Imagine sitting in the 1960s in front of a bulky teletype machine. You type: “I am sad.” The machine rattles and responds: “Why do you say that you are sad?” Magic? No — just text fragments following a fixed recipe. Today we hold philosophical debates with AI systems that write code, compose poems, and analyze business data. Anyone working with ChatGPT, Claude, or local models in automation workflows often experiences something almost magical: you write a sentence — and get useful answers, summaries, or even working code back. But this magic is the result of a long, surprisingly coherent line of development. Those who understand it make better technical decisions: Which models? Which architecture? When is a prompt enough — and when do you need more? This article traces that line — not as an academic history, but as a practical derivation of why modern Large Language Models (LLMs) work exactly the way they do — and what that means for building a future-proof, AI-capable automation environment.
Why You Should Know This
Whether you’re setting up a RAG system for your company, choosing between GPT-4 and a local Llama, or trying to understand why your chatbot sometimes hallucinates: the answers lie in this line of technical development. Those who know that an LLM “only” calculates probabilities ask different (better) questions. Those who understand why RAG works can use it deliberately. Those who grasp decoding can control outputs. The following 60 years of development history are not an academic finger exercise — they are the key to practical decisions you need to make today.
What an LLM Really Is Technically
Large language models can be soberly described as probabilistic text generators. They calculate — step by step — the probability of the next token (smallest text units, often word fragments) and build an output from that. The dominant architecture today is based on Transformer models. The path from input to answer can be told as a story in four acts — from raw text to seemingly intelligent output. Each of these steps carries the legacy of decades of research. Let’s look at how we got here.
The Stone Age: When Chatbots Still Worked by Recipe
1966: ELIZA – The Parrot Without Memory
In the early days, AI was pure rule-following. The most prominent example is ELIZA, developed at MIT. It worked like a mirror: it searched for keywords and bent sentences according to fixed patterns. The principle: if “mother” appears, respond: “Tell me more about your family.” The problem: there was no real language understanding. ELIZA didn’t know what a “mother” was; it only saw a character string. No statistics, no semantics, no world model.

Why this still mattered: text already had to be segmented — a primitive form of what we call tokenization today. And there was already a form of “answer generation,” however extremely fragile. ELIZA showed: language interaction was possible, but with the depth of a magic trick.
The Era of Probability: Rolling Dice Systematically
Late 1960s to 1990s: Hidden Markov Models – The Foundation Is Laid
From the 1970s through the 90s, things became more mathematical. Researchers understood that language is a process where one thing follows another. This is where Hidden Markov Models (HMMs) enter the scene. HMMs assume that behind what we see (words) lies a hidden state (grammar or intent). An HMM tries to do three things:
- Evaluation: How likely is this word sequence?
- Decoding: What is the most likely path through the sentence?
- Training: How do I adjust my internal rules to match the data?
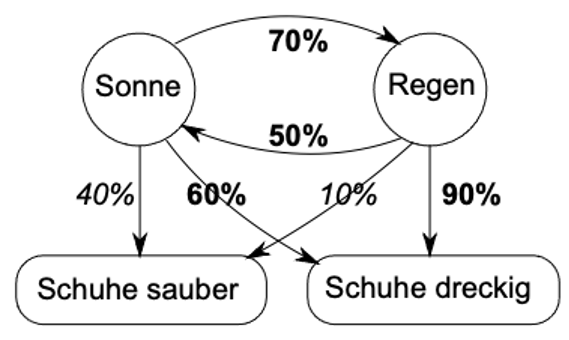
Why this is the direct predecessor of modern LLMs: here the foundation was laid — we no longer view language as a rigid rule, but as a chain of probabilities. Sequences are explained probabilistically. There is a clear separation between “calculating distributions” and “choosing a concrete output.” The idea of decoding (e.g. through the Viterbi algorithm) — the question of how to find the best concrete answer from probabilities — lives on to this day. Anyone who wants to predict the “next word” must be able to calculate.
