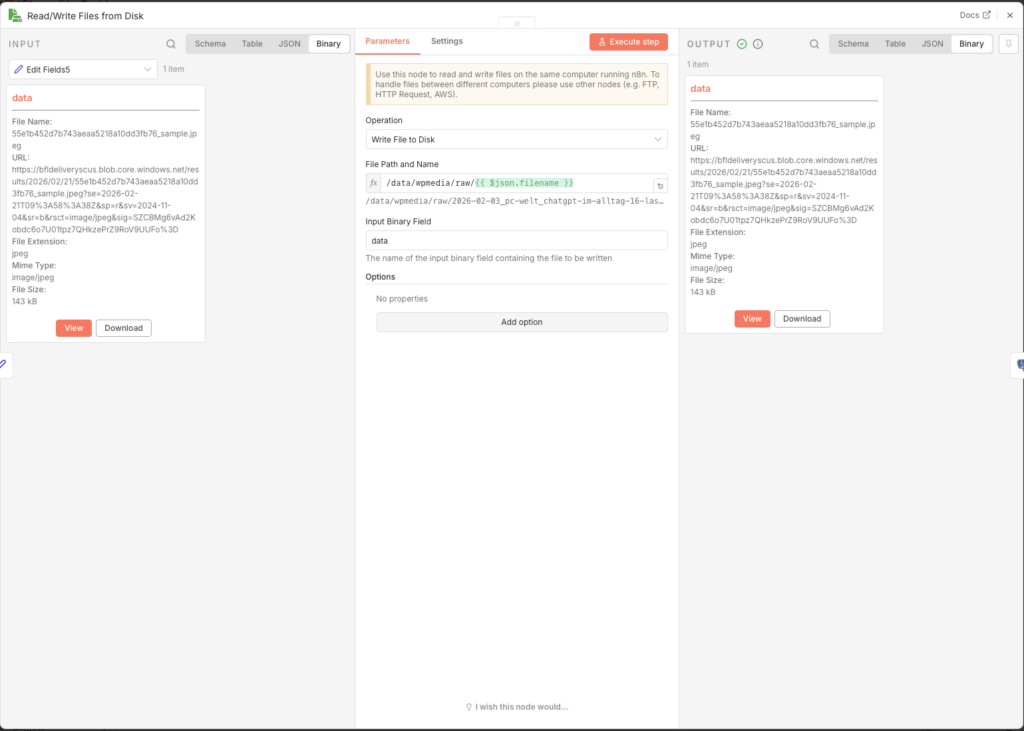
3.6.13 Story in Datenbank aktualisieren
Zum Abschluss schreibt ein Postgres-Node alle erzeugten Inhalte in die ki_story-Tabelle zurück und setzt den Status auf PUBLISH_READY. Das ist das Signal für Agent 5, dass dieser Artikel zur Veröffentlichung bereit steht.
- Node: Update rows in a table
- Credential to connect with:
n8n-postgres - Operation: Update
- Schema: public
- Table: ki_story (nicht ki_artikel!)
- Mapping Column Mode: Map Each Column Manually
- Columns to match on: id
| Feld | Value |
|---|---|
| id (using to match) | ={{ $('Execute a SQL query').item.json.story_id }} |
| status | PUBLISH_READY |
| wp_title | ={{ $('Edit Fields2').item.json.wp_title }} |
| wp_content | ={{ $('Edit Fields2').item.json.wp_content }} |
| wp_excerpt | ={{ $('Edit Fields2').item.json.wp_excerpt }} |
| wp_tags | ={{ $('Edit Fields2').item.json.wp_tags }} |
| image_file_path | ={{ $json.fileName }} |
$json.fileName (mit großem N) ist der automatisch von n8n vergebene Name der gespeicherten Datei – er entspricht dem Wert aus Edit Fields5, wird aber direkt aus dem Read/Write-Node übernommen.
3.6.14 Workflow veröffentlichen
Stelle den Schedule Trigger auf 23 Stunden und aktiviere den Workflow über Publish. Agent 4 läuft täglich einmal, nimmt die beste angereicherte Story, produziert daraus einen fertigen Artikel mit eigenem Coverbild und legt beides in der Datenbank ab.
3.7 Agent 5: Veröffentlichen auf WordPress
Tanja: „Das ist der letzte Schritt, Agent 5 übergibt alles an WordPress.“
Ulf: „Und dann ist der Artikel live?“
Tanja: „Nein. Er landet als Entwurf. Du schaust drüber, gibst grünes Licht, und erst dann geht er online.“
Bernd: „Warum nicht direkt veröffentlichen?“ Dann spart man sich den Schritt.“
Tanja: „Weil, KI-Artikel manchmal Fehler enthalten. Halluzinationen. Falsche Namen. Veraltete Zahlen. Ein kurzer menschlicher Blick verhindert, dass dein Blog Unsinn veröffentlicht, während du schläfst.“
Bernd überlegt. „Ich hätte das direkt veröffentlicht.“
Tanja: „Das weiß ich.“
3.7.1 Vorbereitung in WordPress
Damit n8n Artikel und Bilder hochladen darf, braucht es ein Anwendungspasswort. Das ist sicherer als dein normales Login – es kann jederzeit widerrufen werden, ohne dass sich dein Hauptpasswort ändert.
- Logge dich in dein WordPress-Admin ein
- Lege unter Benutzer → Neu hinzufügen einen neuen Benutzer an, z. B.
n8n-publisher - Weise ihm die Rolle Autor oder Redakteur zu – er braucht keine Admin-Rechte
- Öffne das Profil des neuen Benutzers und scrolle ganz nach unten zu Anwendungspasswörter
- Gib einen Namen ein (z. B.
n8n-Diskstation) und klicke auf Neues Anwendungspasswort hinzufügen - Wichtig: Kopiere das angezeigte Passwort sofort (z. B.
abcd efgh ijkl ...), es wird nur dieses eine Mal angezeigt - Notiere außerdem die Kategorie-ID deiner Ziel-Kategorie. Diese findest du in WordPress unter Beiträge -> Kategorien: Klicke die gewünschte Kategorie an und lies die ID aus der URL ab (z. B.
...tag_ID=8)
3.7.2 Den Workflow starten