The Breakthrough: When Words Become Maps
2013: Word2Vec – The Vector Revolution
For a long time, computers understood words as isolated symbols. “Dog” and “puppy” were as different to it as “dog” and “refrigerator.” That changed in 2013 with Word2Vec and the concept of embeddings. Words were translated into huge, multi-dimensional coordinate systems (vectors). Suddenly concepts had a position in space — and thus a computable meaning.
The famous formula: “King – Man + Woman ≈ Queen” actually worked in vector space.
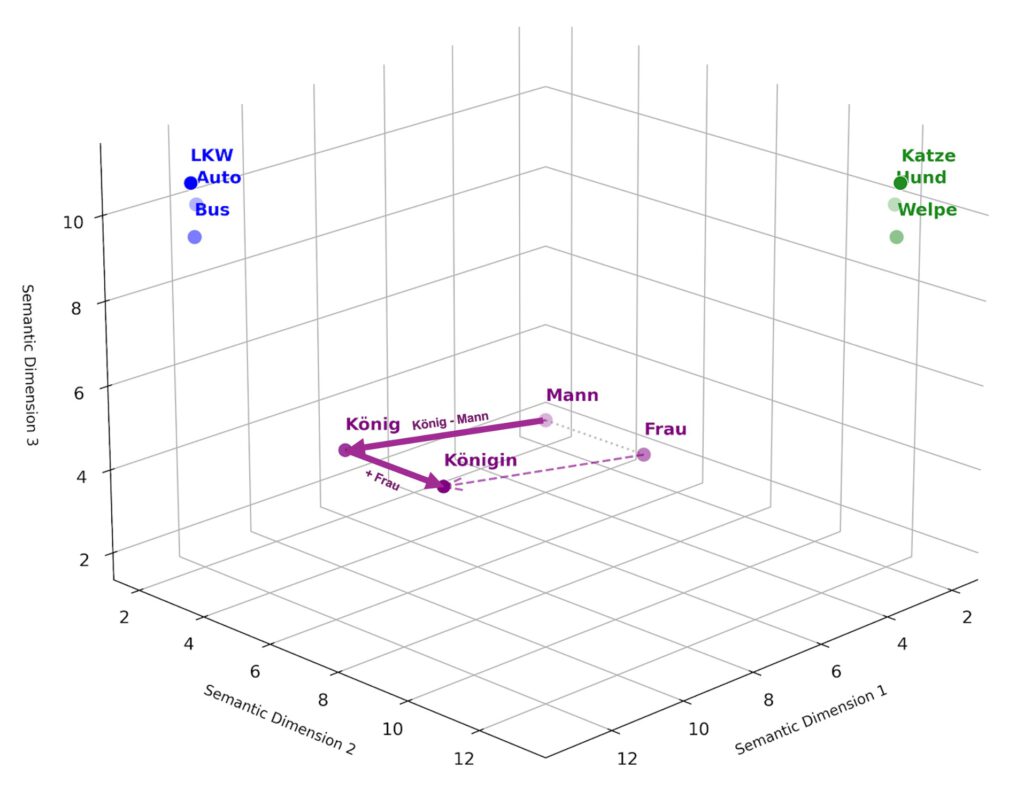
Why this was a milestone:
- Discrete symbols became continuous
- Semantic proximity became measurable
- Neural networks could process language robustly for the first time
- Only through this mathematical “neighborhood” could AI models understand semantic similarities, without a human having to explicitly program them
This was the birth of the first act of modern LLMs: Text is no longer treated as a sequence of characters, but as a position in a space of meaning.
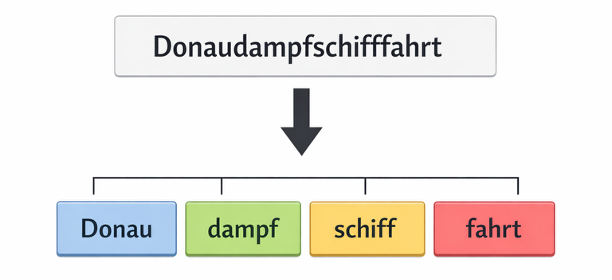
2015/2016: Subword Tokenization – The Lego Principle for Language
In parallel, subword tokenization (via techniques like Byte-Pair Encoding) solved an old problem: instead of learning every word individually, words are broken into pieces. This allows AI to understand even new coinages like “supercalifragilisticexpialidocious” by recognizing its components. It solved practical problems: open vocabularies, compound words, numbers, technical terms.