- Gehe zurück zur Workflow-Übersicht und klicke auf Create new workflow
- Nenne ihn oben links:
A5 Agent: Veröffentlichen auf WordPress - Klicke auf Add First Step und wähle Schedule Trigger
- Trigger Interval: Hours
- Hours Between Triggers: 23
- Trigger at Minute: 0
Für den Aufbau nutzen wir zunächst den Manual Trigger, damit wir direkt testen können.
3.7.3 Fertigen Artikel aus der Datenbank holen
- Node: Postgres – Execute a SQL query
- Credential to connect with:
n8n-postgres - Query:
SELECT
id,
wp_title,
wp_content,
wp_excerpt,
wp_tags,
image_file_path
FROM ki_story
WHERE status = 'PUBLISH_READY'
ORDER BY created_at DESC
LIMIT 1;Der Status PUBLISH_READY wird von Agent 4 automatisch gesetzt. Du kannst ihn in Metabase auch manuell vergeben oder entfernen – das gibt dir volle Kontrolle darüber, welche Artikel in die Veröffentlichungswarteschlange kommen.
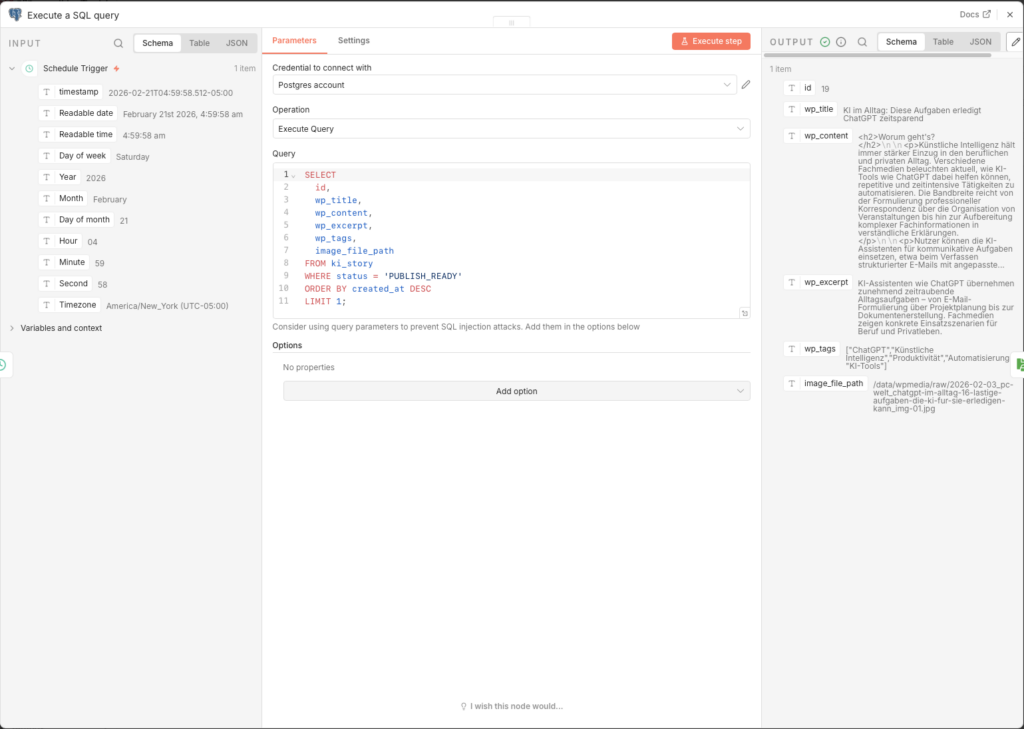
3.7.4 Bild von der NAS laden
Das Bild muss als Binary-Datei in den n8n-Arbeitsspeicher geladen werden, bevor es an WordPress übertragen werden kann.
- Node: Read/Write Files from Disk
- Operation: Read File(s) From Disk
- File(s) Selector:
={{ $json.image_file_path }}
Derimage_file_pathaus der Datenbank enthält den vollständigen Pfad innerhalb des Docker-Containers, z. B./data/wpmedia/raw/2026-01-20_heise-it_openai-stellt-neues-modell-vor_img-01.jpg. Dieser Pfad muss mit dem in Agent 4 gemounteten Volume übereinstimmen.
3.7.5 Bild in die WordPress-Mediathek hochladen
WordPress braucht das Bild zuerst in der Mediathek, um ihm eine interne ID zuzuweisen – diese ID wird dann beim Erstellen des Beitrags als featured_media referenziert.
- Node: HTTP Request (Name:
HTTP Request) - Method: POST
- URL:
https://foundic.org/wp-json/wp/v2/media - Authentication: Generic Credential Type → Basic Auth
- Basic Auth Credential → New Credential:
- Username: dein n8n-Publisher-Benutzername
- Password: das Anwendungspasswort (nicht das normale Login-Passwort!)
- Send Headers: ON
| Header Name | Value |
|---|---|
| Content-Disposition | =attachment; filename="{{ $binary.data.fileName }}" |
| Content-Type | image/jpeg |
- Send Body: ON
- Body Content Type: n8n Binary File
- Input Data Field Name:
data
Wenn der Request erfolgreich ist, gibt WordPress ein JSON-Objekt zurück, das u. a. das Feldidenthält – die Medien-ID des hochgeladenen Bildes. Diese ID brauchen wir im nächsten Schritt.
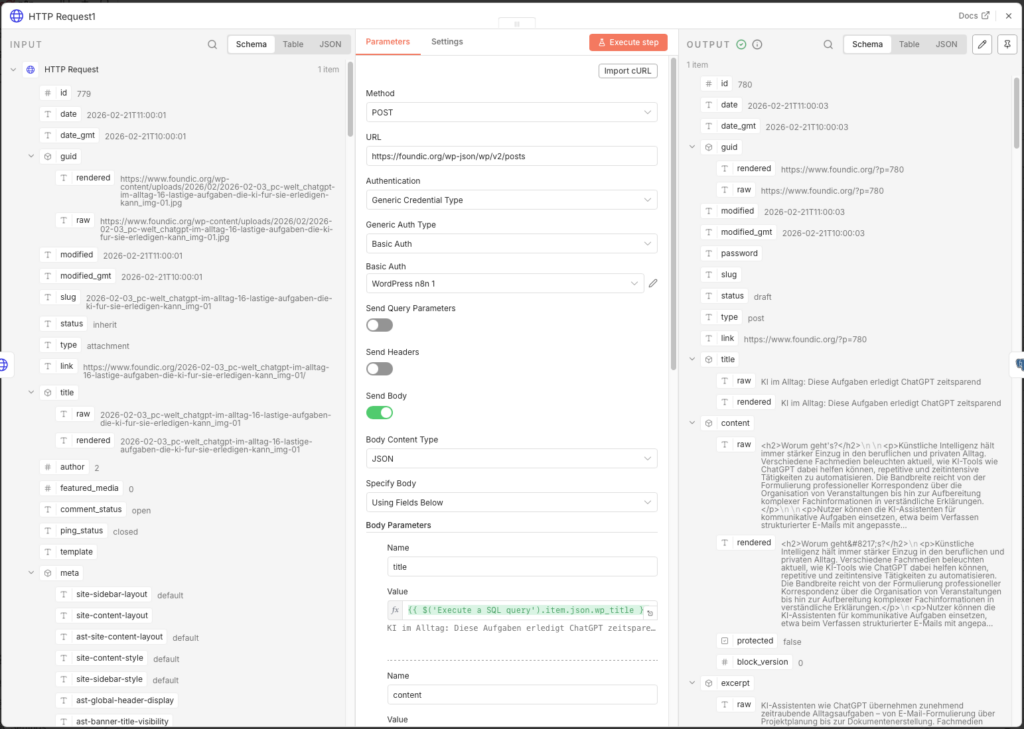
3.7.6 WordPress-Beitrag erstellen
Jetzt wird der eigentliche Beitrag angelegt. Wichtig: Der Status ist bewusst auf draft gesetzt – der Artikel erscheint nicht sofort öffentlich, sondern landet zunächst als Entwurf in WordPress, wo er prüft und freigeben werden kann.
- Node: HTTP Request (Name:
HTTP Request1) - Method: POST
- URL:
https://foundic.org/wp-json/wp/v2/posts - Authentication: Generic Credential Type → Basic Auth → dasselbe Credential wie oben
- Send Body: ON
- Body Content Type: JSON
- Specify Body: Using Fields Below
Füge folgende Body-Felder hinzu (über Add Parameter):
| Name | Value |
|---|---|
| title | ={{ $('Execute a SQL query').item.json.wp_title }} |
| content | ={{ $('Execute a SQL query').item.json.wp_content }} |
| excerpt | ={{ $('Execute a SQL query').item.json.wp_excerpt }} |