The Transformer Revolution: Attention Is Everything
2017: “Attention Is All You Need” – The Real Turning Point
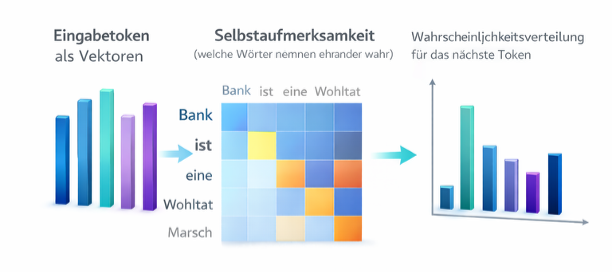
In 2017, a paper appeared with the bold title “Attention Is All You Need.” It introduced the Transformer (the “T” in GPT). The innovation? Self-attention. Earlier models laboriously read sentences from left to right and often “forgot” the beginning when it was too long. The Transformer, on the other hand, looks at the entire text simultaneously and weights which words are important for each other. Example: In the sentence “The bank was a relief after the long march,” the AI recognizes through attention that “bank” refers to a bench (because of “march” and “relief”) and not a financial institution.
The consequences:
- Massive parallelization becomes possible
- Long contexts become manageable
- Scaling becomes practical
- Everything can be considered simultaneously – no more laborious step-by-step processing
This is the second act: The model processes meanings and calculates relationships. It generates a probability distribution across tens of thousands of possible next tokens.
Three Common Misconceptions – Clarified
Before we continue, it’s worth correcting three persistent misconceptions about LLMs: ❌ “The model really understands me” ✅ It calculates probabilities based on patterns. Very good patterns — but no consciousness. The “map” from vectors is not semantic understanding in the human sense, but statistical proximity. ❌ “Bigger is always better” ✅ A small model + RAG + good prompts often beats a large model without context. GPT-4 without access to your data is less useful than Llama-2 with perfectly prepared company documents. ❌ “Hallucinations are a bug” ✅ They are a feature: the model fills probability gaps. It was trained to always generate something. RAG turns this into a controllable process by providing real facts as anchors.
2020: GPT-3 and In-Context Learning – The Aha Moment
Large models suddenly showed: you can explain tasks in the prompt without retraining the model. Give a few examples — and the model learns “on the fly.” This is not consciousness. It’s statistics at large scale. But it feels magical.
From Chatterbox to Assistant: The Psychological Fine-Tuning
Instruction Tuning – When AI Learns What You Really Want
A pure language model like GPT-3 was initially just an extremely good text completer. If you asked: “How do I bake a cake?”, it might respond: “How do I bake a loaf? How do I bake cookies?” — because it thought you wanted to complete a list of book titles. A base model implicitly answers: “What comes next?” Users ask: “Please do X — under my conditions.” Instruction tuning closes this gap. Through Supervised Fine-Tuning and Reinforcement Learning from Human Feedback (RLHF), responses that seem helpful, correct, and cooperative become more probable. Humans rated the AI’s answers, and a reward model taught it to be more helpful, more polite, and less “hallucinatory.” ChatGPT was born.