| featured_media | ={{ $json.id }} ← Medien-ID aus dem vorherigen HTTP Request |
| status | draft |
| categories | 8 ← deine Kategorie-ID aus Schritt 3.7.1 |
Das Feld featured_media mit {{ $json.id }} referenziert die Bild-ID, die WordPress im vorherigen Schritt zurückgegeben hat – das verknüpft das hochgeladene Bild automatisch als Coverbild des Beitrags.
3.7.7 Status in der Datenbank aktualisieren
Nach erfolgreicher Übergabe an WordPress wird der Status in ki_story auf PUBLISHED gesetzt, damit der Artikel beim nächsten Durchlauf nicht erneut verarbeitet wird.
- Node: Update rows in a table
- Credential to connect with:
n8n-postgres - Operation: Update
- Schema: public
- Table: ki_story
- Mapping Column Mode: Map Each Column Manually
- Columns to match on: id
| Feld | Value |
|---|---|
| id (using to match) | ={{ $('Execute a SQL query').item.json.id }} |
| status | PUBLISHED |
3.7.8 Der Human-in-the-Loop: Freigabe in WordPress
Nachdem Agent 5 gelaufen ist, liegt der Artikel als Entwurf in WordPress. Jetzt bist du dran – und das ist gut so:
- Logge dich in dein WordPress-Admin ein
- Gehe zu Beiträge → Entwürfe
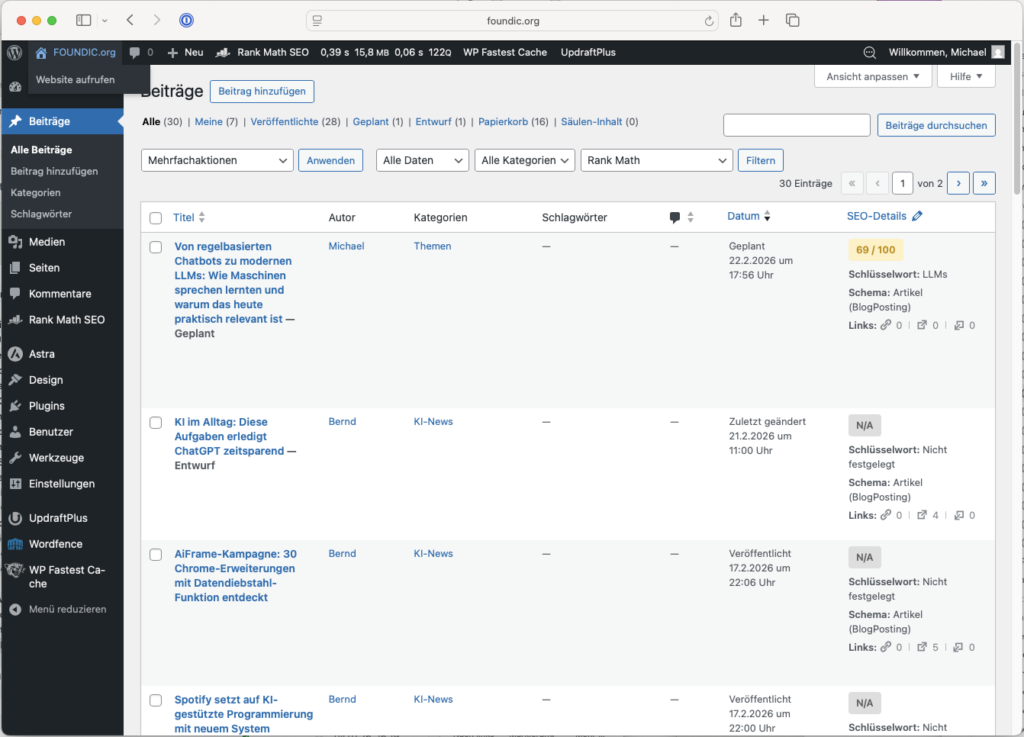
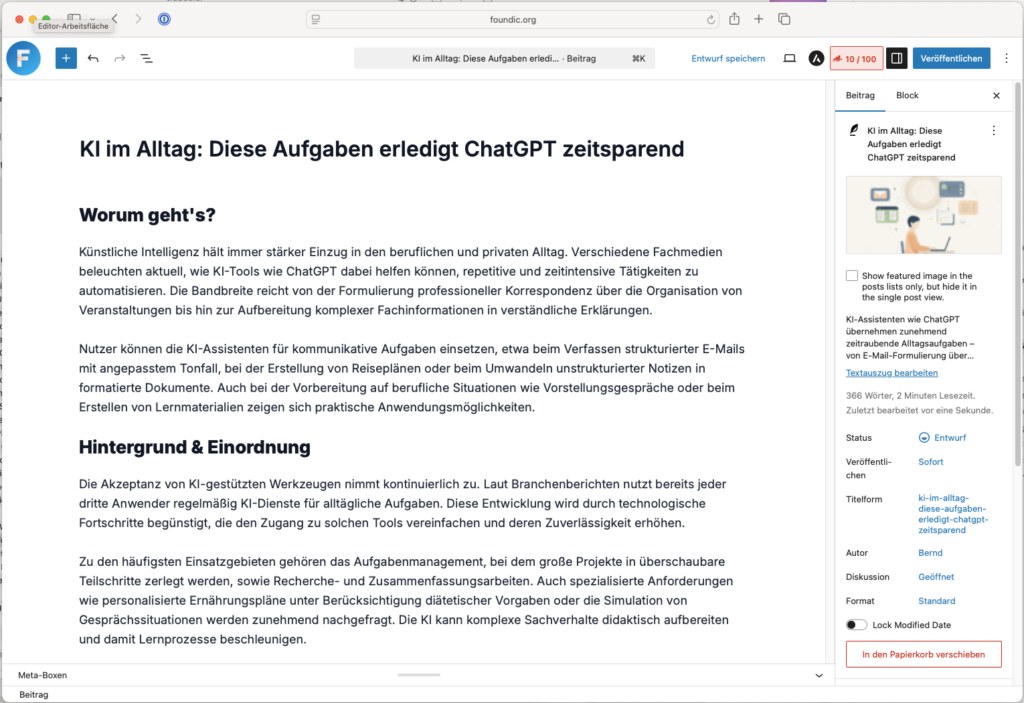
- Öffne den neu erstellten Beitrag und prüfe Titel, Text, Bild und Tags
- Falls alles passt: Klicke auf Veröffentlichen
- Falls du Anpassungen möchtest: Bearbeite den Beitrag direkt in WordPress
Du kannst in Metabase jederzeit den aktuellen Status aller Artikel einsehen und den status-Wert manuell anpassen – z. B. um einen Artikel zurück auf ANGEREICHERT zu setzen, wenn Agent 4 ihn neu bearbeiten soll.
3.7.9 Workflow veröffentlichen
Stelle den Schedule Trigger auf 23 Stunden und aktiviere über Publish. Die gesamte Pipeline läuft jetzt automatisch:
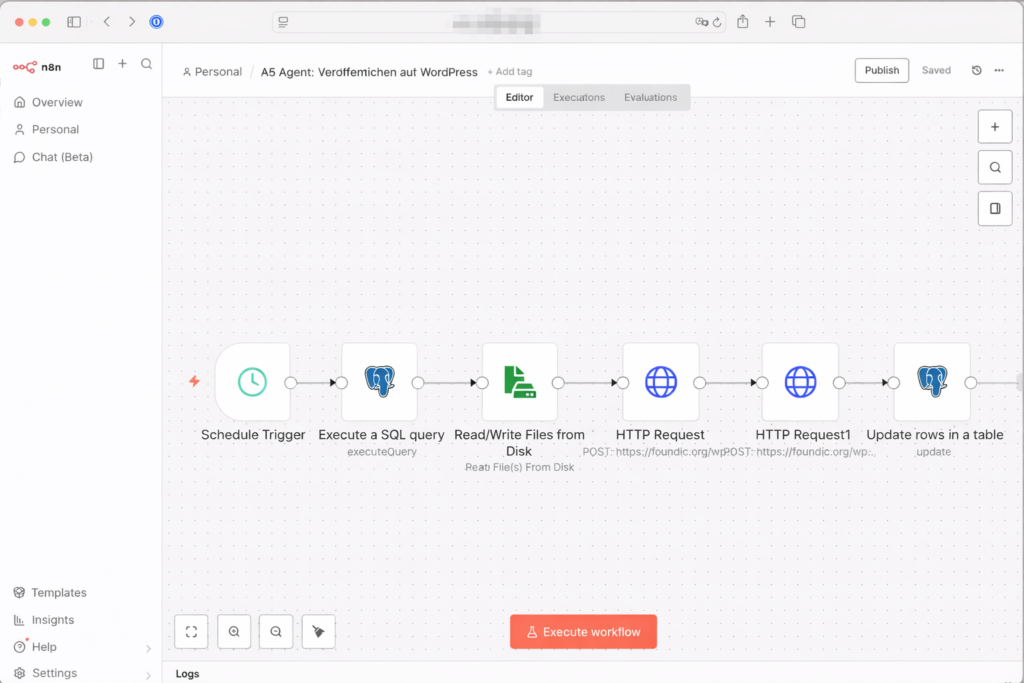
- Alle 2 Stunden liest Agent 1 neue Artikel aus 22 RSS-Feeds ein
- Alle 4 Stunden bewertet Agent 2 die neuen Einträge
- Alle 23 Stunden reichert Agent 3 die besten Artikel mit Web-Kontext an
- Alle 23 Stunden schreibt Agent 4 den fertigen Artikel und generiert das Coverbild
- Alle 23 Stunden lädt Agent 5 den Artikel als Entwurf in WordPress hoch – und wartet auf deine Freigabe bzw. Veröffentlichung in WordPress.
4 Fazit
Einige Wochen später. Gleiches Büro. Gleicher Montag.
Ulf öffnet seinen Laptop, nicht um Feeds zu durchklicken, sondern um einen einzigen Entwurf in WordPress zu prüfen. Der Artikel ist fertig geschrieben, hat ein Coverbild, Quellen und Tags. Er liest ihn durch, nickt, klickt auf „Veröffentlichen“.
Drei Minuten. Statt einer Stunde.
Bernd schaut herüber: „Hast du das alles selbst geschrieben?“
Ulf: „Eine KI hat es geschrieben, ich hab es nur freigegeben.“
Bernd: „Und das ist… okay so?“
Tanja lehnt sich zurück: „Das ist genau der Punkt.“
Was du gebaut hast
Wenn du alle fünf Agenten eingerichtet und aktiviert hast, läuft auf deiner Synology NAS ein vollautomatischer digitaler Newsroom – rund um die Uhr, ohne dass du jeden Morgen Feeds durchklicken oder manuell recherchieren musst. MEehrere Nachrichtenquellen (RSS-Feeds) werden kontinuierlich beobachtet, jede Meldung bewertet, die relevantesten Treffer tiefenrecherchiert, ein kompletter WordPress-Artikel geschrieben und ein eigenes Coverbild generiert. Was früher Stunden an redaktioneller Routinearbeit gekostet hätte, läuft heute im Hintergrund – und landet als Entwurf in deinem WordPress, wartet auf deinen letzten Blick und einen Klick.