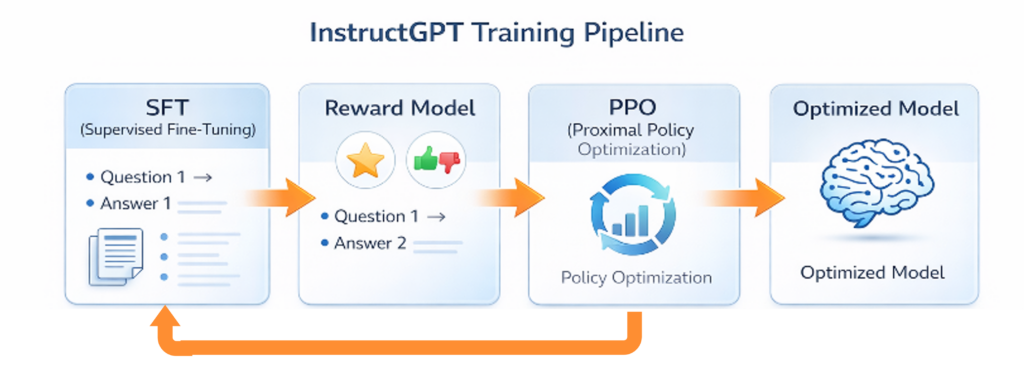
This is the third act: the model learns not just “what is statistically probable,” but “what does the human really want to hear.” The architecture remains the same — but the probabilities shift toward usefulness.
The Present: RAG – Knowledge Without Guessing
When the Model Looks Up Instead of Hallucinating
Despite all their intelligence, LLMs have a problem: their knowledge is “frozen” (at the training cutoff) and they tend to make things up when they don’t know the answer precisely. This is where RAG (Retrieval-Augmented Generation) comes in — the current gold-standard pattern for enterprises. Think of RAG like an “open-book exam”:
- The AI receives a question
- It searches your own data (PDFs, databases, wikis) for relevant passages – via embeddings, i.e., vector search
- It receives these text passages as context
- It formulates the answer based solely on these facts
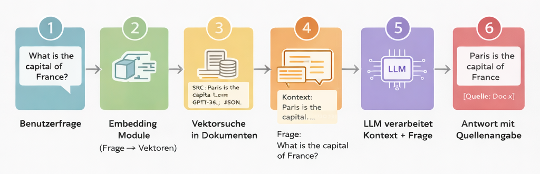
In practice this means:
- Documents are segmented
- Embeddings are computed
- Stored in a vector index (e.g., ChromaDB, Weaviate)
- At runtime, relevant context is retrieved
- Added to the prompt
The LLM then processes concrete sources instead of hallucinating. This makes the AI reliable, up-to-date, and above all: it “invents” facts far less often, since it has a source to refer to.
How an LLM Works: Four Steps from Text to Intelligence
Everything we admire in AI today can be reduced to four functional steps that carry the legacy of the last 60 years. Each step answers a fundamental question on the path from raw text to a useful answer.
1. Understanding: Text Becomes Meaning
The question: How does the model turn letters into something it can calculate with? The solution: Tokenization + Embeddings Text is broken down (from ELIZA’s keyword tricks to modern subword logic) and translated into a multi-dimensional space of meaning. “King” and “Queen” are closer together than “King” and “Bread” — the model “understands” semantic proximity. Historical roots:
- ELIZA (1966): Primitive Textsegmentierung
- Word2Vec (2013): Vektoren statt Symbole
- Subword Tokenization (2015): The Lego principle for open vocabularies
Result: Every token is now a vector – a position in the semantic space. The model can reason with concepts.
2. Thinking: The Transformer Calculates Relationships
The question: How does the model recognize which words are important for each other? The solution: Self-Attention in the Transformer The model looks at all words simultaneously and weights: what is relevant to what? In “The bank was a relief after the march,” it recognizes: bank = seating, not financial institution. Historical roots:
- Hidden Markov Models (1970s–90s): Sequences as probability chains
- Transformer (2017): Self-attention replaces sequential processing
- Scaling (2020+): GPT-3 shows what large models can do
Result: A probability distribution across 50,000+ possible next tokens. For each token: “How likely does it fit here?”
3. Choosing: From Probability to Text
The question: How does “Token A: 23%, Token B: 19%, Token C: 15%” become a concrete word? The solution: Decoding strategies The model has calculated probabilities — but which token do we actually choose?
- Greedy: Always pick the most likely token (boring, but safe)
- Beam Search: Keep multiple paths in parallel and choose the best overall path
- Top-k Sampling: Randomly pick from the k most likely tokens
- Top-p (Nucleus): Randomly sample from the most likely tokens until their cumulative probability reaches p% (more creative, but riskier)
Historical roots: - Viterbi algorithm (1980s): Best paths through probability spaces
- Beam search: From machine translation
- Sampling strategies: Balancing creativity and coherence
Result: A concrete token. Repeat the process until a sentence emerges.