Das ist kein Spielzeugprojekt. Du hast dabei ein ernsthaftes Stück Software-Architektur gebaut: eine relationale Datenbank mit Statusmaschine, ein Pipeline-System mit fünf unabhängig laufenden Agenten, Qualitätsprüfungen auf mehreren Ebenen, URL-Normalisierung zur Duplikatsvermeidung und einen Wissensgraphen aus verlinkten Artikeln. Und das alles ohne eine einzige Zeile Server-Code schreiben zu müssen.
Was das System wirklich leistet – und was nicht
Es lohnt sich, ehrlich zu sein: Das System schreibt gute, strukturierte, rechtskonforme Artikel. Aber es schreibt keine großartigen Artikel. Claude produziert soliden Redaktionsjournalismus – korrekt, gut aufgebaut, mit Quellen. Was fehlt, ist die menschliche Perspektive: die unerwartete Analogie, die pointierte Meinung, der Erfahrungswert aus zehn Jahren im Thema. Das System ist ein sehr guter erster Entwurf – aber ein Entwurf.
Genau deshalb ist der Human-in-the-Loop-Schritt kein lästiges Hindernis, sondern das Herzstück des Konzepts. Der Newsroom übernimmt die Fleißarbeit. Du übernimmst das Urteilsvermögen.
Was du jetzt tun kannst
Das System ist so gebaut, dass es wächst. Ein paar naheliegende nächste Schritte:
- Mehr Quellen – du kannst beliebig viele weitere RSS-Feeds in Agent 1 einbinden, ohne den Rest des Systems anzufassen. Englischsprachige Quellen wie TechCrunch, The Verge oder MIT Technology Review würden die internationale Perspektive deutlich verbessern.
- Feinere Bewertung – der Scoring-Prompt in Agent 2 lässt sich jederzeit anpassen. Wenn du merkst, dass bestimmte Subkategorien zu oft oder zu selten auftauchen, justiere einfach die Beschreibungen oder die Schwellenwerte.
- Mehrsprachigkeit – Claude schreibt problemlos auf Englisch, wenn du den Prompt in Agent 4 entsprechend anpasst. Damit ließe sich derselbe Workflow für einen zweiten Blog in einer anderen Sprache nutzen.
- Tags automatisch anreichern – die von Claude generierten
wp_tagskönnten zusätzlich gegen eine feste Tag-Taxonomie in WordPress abgeglichen werden, damit keine Tippvarianten entstehen. - Benachrichtigungen – ein zusätzlicher n8n-Workflow könnte dich per E-Mail oder Telegram benachrichtigen, sobald ein neuer Artikel als Entwurf in WordPress bereitliegt.
Das größere Bild
Dieses Projekt zeigt exemplarisch, wohin die Reise mit KI-Automatisierung geht: nicht darum, Menschen zu ersetzen, sondern darum, den eigenen Hebel zu verlängern. Eine einzelne Person kann mit diesem Setup eine Publikationsfrequenz aufrechterhalten, die früher ein kleines Redaktionsteam erfordert hätte – und das zu Betriebskosten von unter 5 Euro im Monat.
n8n ist dabei das eigentliche Geheimnis. Nicht weil es besser wäre als Zapier oder Make in jeder einzelnen Funktion, sondern weil es self-hosted läuft. Deine Workflows, deine Daten, deine Infrastruktur – auf deiner eigenen Hardware, ohne monatliche Plattformgebühren, ohne Vendor-Lock-in, ohne Datenschutzbedenken beim Verarbeiten von Artikelinhalten.
Wenn du dieses System aufgebaut hast, hast du nicht nur einen Newsroom gebaut. Du hast verstanden, wie Multi-Agenten-Systeme funktionieren, wie man KI-Outputs in echte Workflows einbettet und wie man Automatisierung so gestaltet, dass sie skalierbar, wartbar und kontrollierbar bleibt. Das sind Fähigkeiten, die weit über dieses eine Projekt hinaus nützlich sein werden.