Same weights, different strategy – completely different quality. Decoding determines whether your answer is creative or conservative, fluent or repetitive.
4. Optimizing: From Parrot to Assistant
The question: How does the model learn to give helpful rather than just probable answers? The solution: Instruction Tuning & RLHF The model learns not just “what comes statistically next,” but “what does the human actually want to hear.” Humans rate answers → a reward model shifts probabilities toward “helpful, correct, cooperative.” Historical roots:
- Supervised fine-tuning: Training on question-answer pairs
- RLHF (2022): InstructGPT/ChatGPT learn from human feedback
- Constitutional AI: Models learn principles instead of just examples
Result: A system that does what you want – not just what would statistically follow from your input. The architecture stays identical, but the probability space is calibrated differently.
What This Concretely Means for Your Architecture Decisions
The theory is one thing — but what practical decisions follow? Here are three typical scenarios:
Example 1: Model Selection – GPT-4 or Local Llama?
You’re considering whether to use cloud models or local open-source solutions? What you now understand:
- Both use the same four principles (Understanding → Thinking → Choosing → Optimizing)
- The difference lies primarily in training data (quantity and quality) and optimization (How much RLHF budget was invested?)
- The key insight: A small local model + perfectly curated RAG can be more precise than GPT-4 without context on your data
Practical implication:
If you need data sovereignty and have domain-specific tasks, Llama-2 (13B) + RAG is often better than GPT-4 without your knowledge base.
Example 2: Prompt Engineering – Why Does “Think Step by Step” Work So Well?
You’ve noticed that “Think step by step” or “Explain your reasoning” massively improves answer quality? What you now understand:
- Decoding favors probable continuations
- “Step by step” triggers structured reasoning patterns from training (chain-of-thought)
- This is no trick – it is deliberate use of the probability distribution: you steer the model into a region of the vector space where careful analyses are more likely
Practical implication:
Your prompts are not magic – they are probability steering. The better you understand what was learned during training (Step 4: Optimizing), the more precisely you can prompt.
Example 3: Reducing Hallucinations – Three Technical Levers
Your system sometimes invents facts. You want to minimize that? What you now understand: Lever 1 – Temperature (Decoding):
- Niedrige Temperature (z.B. 0.2) = konservativere Token-Wahl
- The model stays closer to highly probable continuations
- Use case: For factual tasks such as data extraction
Lever 2 – RAG (Context): - Provide the model with real sources in the prompt
- This shifts the probability distribution away from “I’m just guessing” toward “I’m paraphrasing the source”
- Use case: For knowledge-intensive tasks (support, research)
Lever 3 – System Prompts (Optimization): - “Answer only based on the provided sources. If uncertain, say: I don’t know.”
- Uses RLHF calibration: The model was trained to follow instructions
- Use case: In combination with RAG for maximum reliability
Practical implication:
You don’t need a more perfect model – you need the right combination of decoding, context, and instruction.
A Clear Decision: What Does This Mean for Today’s Systems?
The democratization of this technology means that today you no longer need billion-dollar infrastructure to build your own, secure AI environments. LLMs are not black-box magic, but precise functional chains with traceable mechanisms:
- Verstehen macht Text berechenbar (Embeddings)
- Thinking computes relationships (Transformer)
- Choosing produces concrete outputs (Decoding)
- Optimizing makes outputs useful (Instruction Tuning)
- RAG makes the system reliable and up-to-date (external knowledge base)
Anyone building a future-proof, AI-capable automation environment today should start here: with the deliberate combination of model, context, decoding, and evaluation.
With RAG, you can maintain data sovereignty while using state-of-the-art automation. Open-source models run locally without sending your data to the cloud.
Quality doesn’t just come from the model – it comes from system design.
Not spectacular. But very effective.
The path from rigid rules to probabilistic wonders was not a sudden flash of inspiration, but a fascinating technical lineage. Those who understand it can not only comprehend today’s AI revolution — they can harness it for their own business.